2026-03-15 | CorpusExplorer, InAppNote
Das Release Q1 2026 enthält keine neuen Features – nur kleinere und größere Fehlerkorrekturen (insbesondere durch Updates von Drittanbieter-Komponenten). Aktuell teste ich, ob HDF5 eine Alternative zum CEC6-Format sein kann. Es laufen auch größere Umbauarbeiten...
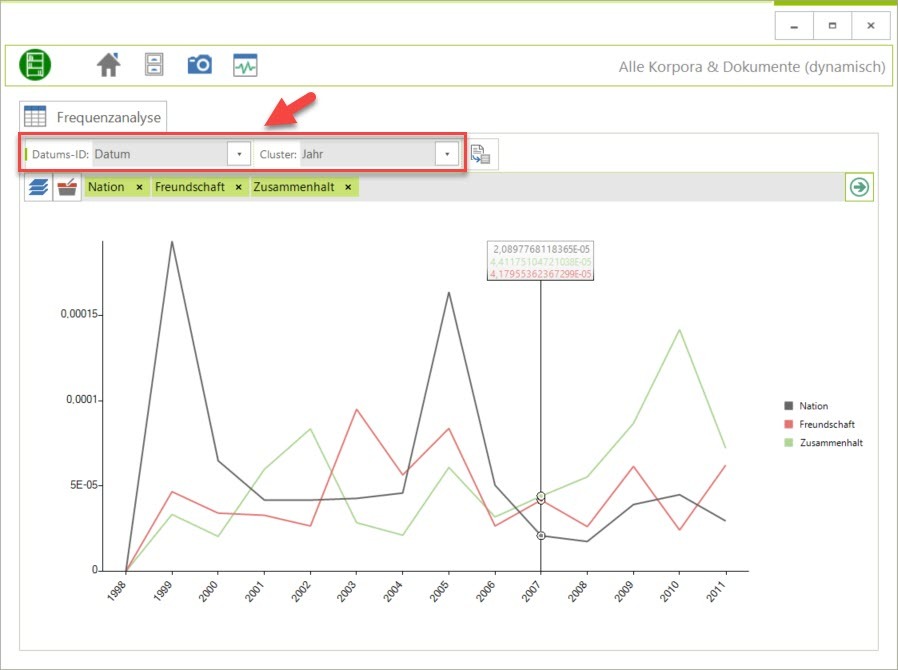
2025-10-11 | CorpusExplorer, InAppNote
CorpusExplorer – Releasenotes Q4 / 2025 Wichtige Neuerungen Überarbeitete Zeitverlaufs-Analysen Die Analyse über Zeitverläufe wurde grundlegend überarbeitet und flexibler gestaltet: Datentyp unabhängige Zeitangaben: Es ist nun nicht mehr erforderlich, dass Zeitangaben...
2025-08-26 | CorpusExplorer, InAppNote
Dieses Update umfasst nur kleinere Korrekturen und Fehlerbehebungen. Größere Neuerungen werden dann in Q4 2025 folgen. Genießt den Sommer
2025-03-23 | CorpusExplorer, InAppNote
Das erste Quartals-Update (Q1) für 2025 bringt folgende Neuerungen und Verbesserungen: Verbesserung der Performance für verschiedene Volltext-Filter/Suchen. Insbesondere für exakte und flexible Phrasen. Filter um Multi-Layer NGramme selektiv zu filtern. Die Analysen...
2024-12-18 | CorpusExplorer, InAppNote
So, das letzte Update für dieses Jahr. Ich wünsche euch schon einmal frohe Feiertage und einen guten Start ins Jahr 2025. Folgende Neuerungen / Änderungen und Verbesserungen gibt es: Salt-XML kann jetzt direkt importiert werden. Eine Installation von Salt&Pepper...