2015-10-14 | CorpusExplorer
Was ist neu im Oktober Release des CorpusExplorers? Neue Scraper für EPUB, DSpin-XML & PDF. Neuer Scraper „Auf gut Glück!“ – versucht aus allen Dateien den größtmöglichen Textinhalt zu extrahieren. Mengenoperationen für Schnappschüsse...
2015-06-08 | CorpusExplorer
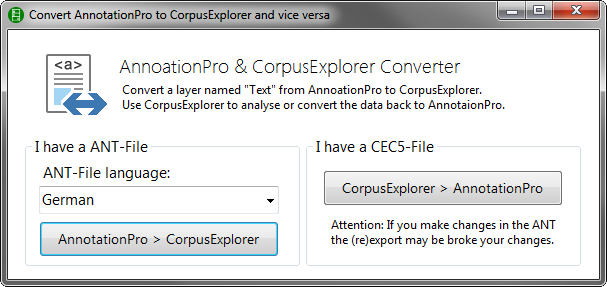
Wie in [diesem Artikel] angekündigt, gibt es jetzt eine Im-/Exporter für AnnotationPro und CorpusExplorer, der in beide Richtungen funktioniert. Bisher konnten ANT-Dateien im CorpusExplorer eingelesen werden. Jetzt können die Daten auch wieder an AnnotationPro zurück...
2015-04-26 | CorpusExplorer
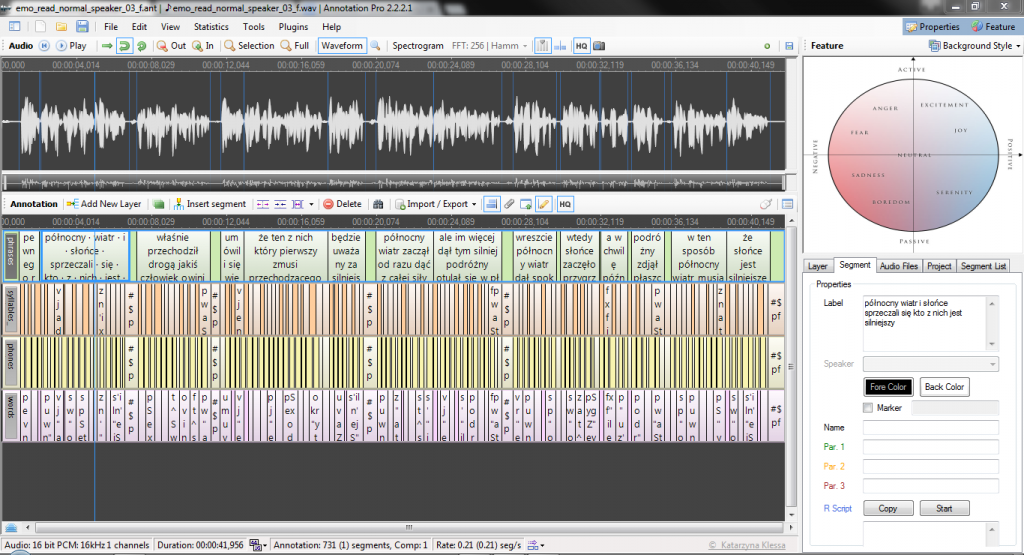
Auf die Frage einer Projektgruppe: Ob denn in naher Zukunft vorgesehen sei, dass der CorpusExplorer auch Transkription von Audio-/Video-Daten unterstützt – war meine Antwort: „Dazu fehlt leider die Zeit und das Budget“. Aber die neue Version (2.0...
2012-05-04 | Magisterarbeit
H. Rosling hält einen sehr spannenden Vortrag über Entwicklungsländer, wie wir diese sehen und was die Daten(-lage) dazu sagen. Daher sein Motto: „Your Mindset vs. My Dataset“ – Es zeigt sich das Datenvisualisierung durchaus auch bei der...