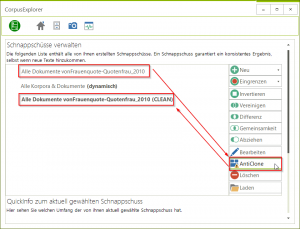
CloneDetection
Egal ob Tweets oder Zeitungsartikel – viele Korpora enthalten Textsorten, die per se zu Duplikaten neigen. Der CorpusExplorer kann jetzt diese automatisch entfernen. Laden Sie ein Korpus. Rufen Sie die Schnappschuss-Detailansicht auf und klicken Sie auf...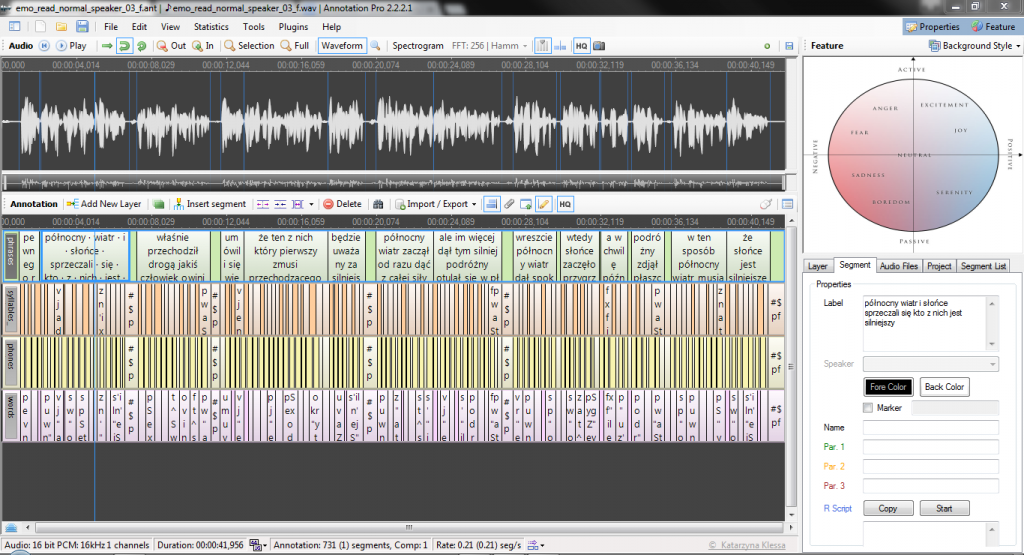
Kooperation: AnnotationPro & CorpusExplorer – Teil 1/2
Auf die Frage einer Projektgruppe: Ob denn in naher Zukunft vorgesehen sei, dass der CorpusExplorer auch Transkription von Audio-/Video-Daten unterstützt – war meine Antwort: „Dazu fehlt leider die Zeit und das Budget“. Aber die neue Version (2.0...Geschützt: Korpus: Jugendsprache (Pressetexte 1990-2014)
Passwortgeschützt
Um dieses geschützten Beitrag anzusehen, unten das Passwort eingeben.:
Geschützt: Korpus: Tebartz van Elst
Passwortgeschützt
Um dieses geschützten Beitrag anzusehen, unten das Passwort eingeben.: