2021-02-13 | CorpusExplorer, InAppNote
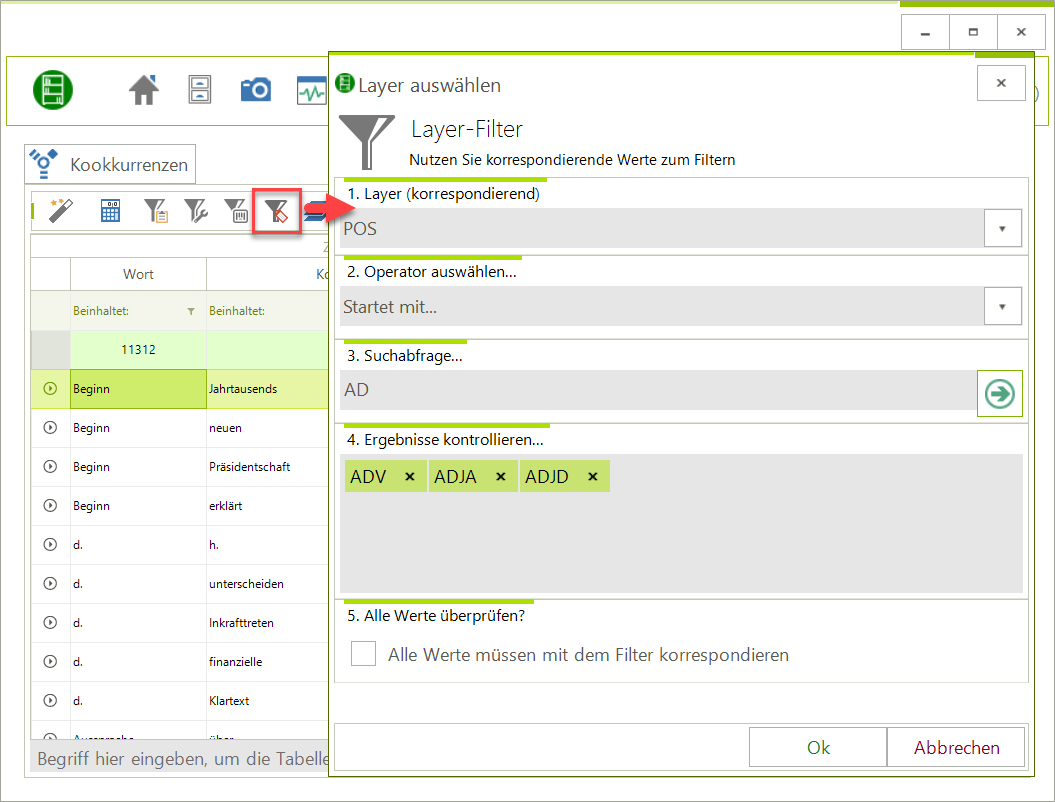
Kleines zusätzliches Update – zusätzlich zum Update Q1 2021. Neuerungen: Neues Format für: FOLKER/OrthoNormal FLN (annotieren & Import). Der Post-Analyse-Filter für korrespondierende Layer-Werte kann jetzt auch über die Konsole/Shell genutzt werden....
2021-02-08 | CorpusExplorer, InAppNote
Vielleicht irre ich mich – aber ich glaube, in 2021 werden einige große Dinge mit dem CorpusExplorer passieren. Zumindest haben sich viele Funktionen angesammelt, die darauf warten veröffentlicht zu werden. Also starten wir mir den Änderungen für Q1 2021:...