An dieser Stelle zuerst ein großes Dankeschön für den Projekt-Rabatt von devart für LinqConnect. Im Rahmen des CorpusExplorer-Projekts habe ich viele ORM-Mapper getestet, auch das neue Entity-Framework (Core). Was aber Funktionalität und Flexibilität anbelangt, ist LinqConnect gegenwärtig das beste Produkt am Markt. In diesem Artikel wird ausgeführt, wie mittels LinqConnect eine CorpusExplorer-Schnittstelle für MySQL und SQLite entwickelt wurde. Natürlich kann man auf die Datenbanken auch nativ oder mit einem anderen ORM-Mapper zugreifen, aus Sicht eines C#-Entwicklers gibt es aber einige Vorteile (die im Folgenden auch behandelt werden).
Das Schema kann direkt in Visual Studio 2017 mittels visueller Tools erstellt werden (der dafür nötige Editor „EntityDeveloper“ ist Teil von LinqConnect).
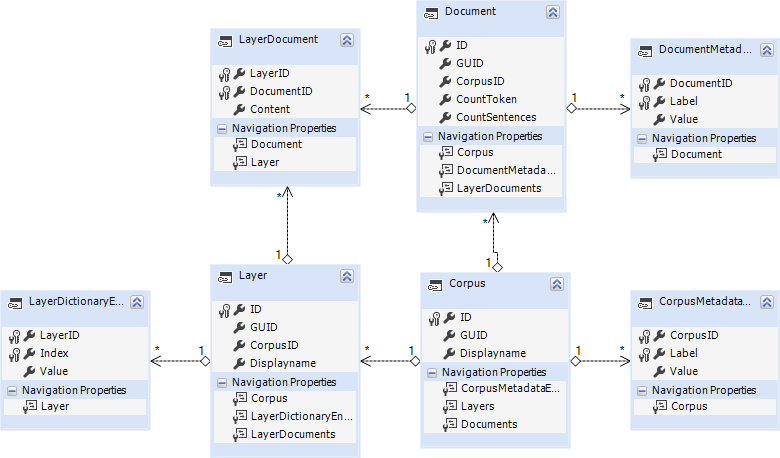 Folgende Tabellen/Klassen wurden definiert:
Folgende Tabellen/Klassen wurden definiert:
- Corpus
- ID – Primärschlüssel – Integer / Autoincrement
- GUID – siehe Besonderheiten: GUID
- Displayname – Der Anzeigename für das Korpus.
- CorpusMetadataEntry (Speichert alle Metadaten die für das Gesamtkorpus Gültigkeit haben)
- CorpusID und Label sind die Primärschlüssel. Label kann z. B. Erstelldatum, Korpussprache, usw. sein.
- Value – siehe Besonderheiten: Metadaten – Value
- Layer
- ID – Primärschlüssel – Integer / Autoincrement
- GUID – siehe Besonderheiten: GUID
- CorpusID – Ordnet den Layer einem Korpus zu
- Displayname – Der Name/Bezeichner des Layers – z. B. POS, Lemma, Wort, usw.
- LayerDictionaryEntry
- LayerID und Index sind die Primärschlüssel – Index wird durch den CorpusExplorer im Annotations-/Tokenisierungsprozess automatisch erzeugt
- Value – der eigentliche Wert bzw. das eigentliche Wort.
- Document
- ID – Primärschlüssel – uLong (64-Bit Ganzzahl (unsigned)) / Autoincrement
- GUID – siehe Besonderheiten: GUID
- CorpusID – Ordnet das Dokument einem Korpus zu
- CountToken / CountSentences – Anzahl Token / Sätze. Dieses Daten werden beim Eintragen in die Datenbank berechnet. Der CorpusExplorer fragt z. B. bei Schnappschusswechsel die Token/Satzanzahl aller Dokumente ab. Um unnötige Wartezeiten/Datenbanklasten zu vermeiden, wird diese Eigenschaft vorberechnet.
- DocumentMetadataEntry (Speichert Metadaten, die nur für ein bestimmtes Dokument gültig sind)
- DocumentID und Label sind die Primärschlüssel – z. B. Autor, Verlag, Datum
- Value – siehe Besonderheiten: Metadata – Value
- LayerDocument
- LayerID und DocumentID sind die Primärschlüssel
- Content – Jedes Dokument kann mehrere Layer haben und jeder Layer erstreckt sich über mehrere Dokumente. Das LayerDocument ist die Schnittstelle zwischen Dokument und Layer. Im Content wird das zweidimensionale 32-Bit Ganzzahl-Array als eindimensionales Byte-Array serialisiert. Die erste Dimension ist die der Sätze, die zweite Dimension ist die Wort-Positionen innerhalb des Satzes (Zählung beginnt wie üblich jeweils bei 0). In der deserialisierten Form wäre doc[0][1] – Der erste Satz [0] und das zweite Wort [1]. Wenn Sie nicht den CorpusExplorer nutzen möchten, um die Daten auszulesen, dann können Sie die Daten wie folgt selbst deserialisieren:
Lesen Sie die ersten vier Byte ein und konvertieren Sie diese in einen vorzeichenbehafteten 32-Bit Integer. Sie erhalten die Anzahl an zu erwartenden Sätzen. Lesen Sie dann die nächsten vier Byte ein und konvertieren Sie erneut, Sie erhalten die zu erwartende Anzahl an Worten/Token im ersten Satz. Lesen Sie die entsprechende Byte-Sequenz aus (4 * Anzahl an erwarteten Worten/Token) und konvertieren Sie diese in ein 32-Bit Ganzzahl-Array. So fahren Sie fort, bis alle Daten gelesen wurden. Das so erhaltene zweidimensionale Array können Sie wie bereits oben beschrieben auswerten. Um den Text zu erhalten, greifen Sie auf die LayerDictionaryEntries des jeweiligen Layers zurück.
Besonderheiten:
- GUID – Im CorpusExplorer ist der Primärschlüssel immer vom Datentyp GUID. Leider unterstützen nicht alle Datenbanken GUID (z. B. weil GUID nicht als Datentyp implementiert ist oder weil GUID keine Primärschlüssel sein darf). Daher wurden einfache Integer IDs vergeben.
- Metadaten – Value: Der CorpusExplorer serialisiert Metadaten als KeyValue-Store. Der Key ist immer vom Typ String, der Value vom Typ Object. Damit lassen sich beliebige Datentypen als Value speichern. Der CorpusExplorer kümmert sich dabei um De-/Serialisierung und die Typsicherheit. Keine dieser Funktionalitäten wird von SQL-Datenbanken unterstützt (mit NoSQL-Datenbanken wie ElasticSearch ist dies möglich). Daher werden die Daten/Typen/Objekte, die in Value gespeichert werden, vorher durch den CorpusExplorer als byte-Array serialisiert. Vor jedes Byte-Array wird ein einzelnes Byte geschrieben, dass angibt, wie die Daten zu deserialierien sind. Folgende Werte sind für dieses erste Byte gültig: 10 – String, 20 – 32-Bit Ganzzahl, 21 – 32-Bit Ganzzahl (unsigned), 30 – Fließkommazahl doppelte Genauigkeit, 40 – DateTime serialisiert als 64-Bit Tick, 50 – 64-Bit Ganzzahl, 51 – 64-Bit Ganzzahl (unsigned), 250 – Alle anderen Typen (der CorpusExplorer nutzt den .NET-BinaryFormatter zur Serialisierung).
Vorteile von LinqConnect:
- LinqConnect übernimmt das Caching, optimiert Abfragen (z. B. Zusammenfassen von INSERT) und stellt einige Sonderfunktionen bereit (Löschen von nicht mehr benötigten DB-Einträgen).
- LINQ ist ein Konzept aus dem .NET-Ökosystem und bedeutet Language INtegrated Query. In den meisten Programmiersprachen ist es üblich, eine SQL-Abfrage aus verschiedenen Werten und Strings (Zeichenketten) zusammen zu setzen – siehe Bsp. $query:
$conn = new mysqli($servername, $username, $password, $dbname); $query = "SELECT " . $columns . " FROM " . $table_name . " WHERE " . $condition; $result = $conn->query($sql);
Dabei kann (1) einige schief gehen und (2) ein Fehler fällt erst zur Laufzeit auf. LINQ löst dies, indem die Abfrage Teil der eigentlichen Programmiersprache ist (bzw. in diese integriert wird). Daher sind Vertipper nicht möglich, auch SQL-Injections werden vermieden – Fehler sind bereits für den Compiler ersichtlich. Eine Abfrage in LINQ sähe wie folgt aus:
var conn = new DataContext(); var result = from x in table select columns;
- Ein weiterer Vorteil ist, dass LINQ alle Daten als Objekte behandelt. In den meisten Programmiersprachen erhalten Sie nach der erfolgreichen Abfrage eine Liste/Tabelle, die Sie zuvor selbst deserialisieren/durchlaufen müssen. Im Vergleich hierzu LINQ:
var result = from x in context.DocumentMetadataEntry where x.Label == "Autor" && x.Value == ValueSerializer.Serialize("JOR") select x.Document;Es werden alle DocumentMetadataEntries abgefragt, die ein Label namens „Autor“ haben und dessen Wert/Value „JOR“ ist. Zurückgegeben wird eine Liste von Objekten des Typs Document. Der gesamte Prozess geschieht im Hintergrund.
- LinqConnect stellt für viele verschiedene Datenbanken eine einheitliche Schnittstelle bereit. Den Quellcode von SQLite auf MySQL umzustellen hat gerade einmal eine Stunden Arbeit beansprucht.
Anmerkungen:
- Primär ist die Schnittstelle für Korpora konzipiert, bei denen die für den CorpusExplorer typische In-Memory Analyse nicht mehr möglich ist (zu groß um im Arbeitsspeicher abgelegt zu werden). Eine vollständig datenbankkonforme Serialisierung wurde/wird nicht angestrebt. Vielmehr wurde auf die Performance geachtet die sich aus Lese-/Schreibvorgängen zwischen CorpusExplorer und Datenbank ergeben.
- Sie können in eine Datenbank beliebig viele Korpora schreiben. Trotzdem wird empfohlen pro Korpus eine separate Datenbank zu nutzen (dies erleichtert die Verwaltung).
- Es ist geplant, eine Schnittstelle für Analyseergebnisse zu schaffen – d. h.: Analysen die der CorpusExplorer durchführt, können direkt in eine SQL-Datenbank geschrieben werden. Andere Programme können diese Daten dann weiter analysieren, nutzen oder visualisieren.
- Einschränkungen: Diese können je nach Datenbank schwanken (falls Datentypen unterschiedlich definiert sind). Prinzipiell gilt, ca. 2 Mrd. Korpora mit jeweils ca. 2 Mrd. Layer, mit jeweils ca. 2 Mrd. Layer-Werten und max. 18’446’744’073’709’551’615 Dokumente (pro Dokument max. ca. 2 Mrd. Sätze mit jeweils ca. 2 Mrd. Token). – Dies sollte also auf recht lange Sicht ausreichende Kapazitäten schaffen.