Korpora
Alle hier aufgeführten Korpora (insgesamt über 2 Mrd. Token) sind frei verfügbar und können kostenfrei zu nicht kommerziellen Zwecken genutzt werden (siehe „Allgemein“). Voraussetzung für die Nutzung ist ein bereits installierter CorpusExplorer (kostenfrei / OpenSource). Dieser erlaubt nicht nur die Analyse und Visualisierung der Korpusdaten, sondern sorgt auch dafür, dass Sie immer mit aktuellstem Korpusmaterial arbeiten (Korpus-Autoupdate).
Installationsanleitung:
- Stellen Sie sicher, dass der CorpusExplorer geschlossen/beendet ist, bevor Sie weiter fortfahren.
- Klicken Sie auf den Download-Button der gewünschten Korpora, um den Download zu starten. Hinweis: Seien Sie bitte nicht irritiert, die Datei ist ca. 1-4 KB groß. Speichern Sie die Datei unter:
„Meine Dokumente“ > „CorpusExplorer“ > „Meine Erweiterungen“ - Wenn Sie das nächste Mal den CorpusExplorer starten, werden die Korpora automatisch installiert und auch zukünftig aktuell gehalten. Die Korpora sind dann unter „Korpora“ > „Existierendes Korpus laden“ verfügbar.
Korpora konvertieren:
Korpora auf dieser Seite werden im Format CEC6 ausgeliefert. Ein Export in andere Korpusformate (DTABf, Weblicht, XML, JSON, etc.) ist mittels CorpusExplorer möglich. Für die Konvertierung gibt es vier Optionen (Optionen 1-3 setzen einen installierten CorpusExplorer voraus [kostenlose Installation] – Option 4: Ist webbasiert):
-
- ENTWEDER: Sie laden ein Korpus in den CorpusExplorer und exportieren es via ‚Schnappschuss Übersicht‘ > ‚Exportieren‘.
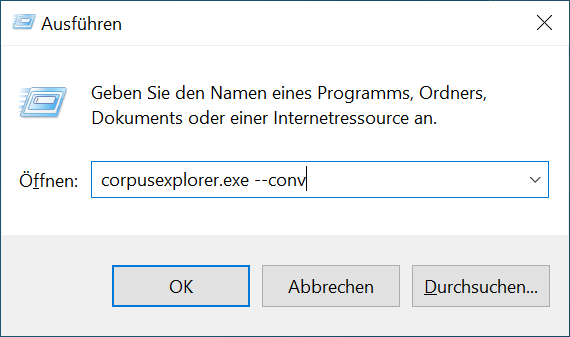
- ODER: Sie drücken gleichzeitig die Tasten WINDOWS und R. Der Dialog „Ausführen“ erscheint. Geben Sie hier folgendes ein: CorpusExplorer –conv
Bestätigen Sie die Eingabe mit OK und folgen Sie den Anweisungen.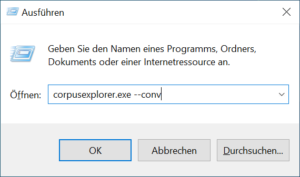
- ODER: Die Konvertierung ist auch ohne GUI möglich, mittels CMD-Shell und der CorpusExplorer-Console (cec.exe):
cec.exe import#Cec6#C:input.cec6 convert Xml#C:output.xml
- ODER: Sie nutzen den Web-Konverter:
https://convert.corpusexplorer.de/
Bitte nur für kleine Korpora (bis max. 50 MB) verwenden. - ODER: Für große Korpusmengen (viele und große Korpusdateien) nutzen Sie gerne den CEC6-Converter (funktioniert unter Windows, Linux und MacOS): http://hdl.handle.net/11372/LRT-5705
Lizenz:
Falls keine andere Lizenz genannt wird, steht das Korpusmaterial auf dieser Seite unter der CC BY-NC 4.0 Lizenz zur kostenlosen/freien Verfügung.
Rechtliches / Datenschutz:
Die hier bereitgestellten Korpora sind entweder gemeinfrei (z. B. Gesetzestexte, Plenarprotokolle, 70 Jahre nach Tod des Urhebers §64 UrhG), basieren auf bereits existierenden gemeinfreien Korpora (siehe entsprechende Verweise – in Rücksprache mit den Originalautor*innen). Wenn Sie Beanstandungen irgendwelcher Art gegen ein Korpus oder Korpusteile haben (z. B. bestimmte Dokumente innerhalb des Korpus), dann melden Sie bitte das Korpus – bzw. Korpus + GUID (für beanstandete Dokumente). Ich werde das Material prüfen und innerhalb weniger Werktage entfernen.
Statistik:
Für die Korpora sind separate Statistiken ausgewiesen. Hier eine Statistik zum Gesamtmaterial:
Dokumente: 10’643’180 – Token: 6’232’033’007
Hinweise:
- Große Korpora (größer 2GB) setzen eine schnelle und stabile Internetverbindung für den Download voraus, sowie einen leistungsstarken PC (min. Quad-Core CPU / 16 GB RAM).
- Wenn Sie über eigenes Korpusmaterial verfügen, dass Sie publizieren möchten, dann (A) überprüfen Sie bitte zuerst, ob es sich lohnt, dieses in einem öffentlichen Langzeit-Repository zu publizieren. Ich berate Sie auch gerne. (B) Zusätzlich/alternativ biete ich auch an, das Material hier zu publizieren. Nutzer*innen des CorpusExplorers können so das Korpus mit wenigen Klicks aus der Anwendung heraus nutzen (siehe nächster Punkt).
- Korpora, die für den CorpusExplorer publiziert werden, verfügen über eine Auto-Update-Funktion. Wie oben erwähnt, biete ich an, das Hosting zu übernehmen. Sie können Korpora aber auch ganz einfach selbst hosten (z. B. hausinterne Verteilung -oder- Verteilung an Seminargruppe). Dazu sind nur drei Schritte nötig. [Anleitung hier]
Verfügbare Korpora (Korpus-Addons):
Radiopredigtenkorpus:
1933–1939; 1950–1960; 2010–2024 !NEU!
Das Korpus deutscher Radiopredigten umfasst über 29.000 digitalisierte und annotierte Manuskripte moderner Radiopredigten (2010–2024) sowie 267 historische Texte aus der Zeit des Nationalsozialismus (1933–1939) und 96 aus dem DDR-Rundfunk (1950–1960).
Die modernen Predigten sind Endfassungen gesendeter Manuskripte aus RBB, HR, WDR, SWR, BR und SR und decken das gesamte Bundesgebiet ab. Die historischen Bestände stammen aus kirchlichen Archiven bzw. zeitgenössischen Publikationen und wurden über die Reichssender Köln und München sowie den DDR-Rundfunk verbreitet. Das Korpus vereint damit drei exemplarische Zeiträume der Radiopredigtgeschichte (1924–2024) unter unterschiedlichen politischen Systemen, einschließlich Phasen staatlicher Zensur.
Das Korpus ist im Rahmen des DFG-Projekts „Denn Deine Sprache verrät Dich…“ – Sprache und Konfession 500 Jahre nach der Reformation (Kurz: Sprache und Konfession im Radio) von Dr. Anna-Maria Balbach entstanden, das von 2019–2025 unter der Projektnummer 410899976 gefördert wurde. Weitere Informationen zum Korpus unter:
Anna-Maria Balbach and Jan Oliver Rüdiger, 2025, [RPK] – Radiopredigtenkorpus (german radio sermons): 1933-1939; 1950-1960; 2010-2024, LINDAT/CLARIAH-CZ digital library at the Institute of Formal and Applied Linguistics (ÚFAL), http://hdl.handle.net/11372/LRT-5975.
113 MB – 29,5 Tsd. Dokumente
20,07 Mio. Token – 1,60 Mio. Sätze
Layer: Wort, POS, Lemma
OpenLegalData
OpenLegalData ist eine freie und offene Plattform, die juristische Dokumente und Informationen für die Öffentlichkeit zugänglich macht. Das Ziel dieser Plattform ist es, die Transparenz der Rechtsprechung mithilfe offener Daten zu verbessern und Menschen ohne juristische Ausbildung dabei zu unterstützen, das Justizsystem zu verstehen. Das Projekt ist den Open-Data-Prinzipien und der Bewegung für freien Zugang zum Recht verpflichtet.
Für die Erstellung dieses Korpus wurde der DUMP von OpenLegalData mit Stand: 2022-10-18 verwendet. Die Daten wurden bereinigt, maschinell annotiert (TreeTagger: POS & Lemma) und anhand der Metadaten gruppiert (Gerichtsbarkeit – BundeslandID – ggf. Teilgröße – Bsp.: Verwaltungsgerichtsbarkeit_11_05.cec6.gz – Gerichtsbarkeit: Verwaltungsgerichtsbarkeit, BundeslandID = 11 – Teilkorpus = 05). Teilkorpora werden zu je 50 MB zufällig gesplittet.
2,8 GB – 169216 Dokumente
39,6 Mio. Sätze – 610,7 Mio. Token
Layer: Wort, POS, Lemma
Wahlprogramme zur Bundestagswahl 2021
Die Wahlprogramme der zur Zeit (19. Legislaturperiode) im Bundestag vertretenen Parteien wurden aus dem verfügbaren PDF-Format zunächst in txt umgewandelt und um Kopfzeilen, Seitenzahlen sowie um Marginalia bereinigt. Auch Inhaltsverzeichnisse und Register wurden entfernt.
[OpenAccess] – Bei Rückfragen wenden Sie sich bitte an: simon.meier-vieracker@tu-dresden.de
Referenzkorpus Altdeutsch (750-1050)
Das “Referenzkorpus Altdeutsch” (kurz: ReA) enthält eine auf Vollständigkeit bedachte annotierte Sammlung der ältesten deutschen Sprachdenkmäler vom Beginn der kontinuierlichen schriftlichen Überlieferung um 750 bis etwa 1050. Das Korpus steht unter der CC-BY-NC-SA Lizenz. Weitere Infos zum Korpus auf der Projektwebseite.
Bitte zitieren Sie das Korpus in Ihren Arbeiten wie folgt: Lars Erik Zeige, Gohar Schnelle, Martin Klotz, Karin Donhauser, Jost Gippert, Rosemarie Lühr. 2022. Deutsch Diachron Digital. Referenzkorpus Altdeutsch. Humboldt-Universität zu Berlin. Homepage: http://www.deutschdiachrondigital.de/rea/. DOI https://doi.org/10.34644/laudatio-dev-MiXVDnMB7CArCQ9CABmW.
Hinweis: Beim Korpusimport wird eine Fehlermeldung angezeigt. Grund: Der CorpusExplorer ist übervorsichtig konfiguriert und schlägt bei älteren Sprachstufen gerne mal falsch an. Sie können den Fehler getrost mit „Abbrechen“ ignorieren.
11,5 MB – 1943 Dokumente – 743,8 Tsd. Token – 16 Layer z. B.: Wort, Norm, POS, Lemma, INFL, INFL-CLASS
Referenzkorpus Frühneuhochdeutsch (1350–1650)
Das “Referenzkorpus Frühneuhochdeutsch” (kurz: ReF) ist ein Korpus diplomatisch transkribierter und annotierter Texte des Frühneuhochdeutschen (1350–1650). Es wurde an den drei Projektstandorten Bochum, Halle und Potsdam erstellt und enthält morphologische (Bochum, Halle) und syntaktische Annotationen (Potsdam). Das Korpus steht unter der „CC BY-SA 4.0 DEED“-Lizenz. Weitere Informationen finden Sie auf der Projektwebseite.
Bitte zitieren Sie das Korpus in Ihren Arbeiten wie folgt: Wegera, Klaus-Peter; Solms, Hans-Joachim; Demske, Ulrike; Dipper, Stefanie (2021). Referenzkorpus Frühneuhochdeutsch (1350–1650), Version 1.0, https://www.linguistics.ruhr-uni-bochum.de/ref/. ISLRN 918-968-828-554-7.
Hinweis: Beim Korpusimport wird eine Fehlermeldung angezeigt. Grund: Der CorpusExplorer ist übervorsichtig konfiguriert und schlägt bei älteren Sprachstufen gerne mal falsch an. Sie können den Fehler getrost mit „Abbrechen“ ignorieren.
Anmerkung: Die Originaldateien liegen in TiGER-XML und CORA-XML vor. Die Daten wurden mittels CorpusExplorer vereinheitlicht.
12,1 MB – 143 Dokumente – 2,56 Mio. Token – 6 Layer: INFL, INFL-Class, Lemma, Norm, POS und Wort
One Million Posts Corpus
Das „One Millio Posts Corpus“ umfasst Zeitungsartikel der österreichischen Zeitung „der Standard“ – inkl. der Online-Kommentare der Leser*innen. Das Korpus wurde im Original teilweise manuell annotiert – so finden sich z. B. zu einigen Leserkommentaren Einschätzungen zu Positiv/Negativ-Wertung oder welcher Art/Domäne ein Kommentar zuzuordnen ist. Für diese Version wurde das Korpus entsprechend korpuslinguistisch aufbereitet. Link zur Original-Ressource. 1,0 GB – 973 Tsd. Dokumente
3,94 Mio. Sätze – 41,71 Mio. Token
Layer: Wort, Lemma, POS
HetWiK – Heterogene Widerstandskulturen
Das repräsentative volltextdigitalisierte HetWiK-Korpus besteht aus 129 manuell annotierten Texten des deutschen Widerstands zwischen 1933 und 1945. Dazu gehören sowohl bekannte als auch relativ unbekannte Dokumente, öffentliche Schriften, wie Flugblätter oder Memoranden, als auch private Texte, z.B. Briefe, Tagebuch- oder Gefängniseinträge und Biographien. Damit repräsentiert das Korpus die verschiedenen Gruppen sowie die Heterogenität des verbalen Widerstands und ermöglicht die Untersuchung des Widerstands im Zusammenhang mit dem Sprachgebrauch. Das HetWiK-Korpus steht unter der „CC BY-NC-SA 4.0 DEED“-Lizenz. Ein detailliertes Register der einzelnen Texte und weitere Informationen zum Tagset sind auf der Projekt-Homepage zu finden.
Wenn Sie das Korpus verwenden, dann zitieren Sie es bitte wie folgt: Schuster, Britt-Marie; Markewitz, Friedrich; Wilk, Nicole M.; Schröder, Sarah and Rüdiger, Jan Oliver, 2021, HetWiK: Heterogene Widerstandskulturen, LINDAT/CLARIAH-CZ digital library at the Institute of Formal and Applied Linguistics (ÚFAL), Faculty of Mathematics and Physics, Charles University, http://hdl.handle.net/11372/LRT-4623.
1,1 MB – 129 Dokumente – 302,8 Tsd. Token – Layer siehe Dokumentation (in der ZIP-Datei).
W2C – Web to Corpus
Die hier zur Verfügung gestellten Korpusdaten umfassen alle deutschen Texte aus dem: Majliš, Martin, 2011, W2C – Web to Corpus – Corpora, LINDAT/CLARIN digital library at the Institute of Formal and Applied Linguistics (ÚFAL), Faculty of Mathematics and Physics, Charles University, http://hdl.handle.net/11858/00-097C-0000-0022-6133-9. Die Texte wurden tokenisiert und annotiert.
1,0 GB – 1,9 Mio. Dokumente
9,18 Mio. Sätze – 116,99 Mio. Token
Layer: Wort, Lemma, POS
Wikipedia
Das Wikipedia-Korpus enthält alle Seiten der deutschsprachigen Wikipedia (Stand Juni 2019). Seiten mit Weiterleitungen oder Seiten, die von der Qualitätskontrolle geflaggt wurden, wurden entfernt. Der Rohtext wurde bereinigt (Tabellen entfernt, Referenzen entfernt, usw.), tokenisiert und mittels TreeTagger annotiert.
11,7 GB – 1,27 Mio. Dokumente
64,44 Mio. Sätze – 750,04 Mio. Token
Layer: Wort, Lemma und POS
KAMOKO
KAssler MOrgenstern KOrpus – kurz KAMOKO ist eine strukturierte und kommentierte Sammlung von Textbeispielen zur französischen Sprache und Linguistik, die nahezu alle zentralen Strukturen der französischen Sprache aus linguistischer Sicht behandelt.
Mithilfe des KAMOKO-Korpus können Studierende die Funktionen sprachlicher Formen in thematisch gegliederten Lehreinheiten für sich erschließen. Jede Einheit stellt ein sprachliches Phänomen (wie z. B. Tempus und Aspekt) anhand von Textbeispielen dar, die aufeinander aufbauen und zunehmend komplexere Verwendungen einer Form darstellen und erklären.
Zentral ist dabei das Muster von Original und Variante, bei dem der Originaltext in unterschiedlicher Weise verändert wird. Die so entstandenen Varianten und neuen Lesarten illustrieren dann das funktionale Profil einer sprachlichen Form und deren Wirken in verschiedenen Kontexten.
Auf diese Weise vermittelt KAMOKO in korpusbasierter Anschaulichkeit komplexe linguistische Inhalte.
39,3 MB – 64122 Dokumente
0,185 Mio. Sätze – 2,70 Mio. Token
Layer: Wort, POS, Lemma, Original, Kommentar Muttersprachler
DTA-Korpus
Das Korpus basiert auf der TCF-Version (Stand: 1. September 2017) und umfasst derzeit 3242 Texte (DTA-Kernkorpus und Ergänzungstexte). Das Korpus wurde mit dem Ziel zusammengestellt, das gesamte Spektrum der deutschen Sprache zu erfassen und somit ein ausgewogenes historisches Referenzkorpus in deutscher Sprache zu schaffen.
Es gibt andere umfangreiche Textsammlungen im Internet wie etwa Google Books, Wikisource oder das Projekt Gutenberg-DE. Das DTA unterscheidet sich von diesen Textsammlungen durch die sorgfältige Auswahl der Texte und Ausgaben, die sehr hohe Erfassungsgenauigkeit, die strukturelle und linguistische Erschließung der Textdaten sowie die Verlässlichkeit der Metadaten. [Weitere Informationen finden Sie hier]
Anmerkung: Bitte beachten Sie: Der Download hat eine Größe von ca. 1,0 GB. Das Korpus-Addon basiert auf den bereinigten & annotierten TCF-Dateien (Stand: September 2017) – [Link zu den Originaldateien]. Importiert wurden die folgenden Layer: Wort, Lemma, POS und Orthografie. Ebenfalls stehen folgende Metadaten zur Verfügung: URL, Sprache, DWDS-Hauptkategorie, DWDS-Unterkategorie, Titel, Autor, Autor (URL), Ausgabe, Verleger, Jahr und Verlagsort.
3,47GB – 4431 Dokumente
9,7 Mio. Sätze – 223,44 Mio. Token
Layer: Wort, POS, Lemma, NER, Orthografie
TextGrid – Digitale Bibliothek
Die „Digitale Bibliothek“ im TextGrid Repository bietet eine umfangreiche Sammlung XML/TEI-erschlossener Texte aus Belletristik und Sachliteratur vom Anfang des Buchdrucks bis zu den ersten Jahrzehnten des 20. Jahrhunderts in digitaler Form. Für die germanistische Literaturwissenschaft ist die Sammlung von besonderem Interesse, da sie nahezu alle wichtigen kanonisierten Texte und zahlreiche weitere literaturhistorisch relevante Texte enthält, deren urheberrechtliche Schutzfrist abgelaufen ist. Ähnliches gilt für die Philosophie und die Kulturwissenschaften insgesamt. Die Texte stammen zum größten Teil aus Studienausgaben und sind daher, ebenso wie die auf der Digitalisierung von Erstdrucken basierenden Texte, zitierfähig. [Weitere Details finden Sie hier]
Dieses Korpus ist eine Abwandlung des Datenbestandes der Digitalen Bibliothek von TextGrid, www.editura.de und wird unter der Creative Commons Lizenz veröffentlicht.
2,19GB – 70847 Dokumente
10,07 Mio. Sätze – 156,85 Mio. Token
Layer: Wort, POS, Lemma
NottDeuYTSch
Das NottDeuYTSch-Korpus (Nottinghamer Korpus Deutscher YouTube-Sprache) enthält über 37 Millionen Token aus ca. 3 Millionen YouTube-Kommentaren von Videos. Die zwischen 2008 und 2018 veröffentlicht wurden und sich an eine junge, deutschsprachige Zielgruppe richten, bzw. von dieser Zielgruppe stammen. Das NottDeuYTSch-Korpus versucht damit eine authentische sprachliche Momentaufnahme junger/jugendlicher Deutschsprachiger abzubilden. Das Korpus wurde proportional nach Videokategorie und Jahr aus einer Datenbank von 112 beliebten deutschsprachigen YouTube-Kanälen in der DACH-Region ausgewählt, um eine optimale Repräsentativität und Ausgewogenheit zu gewährleisten. Außerdem enthält NottDeuYTSch eine beträchtliche Menge an zugehörigen Metadaten für jeden Kommentar, die weitere Längsschnittanalysen ermöglichen.
[OpenAccess] Bei Rückfragen wenden Sie sich bitte an: Louis Cotgrove
2,0 GB – 3,15 Mio. Dokumente
5,9 Mio. Sätze – 37,86 Mio. Token
Layer: Wort, Lemma (tree_tagger), POS (tree_tagger)
CEHugeWebCorpus
Dieses Korpus wurde ursprünglich zum Testen der Performance (Serverinfrastruktur CorpusExplorer – siehe: diskurslinguistik.net / diskursmonitor.de) erstellt. Es umfasst den gefilterten Datenbestand (ursprünglich 8,8 TB) von CommonCrawl (Stand März 2018). Zunächst wurden die URLs anhand ihrer Top-Level-Domain (de, at, ch) gefiltert. Dann wurden die Texte mittels NTextCat klassifiziert und nur eindeutig deutsche Texte wurden ins Korpus übernommen. Die Texte wurden dann mittels TreeTagger annotiert. 2,58 Mio. Dokumente – 232,87 Mio. Sätze – 3,021 Mrd. Token
Layer: Wort, Lemma, POS
Das Korpus steht aufgrund der Größe (komprimiert ca. 50 GB) und des Urheberrechts nur für wissenschaftliche Zwecke (auf Anfrage) zur Verfügung.
Download
Hinweis: Aufgrund der Größe (50GB) wird der Download extern (via CLARIN) bereitgestellt.
Referenzkorpus Mittelhochdeutsch
(1050–1350)
Das “Referenzkorpus Mittelhochdeutsch” (kurz: ReM) ist ein Korpus diplomatisch transkribierter und annotierter Texte des Mittelhochdeutschen (1050-1350) mit einem Umfang von ca. 2 Mio. Wortformen. Es ist aus den Forschungsprojekten “Referenzkorpus Mittelhochdeutsch” und “Mittelhochdeutsche Grammatik”hervorgegangen. Das Korpus steht unter der CC-BY-SA Lizenz. Weitere Informationen zum Korpus auf der Projektwebseite.
Bitte zitieren Sie das Korpus in Ihren Arbeiten wie folgt: Klein, Thomas; Wegera, Klaus-Peter; Dipper, Stefanie; Wich-Reif, Claudia (2016). Referenzkorpus Mittelhochdeutsch (1050–1350), Version 1.0, https://www.linguistics.ruhr-uni-bochum.de/rem/. ISLRN 332-536-136-099-5.
Hinweis: Beim Korpusimport wird eine Fehlermeldung angezeigt. Grund: Der CorpusExplorer ist übervorsichtig konfiguriert und schlägt bei älteren Sprachstufen gerne mal falsch an. Sie können den Fehler getrost mit „Abbrechen“ ignorieren.
71,25 MB – 398 Dokumente – 2,52 Mio. Token – Layer: Wort, Norm, POS, Lemma, INFL, INFL-CLASS
Referenzkorpus Mittelniederdeutsch / Niederrheinisch (1200-1650)
Das ‚Referenzkorpus Mittelniederdeutsch / Niederrheinisch‘, kurz ‚ReN‘, umfasst mittelniederdeutsche und niederrheinische Sprachdenkmäler von 1200 bis 1650 in einer strukturierten Auswahl. Es beinhaltet Handschriften, Drucken und Inschriften und soll einen Einblick in die Sprach- und Textkultur des niederdeutschen und niederrheinischen Raums geben. Die historische Sprachentwicklung soll in ihrer diatopischen und diachronischen Untergliederung anhand des Textsortenspektrums nachgezeichnet werden. Das Korpus steht unter der „CC BY 4.0 LEGAL CODE“-Lizenz. Weitere Informationen entnehmen Sie bitte der Projektwebseite.
Bitte zitieren Sie das Korpus in Ihren Arbeiten wie folgt: ReN-Team. (2021). Reference Corpus Middle Low German/Low Rhenish (1200–1650); Referenzkorpus Mittelniederdeutsch/Niederrheinisch (1200–1650) (Version 1.1) [Data set]. http://doi.org/10.25592/uhhfdm.9195
Hinweis: Beim Korpusimport wird eine Fehlermeldung angezeigt. Grund: Der CorpusExplorer ist übervorsichtig konfiguriert und schlägt bei älteren Sprachstufen gerne mal falsch an. Sie können den Fehler getrost mit „Abbrechen“ ignorieren.
4,5 MB – 66 Dokumente – 655,36 Tsd. Token – 5 Layer: Lemma, Lemma (S), MORPH, POS und Wort
Briefe: Jean Paul
Das von TELOTA (Berlin-Brandenburgische Akademie der Wissenschaften) aufbereitete Korpus steht gemeinfrei (CC-BY-SA 4.0) unter https://www.jeanpaul-edition.de zur Verfügung (herausgegeben von Markus Bernauer, Norbert Miller und Frederike Neuber (2018)). Für korpuslinguistische Zwecke wurde die digital verfügbaren Texte bereinigt, tokenisieriert und mittels TreeTagger annotiert. Besonderes herauszuheben sind die speziellen Metadaten – Ort, Datum, Empfänger, vorheriger/nachfolgender Brief.
30 MB – 5525 Dokumente – 136 Tsd. Sätze – 1,51 Mio. Token
Layer: Wort, Lemma, POS
Download
kleineanfragen.de
Die Seite www.kleineanfragen.de sammelt kleine (und auch große) Anfragen der Landesparlamente und des Bundestages und versucht diese möglichst einfach auffind-, durchsuch- und verlinkbar zu machen. Die Daten auf der Webseite sind tagesaktuell – das hier verfügbare Korpus basiert auf dem Stand: 2018-05-07. Der Rohtext wurde bereinigt und mittels TreeTagger annotiert (Token, Satz, POS, Lemma). Für ein tagesaktuelles Korpus nutzen Sie bitte die Import-Funktion des CorpusExplorers. Dieses Korpus wird in regelmäßigen Abständen (ca. alle 6 Monate) aktualisiert. Der Datensatz steht unter der Open Database License (ODbL) 1.0 frei zur Verfügung.
3,3 GB – 85’021 Dokumente
17,88 Mio. Sätze – 238,59 Mio. Token
Layer: Wort, POS, Lemma
Deutscher Bundestag Drucksachen
Unter https://www.bundestag.de/service/opendata stellt der Deutsche Bundestag alle Drucksache (z. B. Anträge, Gesetzesvorlagen, etc.) OpenAccess in einem sehr rudimentären XML-Format bereit. Die vorhandenen Metadaten wurde extrahiert. Der Rohtext bereinigt und mittels TreeTagger annotiert (Token, Phrasen, Satz, POS, Lemma).
12,85 GB – 131833 Dokumente
44,7 Mio. Sätze – 715,15 Mio. Token
Layer: Wort, POS, Lemma, Phrase
Deutscher Bundestag Plenarprotokolle !UPDATE!
Unter https://www.bundestag.de/service/opendata stellt der Deutsche Bundestag alle Plenarprotokolle OpenAccess in einem sehr rudimentären XML-Format bereit (1-19 Wahlperiode). Die vorhandenen Metadaten wurde extrahiert. Der Rohtext bereinigt und mittels TreeTagger annotiert (Token, Phrasen, Satz, POS, Lemma). In der aktuellen Version wird noch die gesamte Plenarsitzung als ein Dokument hinterlegt. Eine Aufteilung in einzelne Redebeiträge, wie im EUROPARL-Korpus, ist geplant.
Hinweis: Die laufende Legislaturperiode wird alle 3-4 Monate um neue Texte ergänzt.
5,39GB – 4345 Dokumente
~19 Mio. Sätze – 325,77 Mio. Token
Layer: Wort, POS, Lemma, Phrase
EuroParl – Deutsche Reden
(L1 & Übersetzungen)
Das „European Parliament Proceedings Parallel Corpus 1996-2011“ (http://www.statmt.org/europarl/) ist eine etablierte Anlaufstelle für alle, die ein paralleles Korpus suchen, das hochwertig/professionell übersetzte Texte enthält (Original zusammengestellt von Prof. Dr. Köhn). Für eine Diskursanalyse wurden alle verfügbaren Plenarprotokolle durch den CorpusExplorer gesplittet und bereinigt (Metadaten: File, UtteranceId, Speaker, Language, SpeakerID, Chapter), sowie mittels TreeTagger (POS-, Lemma-Tags) annotiert. Aktuell stehen nur die deutschen Protokolle zur Verfügung (L1 oder ins Deutsche übersetzte Reden). Auf Anfrage auch andere Sprachen möglich. Das Korpus umfasst 54,76 Token (Worte + Satzzeichen) und 201’066 Äußerungen/Dokumente aus 9’224 Plenarprotokollen.
NEU – Hinweis: Wenn Sie mit diesem Korpus arbeiten möchten, dann steht Ihnen im [10plus1journal] eine Video-Anleitung zur Verfügung. Diese zeigt, wie Sie mit dem EuroParl-Korpus und dem CorpusExplorer arbeiten können.
819MB – 201066 Dokumente
2,4 Mio. Sätze – 54,76 Mio. Token
Layer: Wort, POS, Lemma
Deutsche politische Reden
Es handelt sich um die zweite Veröffentlichung (Stand 2012) einer Redensammlung aus dem Bundespräsidial- und Kanzleramt. Erstellt wurde das Korpus von Adrien Barbaresi – Korpuslizenz: CC BY-SA v3.0 – Weitere Korpus-Inforamtionen, wie Erstellung, Zusammensetzung und Beispielanalysen finden Sie im technischen Bericht und unter: http://purl.org/corpus/german-speeches
51,45MB – 3270 Dokumente
0,145 Mio. Sätze – 2,68 Mio. Token
Layer: Wort, POS, Lemma, Phrase
Test-Korpora:
Für erste Tests mit dem CorpusExplorer eignen sich folgende Korpora:
- Tweets: Alle Tweets des Accounts notesjor (mein Account). Stand: 12.02.2019 – 27,7 Tsd. Token – Sprache: Deutsch – [DOWNLOAD]
- EuroParl: SIEHE OBEN – Das EuroParl-Korpus ist Grundlage für eine Video-Tutorial-Reihe zum CorpusExplorer. [DOWNLOAD]
- DTA-Korpus: SIEHE OBEN – Das Korpus wurde mit dem Ziel zusammengestellt, das gesamte Spektrum der deutschen Sprache zu erfassen und somit ein ausgewogenes historisches Referenzkorpus in deutscher Sprache zu schaffen. [DOWNLOAD]
- TextGrid-Korpus: SIEHE LINKS- Texte aus Belletristik und Sachliteratur vom Anfang des Buchdrucks bis zu den ersten Jahrzehnten des 20. Jahrhunderts in digitaler Form. [DOWNLOAD]