
2014-07-19 | CorpusExplorer
Effizienz und Chaos passen für viele Menschen nicht zusammen, für Computer manchmal schon. Der Grund, Ordnung enthält immer Redundanzen (z. B. Dopplungen). Man kann sich diese Dopplungen zunutze machen und meistens helfen Sie auch – z. B. wenn ich meinen...
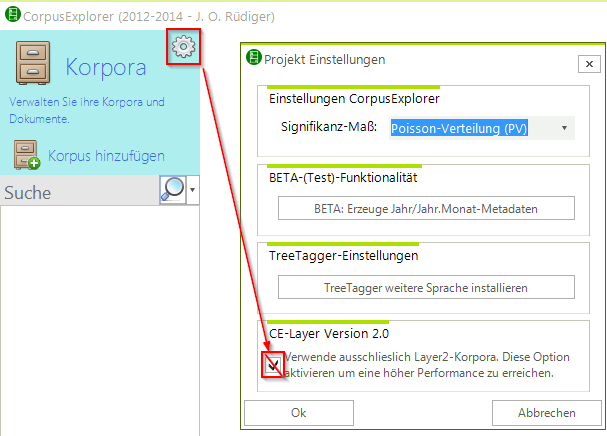
2014-07-08 | CorpusExplorer
Die Juli Version des CorpusExplorers enthält folgende Änderungen / Korrekturen Modulbezeichnungen wurden korrigiert. Unter bestimmten Umständen konnte es vorkommen, dass der Korpusname nicht korrekt angezeigt wurde. Unter bestimmten Umständen konnte es vorkommen, dass...