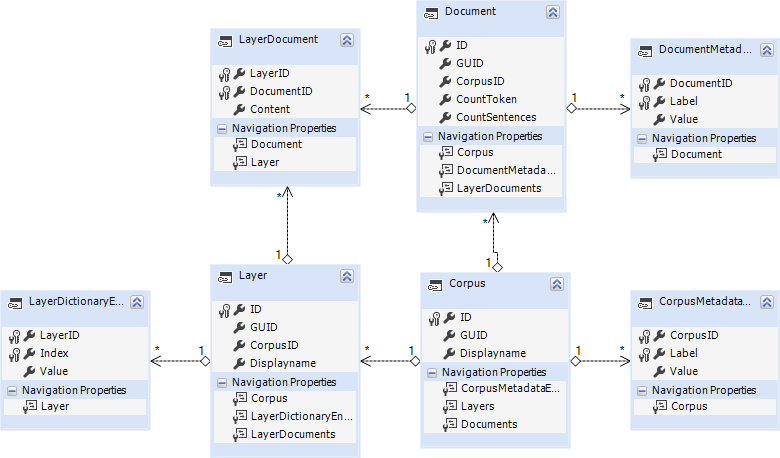
2017-11-16 | CorpusExplorer
An dieser Stelle zuerst ein großes Dankeschön für den Projekt-Rabatt von devart für LinqConnect. Im Rahmen des CorpusExplorer-Projekts habe ich viele ORM-Mapper getestet, auch das neue Entity-Framework (Core). Was aber Funktionalität und Flexibilität anbelangt, ist...
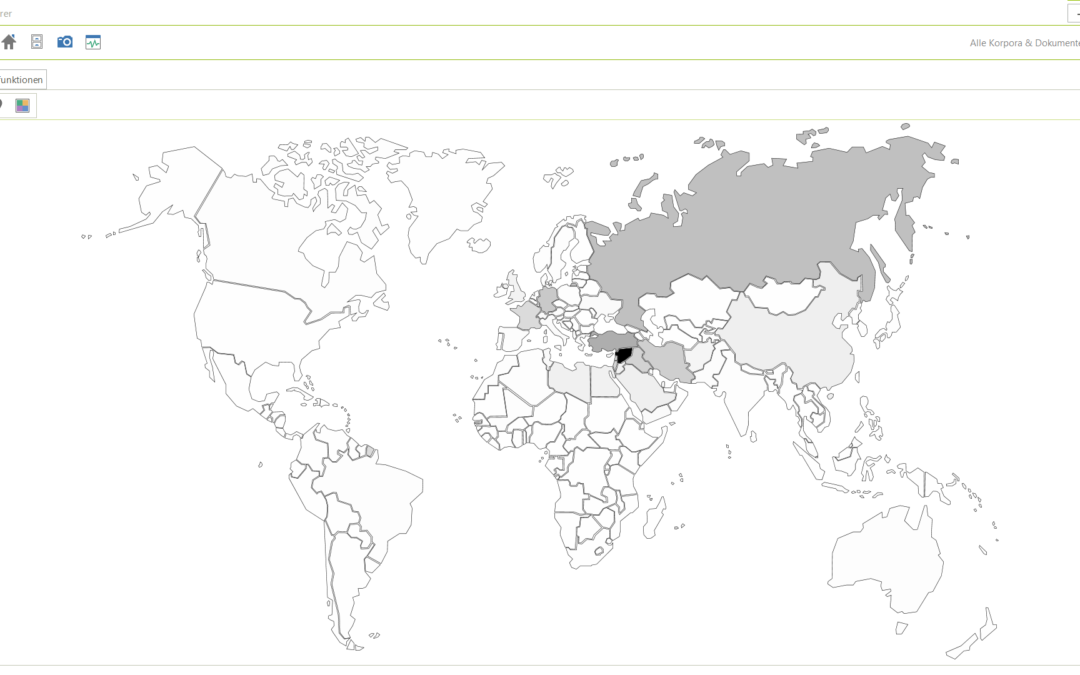
2017-11-14 | CorpusExplorer
Lange habe ich nach einer Lösung gesucht, wie man Karten einfach und effizient im CorpusExplorer integrieren kann. Sowohl kommerzielle als auch OpenSource Lösungen wurden geprüft – von klassischen WinForm- und WPF-Lösungen bis hin zu HTML5/JS. Zwei Dinge störten...
2017-11-13 | CorpusExplorer
So langsam gewöhnt sich der CorpusExplorer an einen dreimonatigen Update-Zyklus. Über einige ausgewählte Funktionen wird es in den kommenden Tagen noch zusätzliche Blog-Beiträge geben. Neue Funktionen: Unterstützung von anderen Encodings/Codepages als UTF-8. Dies kann...