2017-11-14 | CorpusExplorer
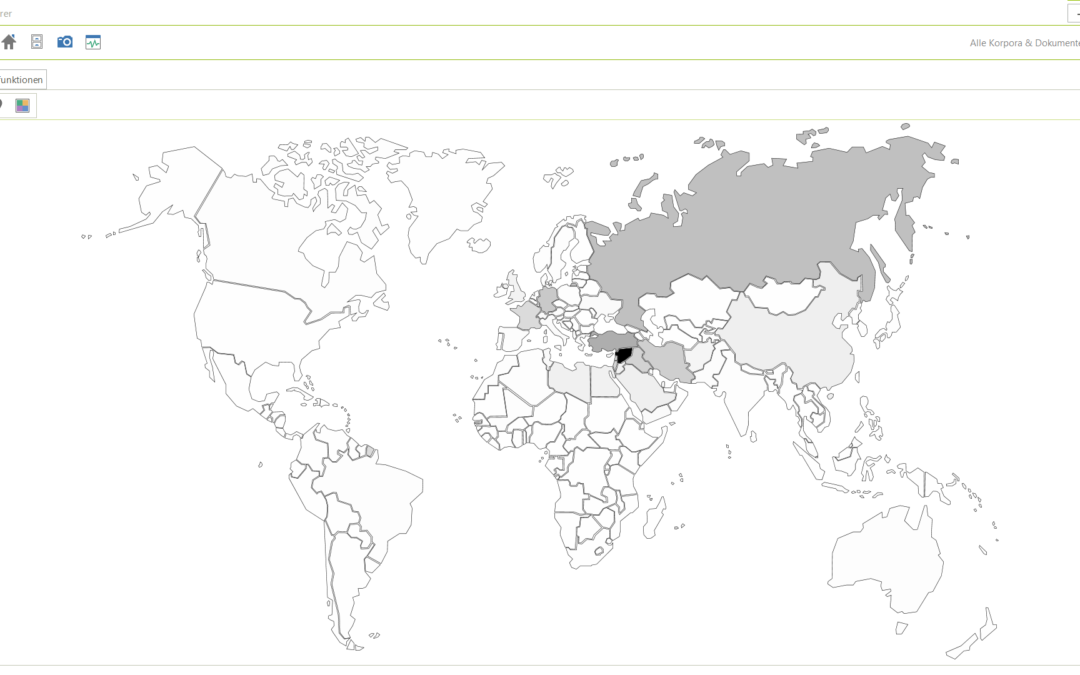
Lange habe ich nach einer Lösung gesucht, wie man Karten einfach und effizient im CorpusExplorer integrieren kann. Sowohl kommerzielle als auch OpenSource Lösungen wurden geprüft – von klassischen WinForm- und WPF-Lösungen bis hin zu HTML5/JS. Zwei Dinge störten...
2016-07-25 | CorpusExplorer
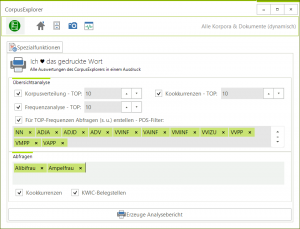
Neues Update – Neue Funktion – Der „PaperLinguist“ ist jetzt verfügbar (Spezialanalysen). Dadurch wird es möglich, die wichtigsten Analysen in einem Rutsch auszudrucken bzw. als PDF, Word, Excel oder CSV zu exportieren. Aber vorsicht, bei...

2014-07-19 | CorpusExplorer
Effizienz und Chaos passen für viele Menschen nicht zusammen, für Computer manchmal schon. Der Grund, Ordnung enthält immer Redundanzen (z. B. Dopplungen). Man kann sich diese Dopplungen zunutze machen und meistens helfen Sie auch – z. B. wenn ich meinen...

2014-06-25 | CorpusExplorer
Gerade teste ich ob man via D3.js [http://d3js.org] brauchbare Textvisualisierungen erzeugen kann … und ich muss sagen, ich bin absolut begeistert. Zu sehen ist eine Auswertung von Dokument-Metadaten – (zufälliges...
2013-04-24 | CorpusExplorer, CorpusExplorer - Hilfe
Wie sind die Dokumente im Korpus verteilt, welchen Anteil hat der Autor X oder der Verlag Y am Gesamtkorpus? – Diese Frage schnell zu beantworten ist Aufgabe dieses Moduls. Kombinieren Sie dieses Modul mit der Suche so haben sie ein sehr mächtiges Werkzeug zur...