CorpusExplorer
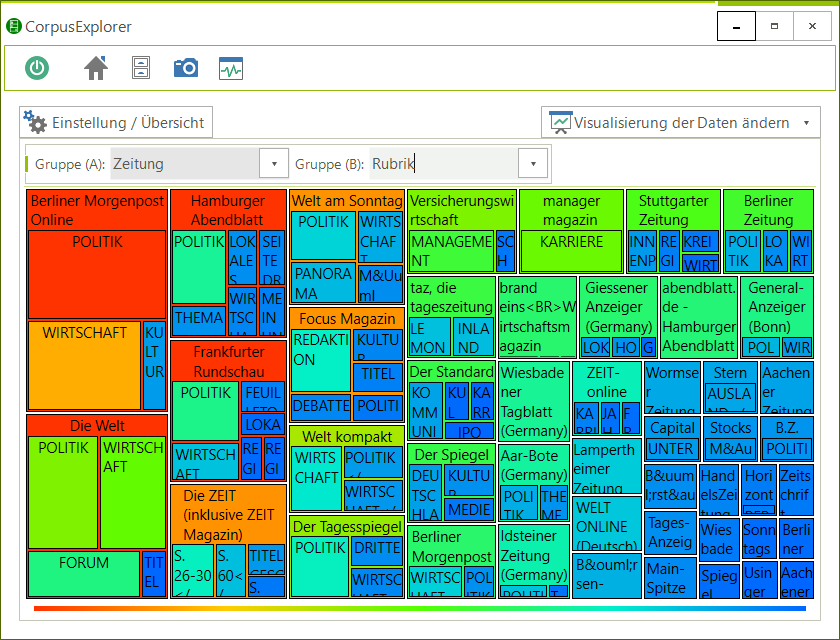
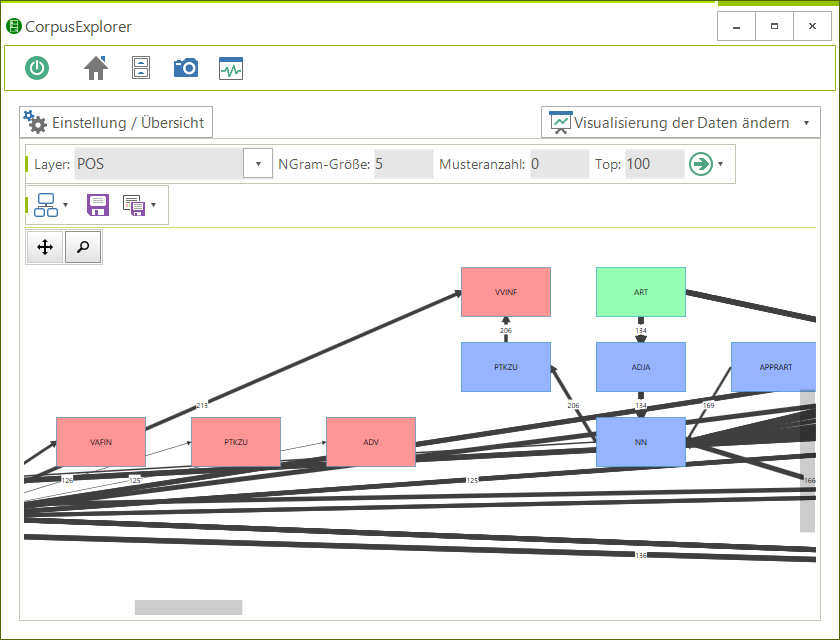
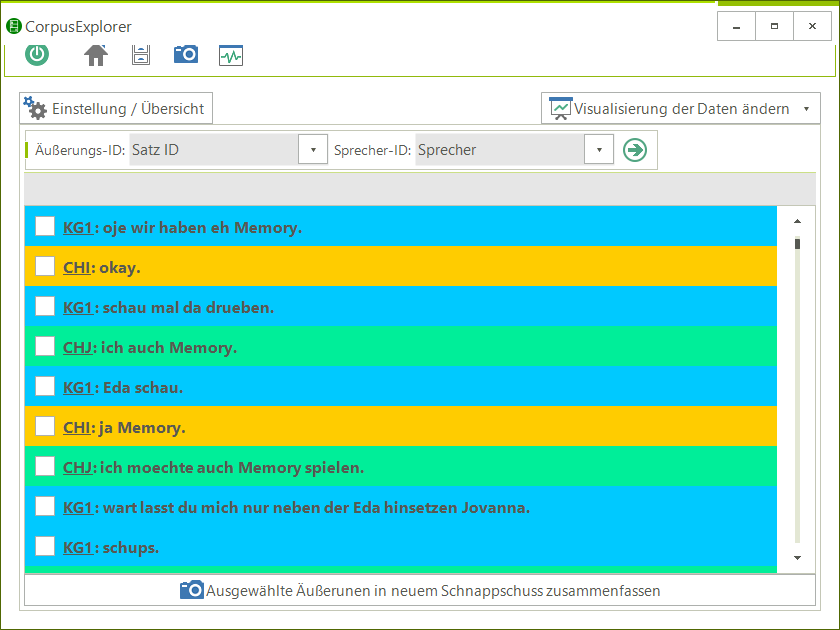
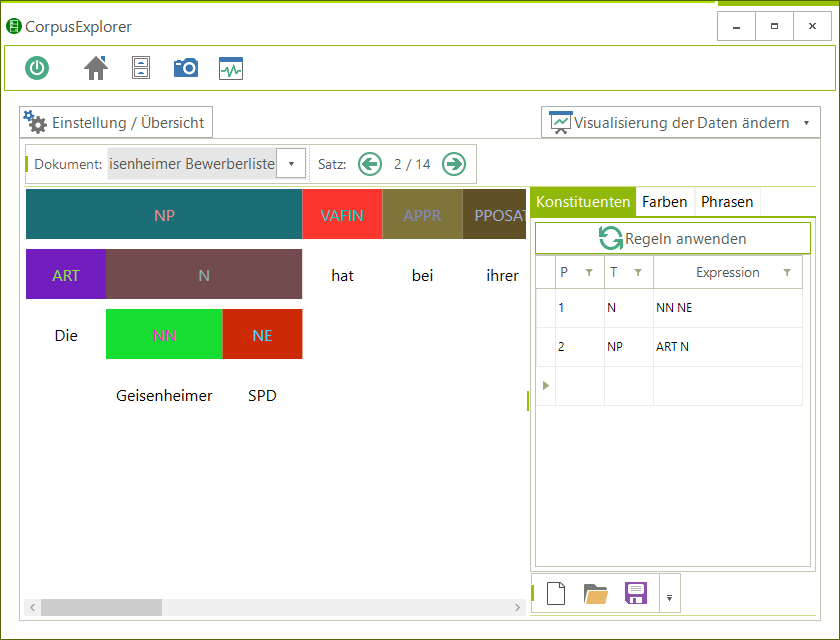
 Software für Korpuslinguist*innen und Text-/Data-Mining Interessierte. Der CorpusExplorer vereint über 50 interaktive Auswertungsmöglichkeiten mit einer einfachen Bedienung. Routineaufgaben wie z. B. Textakquise, Taggen oder die grafische Aufbereitung von Ergebnissen werden vollständig automatisiert. Die einfache Handhabung erleichtert den Einsatz in der universitären Lehre und führt zu schnellen sowie gehaltvollen Ergebnissen. Dabei ist der CorpusExplorer offen für viele Standards (XML, CSV, JSON, R, u. v. m.) und bietet darüber hinaus ein eigenes Software Development Kit (SDK) an, mit dem es möglich ist, alle Funktionen in eigene Programme zu integrieren.
Software für Korpuslinguist*innen und Text-/Data-Mining Interessierte. Der CorpusExplorer vereint über 50 interaktive Auswertungsmöglichkeiten mit einer einfachen Bedienung. Routineaufgaben wie z. B. Textakquise, Taggen oder die grafische Aufbereitung von Ergebnissen werden vollständig automatisiert. Die einfache Handhabung erleichtert den Einsatz in der universitären Lehre und führt zu schnellen sowie gehaltvollen Ergebnissen. Dabei ist der CorpusExplorer offen für viele Standards (XML, CSV, JSON, R, u. v. m.) und bietet darüber hinaus ein eigenes Software Development Kit (SDK) an, mit dem es möglich ist, alle Funktionen in eigene Programme zu integrieren.
[Download & weitere Informationen finden Sie hier.]
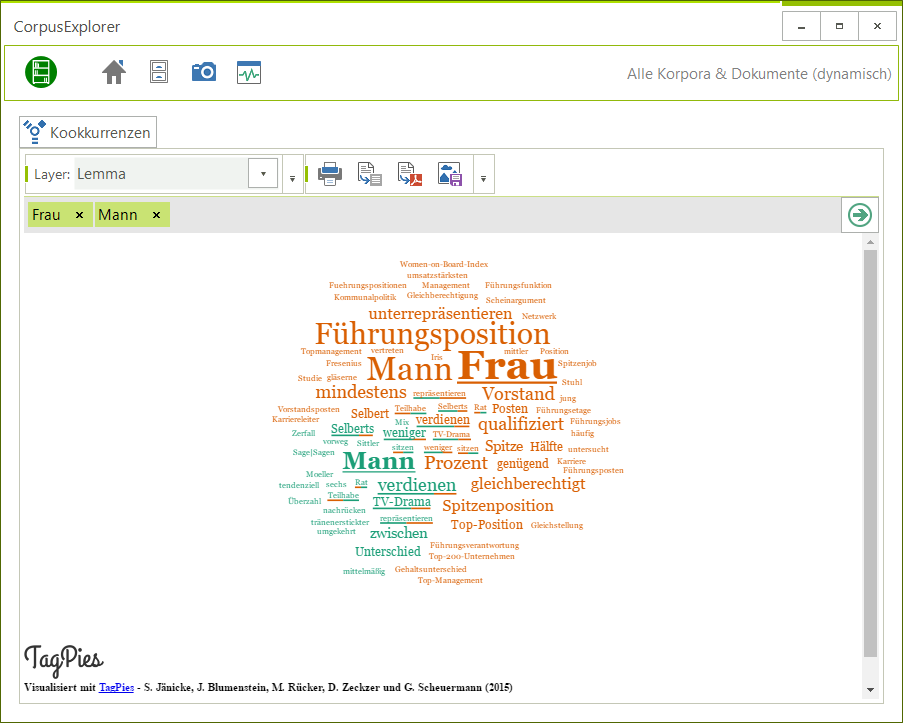
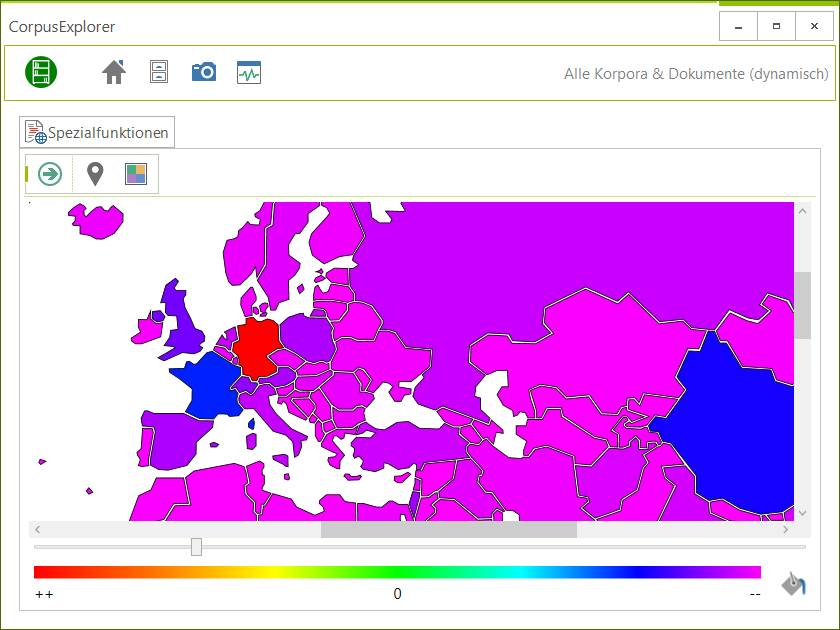
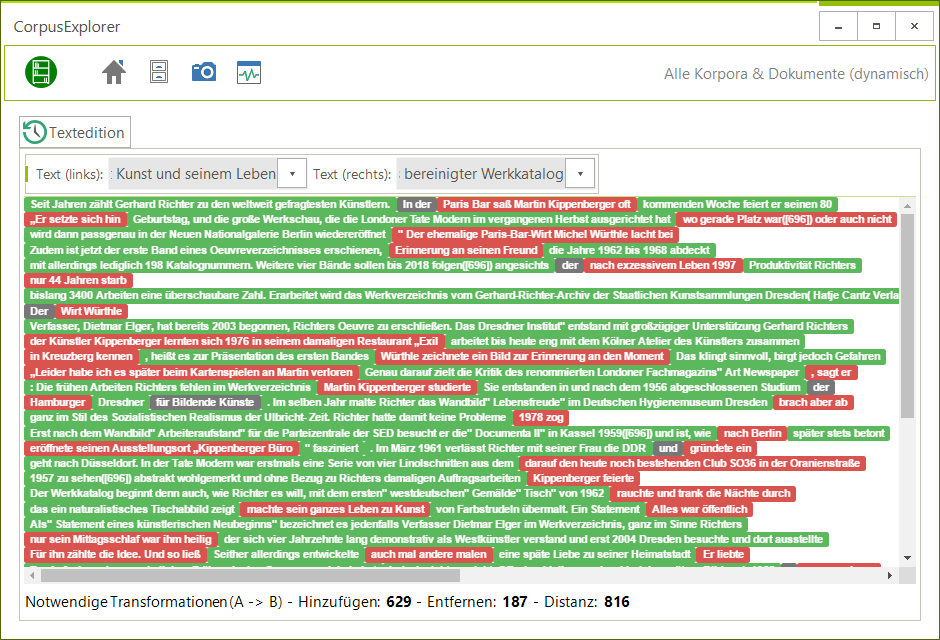
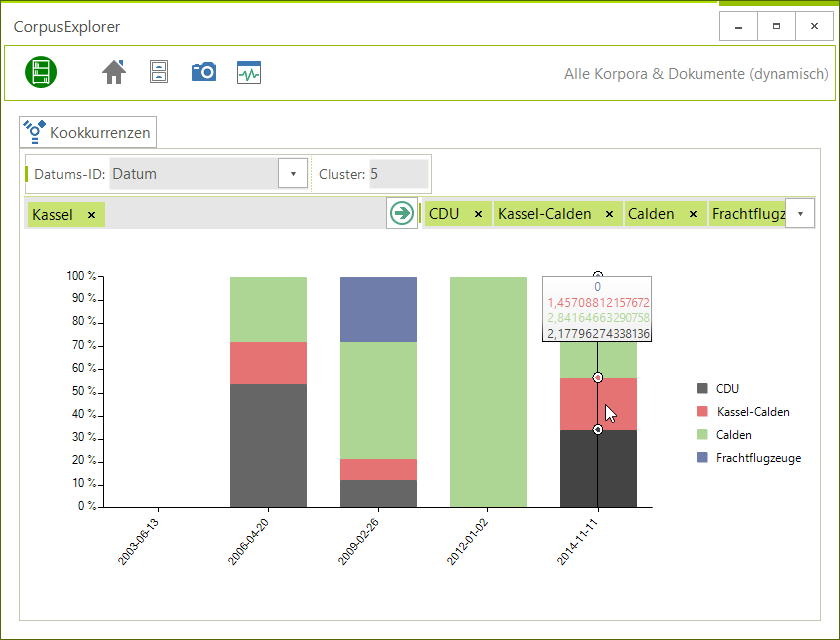
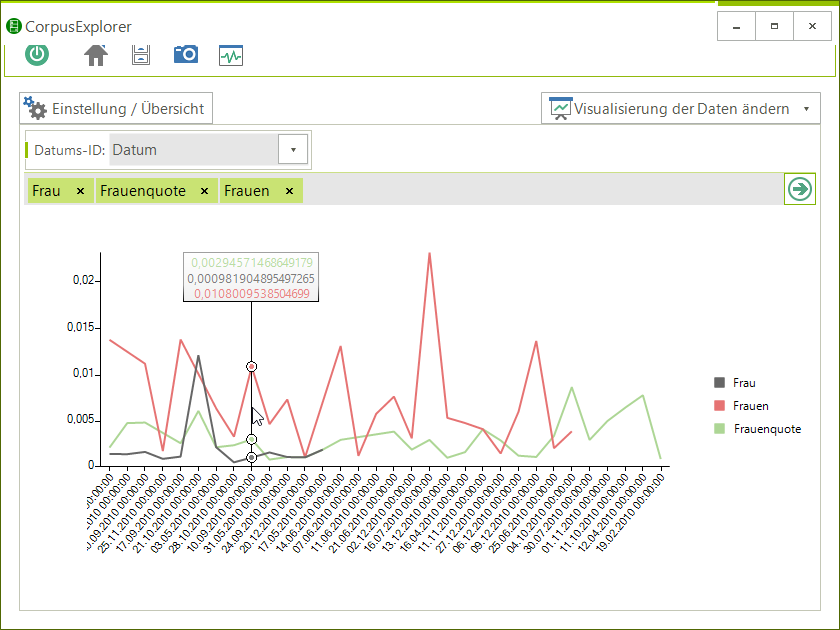
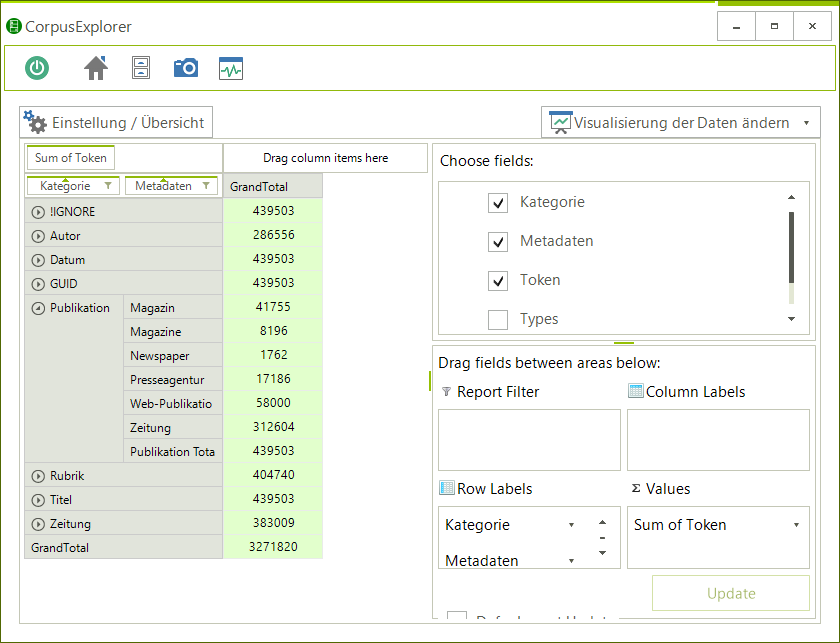

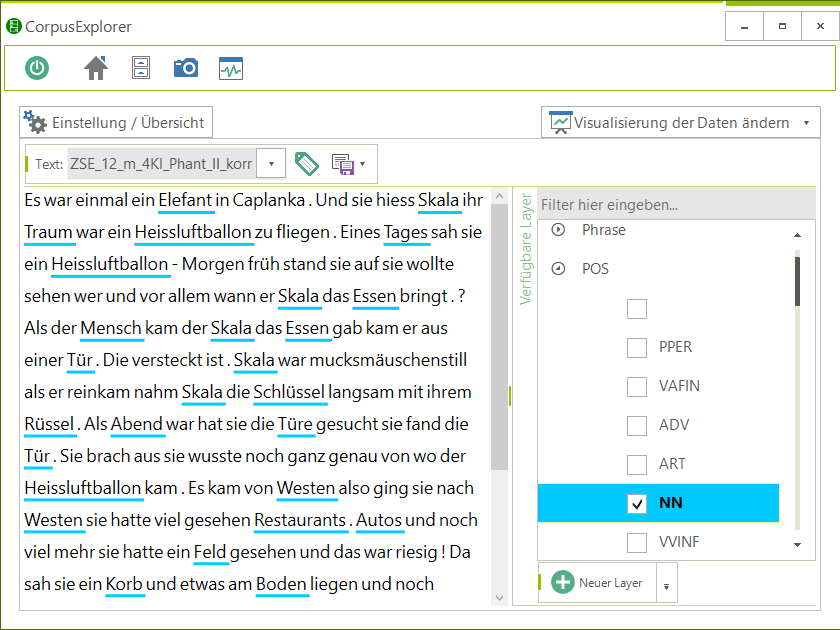
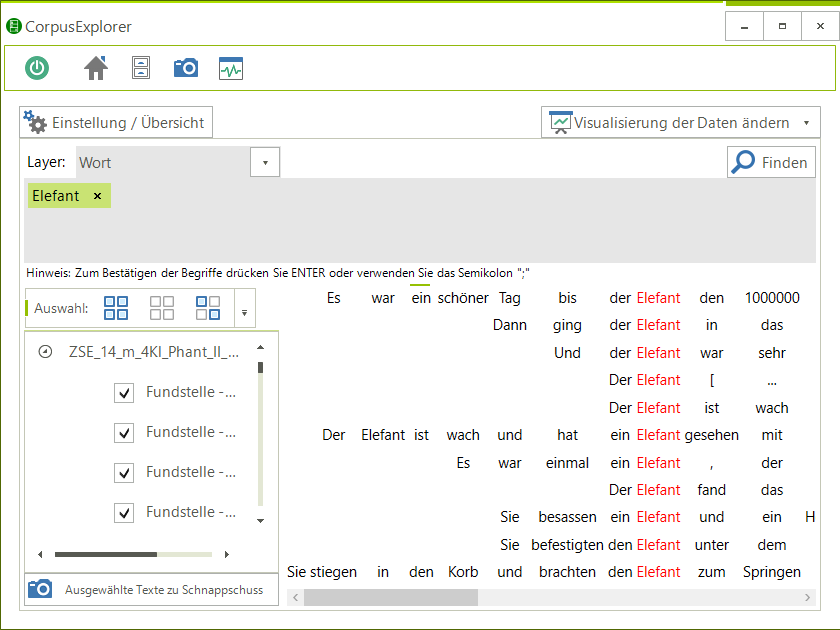
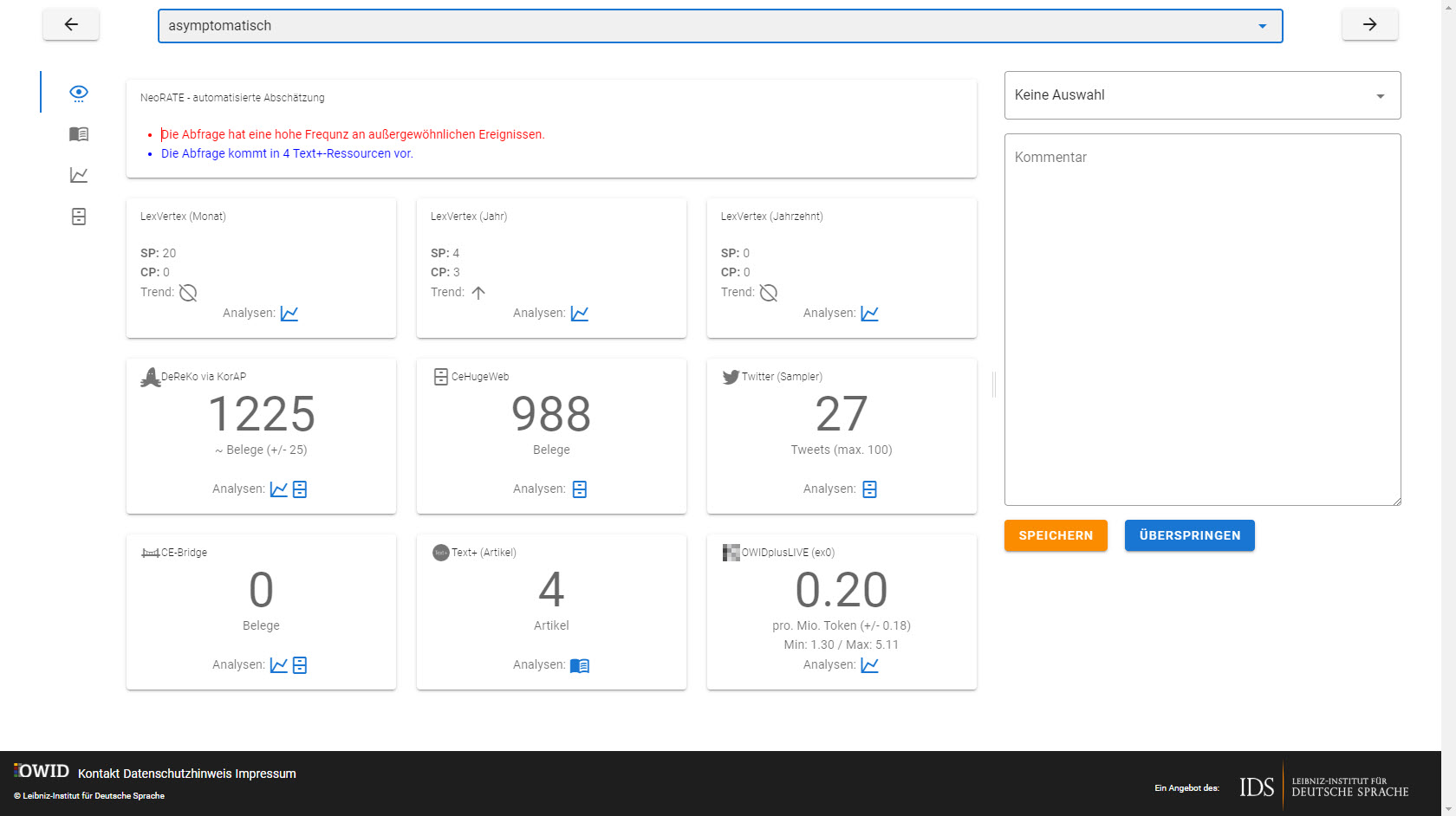
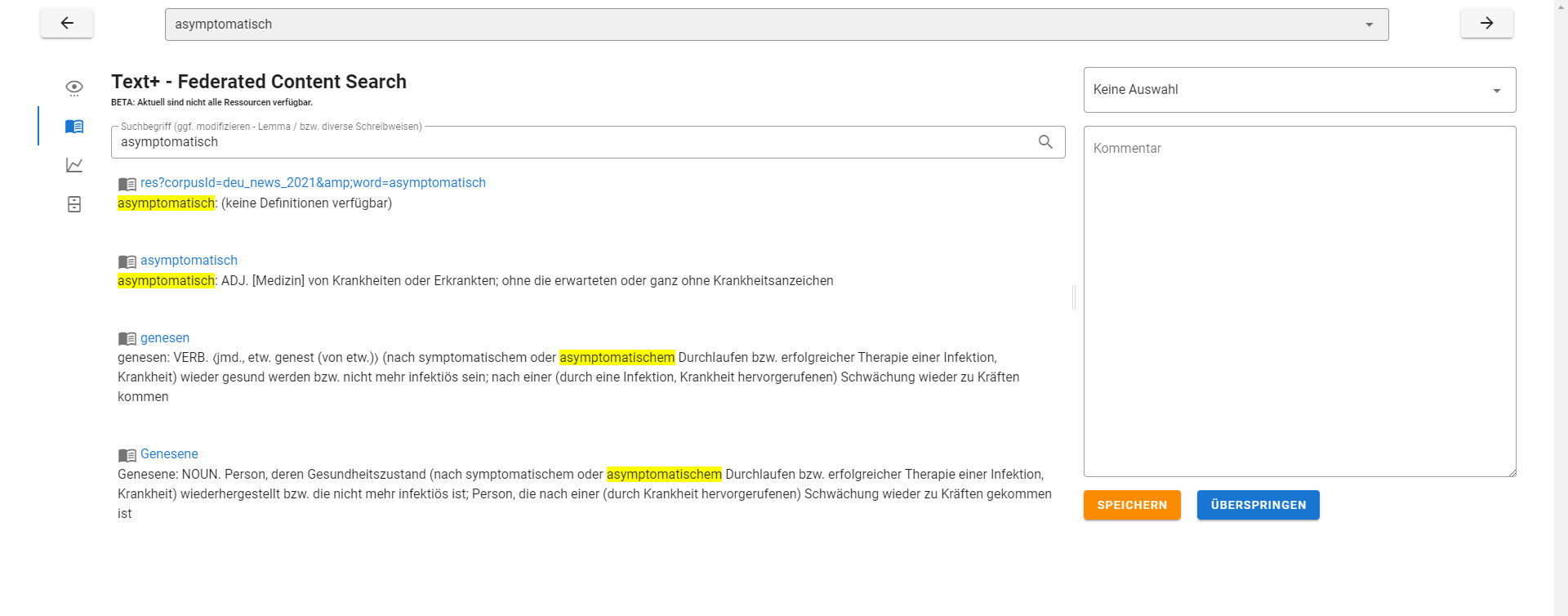
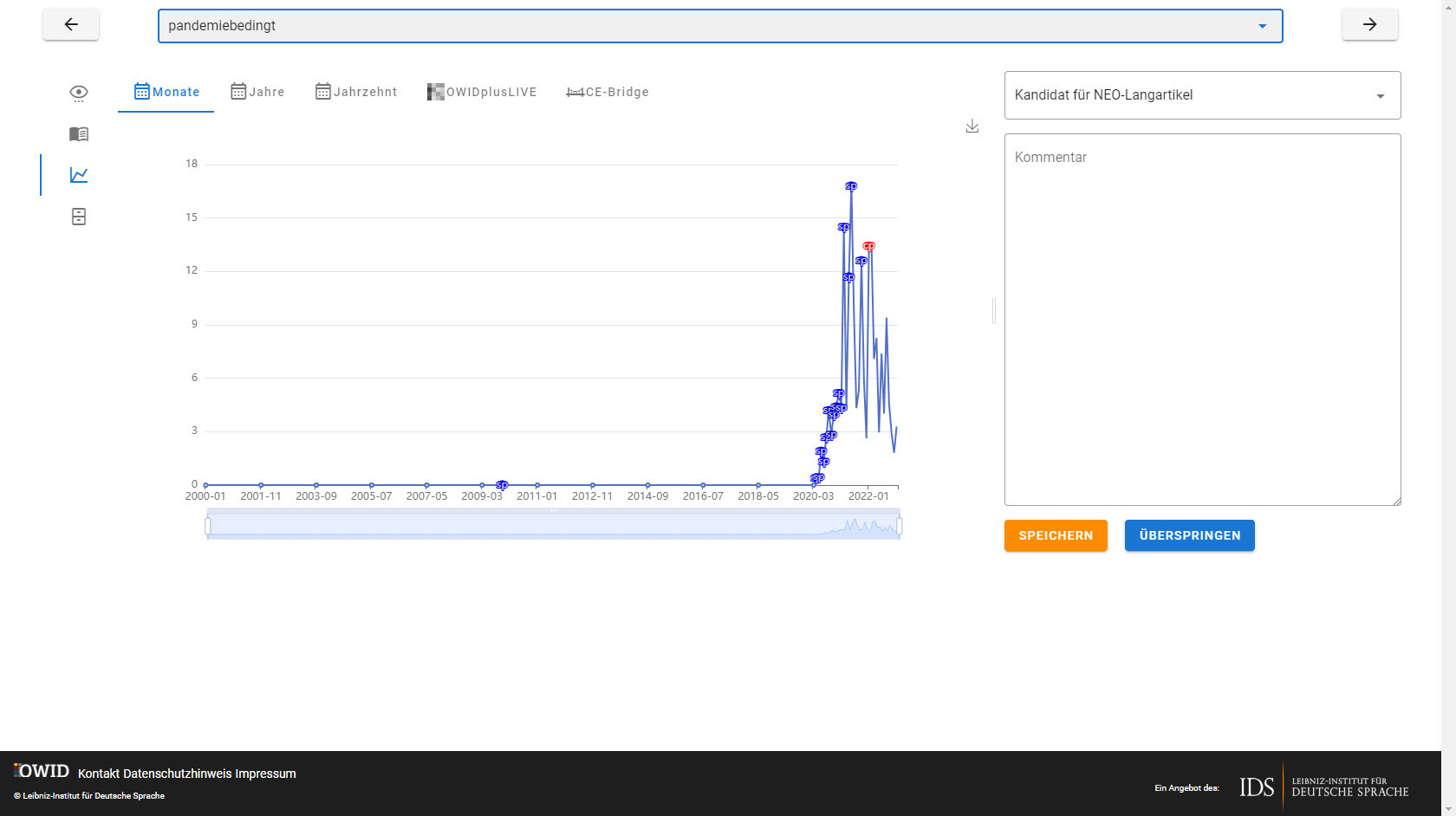
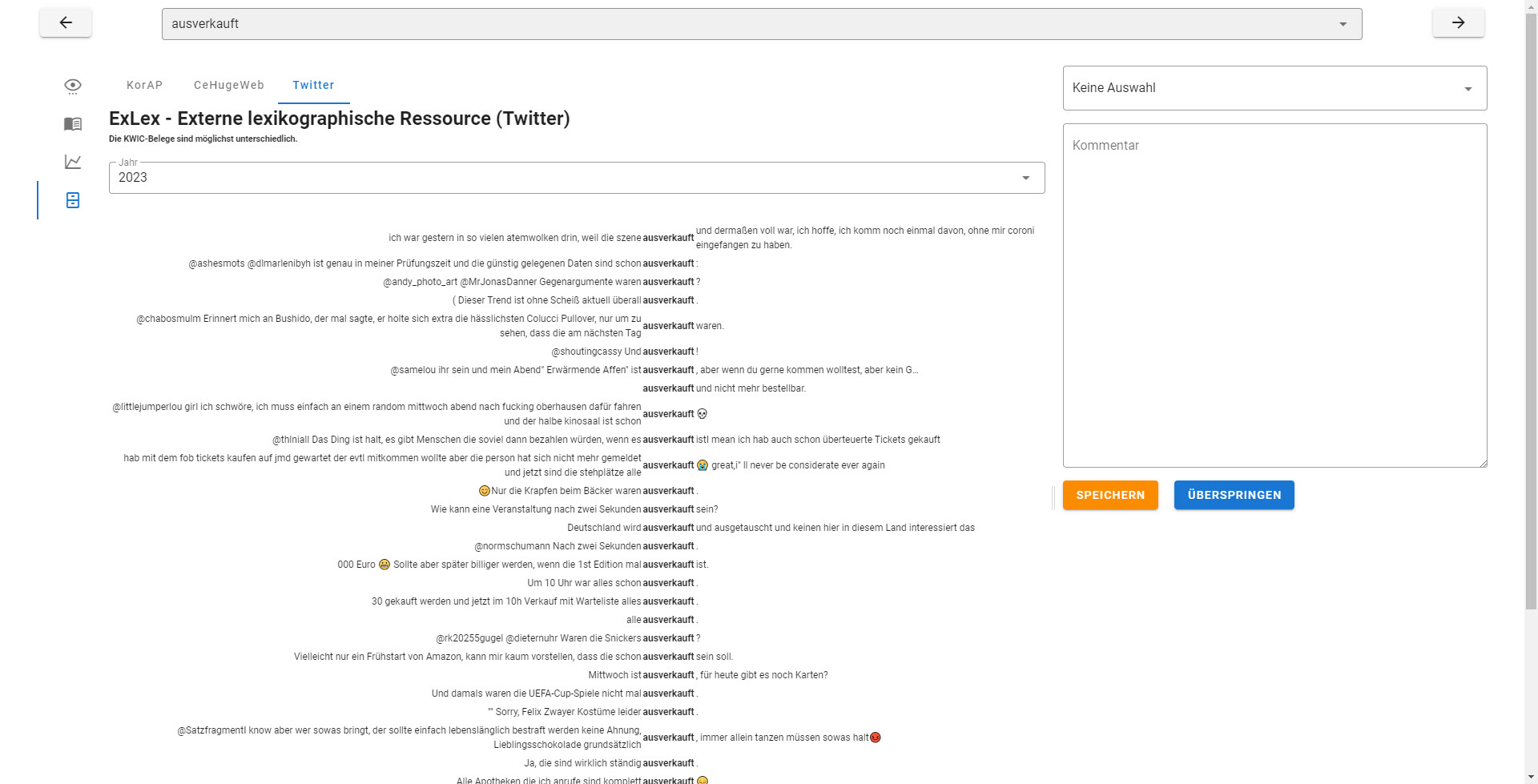
NeoRATE
NeoRATE ist eine Software zur Analyse von Neologismen. NeoRATE greift dabei auf bereits bestehende Infrastrukturen und Verfahren zurück, die sich am „Leibniz-Institut für Deutsche Sprache“ für die Neologismen-Detektion etabliert haben. Die kontinuierlich ermittelte Kandidatenliste wird dann mit weiteren in-/externen Datenressourcen abgeglichen und angereichert. Das NeoRATE-System gibt dann auf Basis dieser Informationen Abschätzungen und Hinweise sowie Detailanalysen zu möglichen Kandidaten bzw. erlaubt das schnelle Aussortieren nicht relevanter Token.
OWIDplusLIVE
Mit OWIDplusLIVE können Sie tagesaktuell (zum Vortag) in ausgewählten deutschsprachigen RSS-Feeds nach Einzeltoken und N-Grammen suchen. Auch lemma- und wortartenbasierte Suchen sind möglich. Ergebnisse können exploriert und auf unterschiedlichen Arten visualisiert werden. OWIDplusLIVE setzt die Entwicklung von „cOWIDplus Viewer/Analyse“ fort.

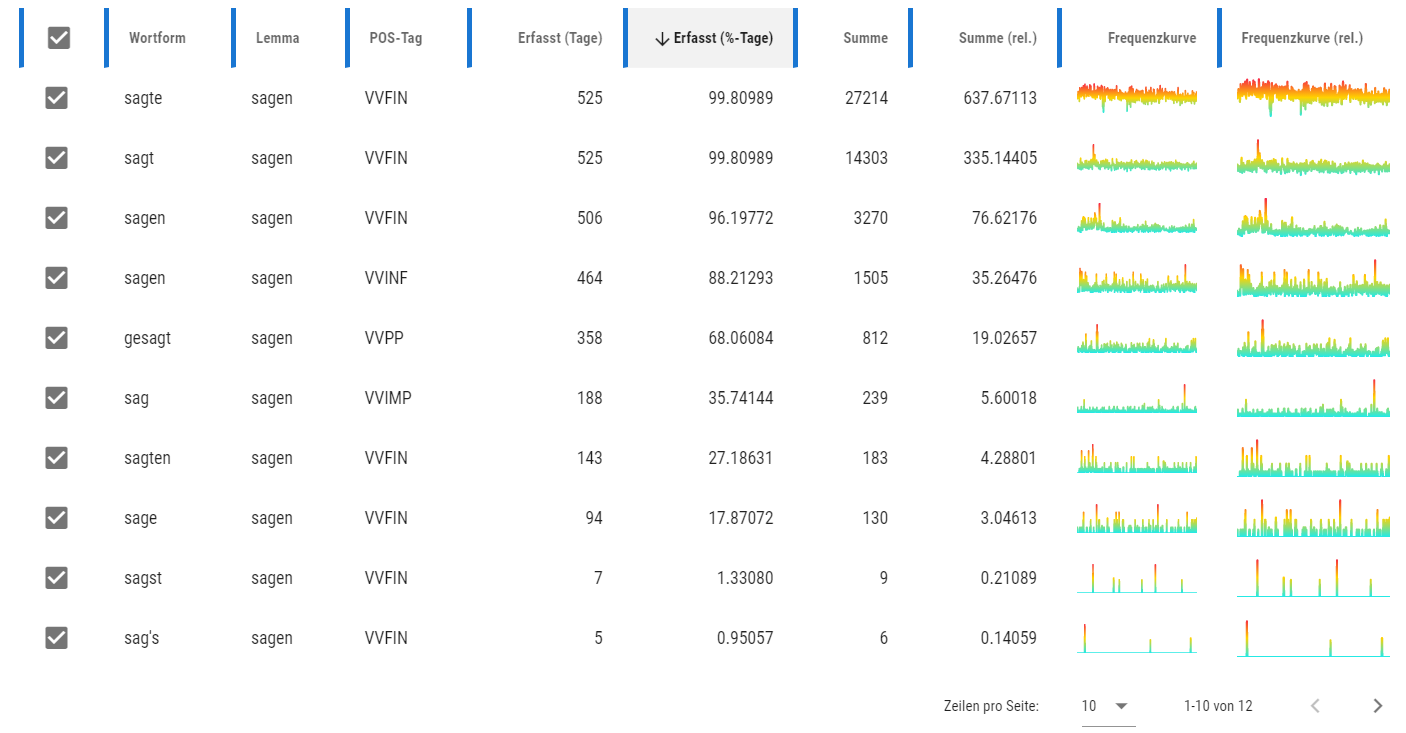
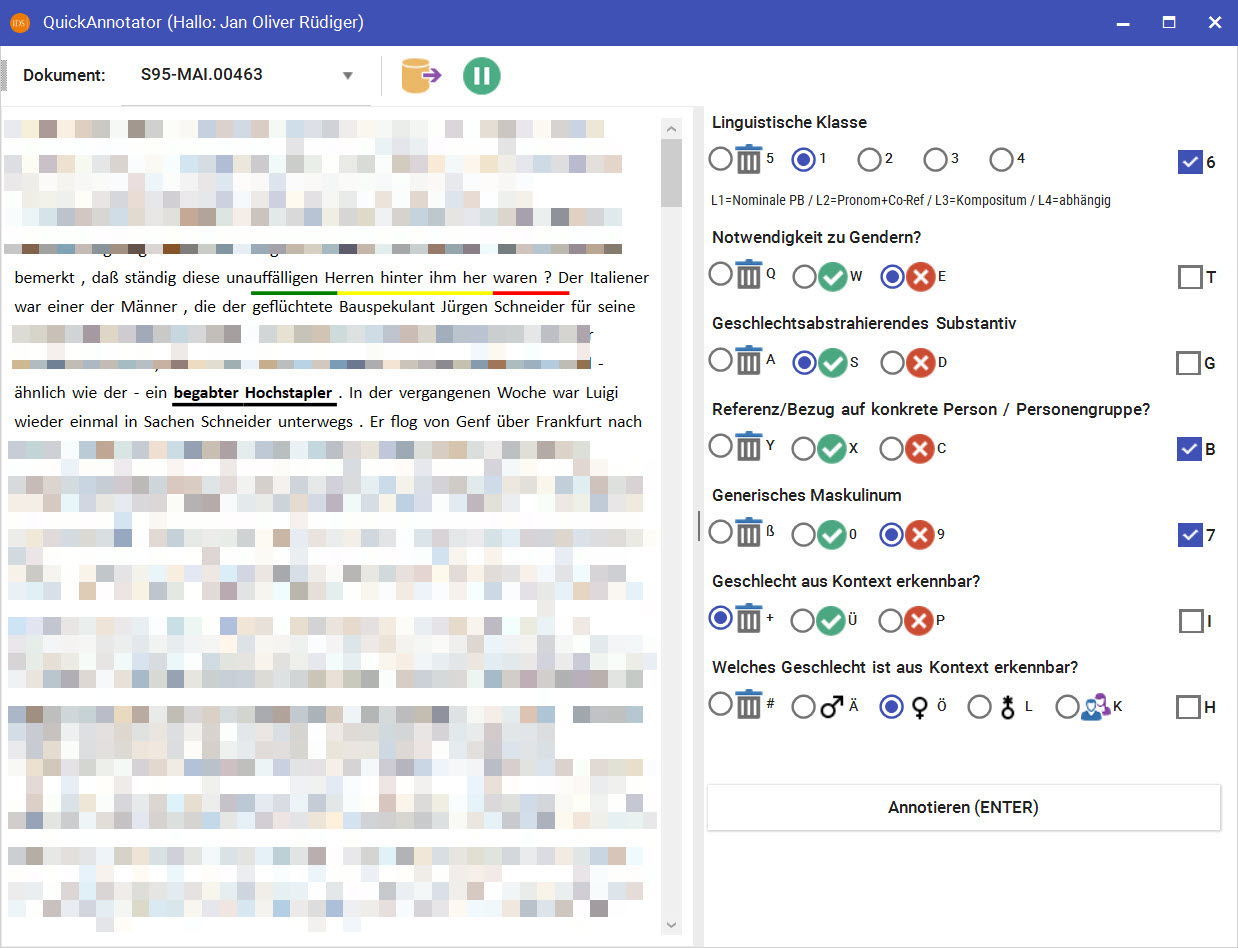
QuickAnnotator – Programmoberfläche
Programm-Obergläche. Einige Text-Teile wurden manuell verpixelt. Auswahl der Bereiche (links) und Annotationen (rechts) sind beispielhaft.

QuickAnnotator – Vergleich
Ausschnitt aus einem annotierten Dokument. Die Farben markieren die unterschiedlichen Annotator*innen. Unterschiede in der Annotation werden fett hervorgehoben.
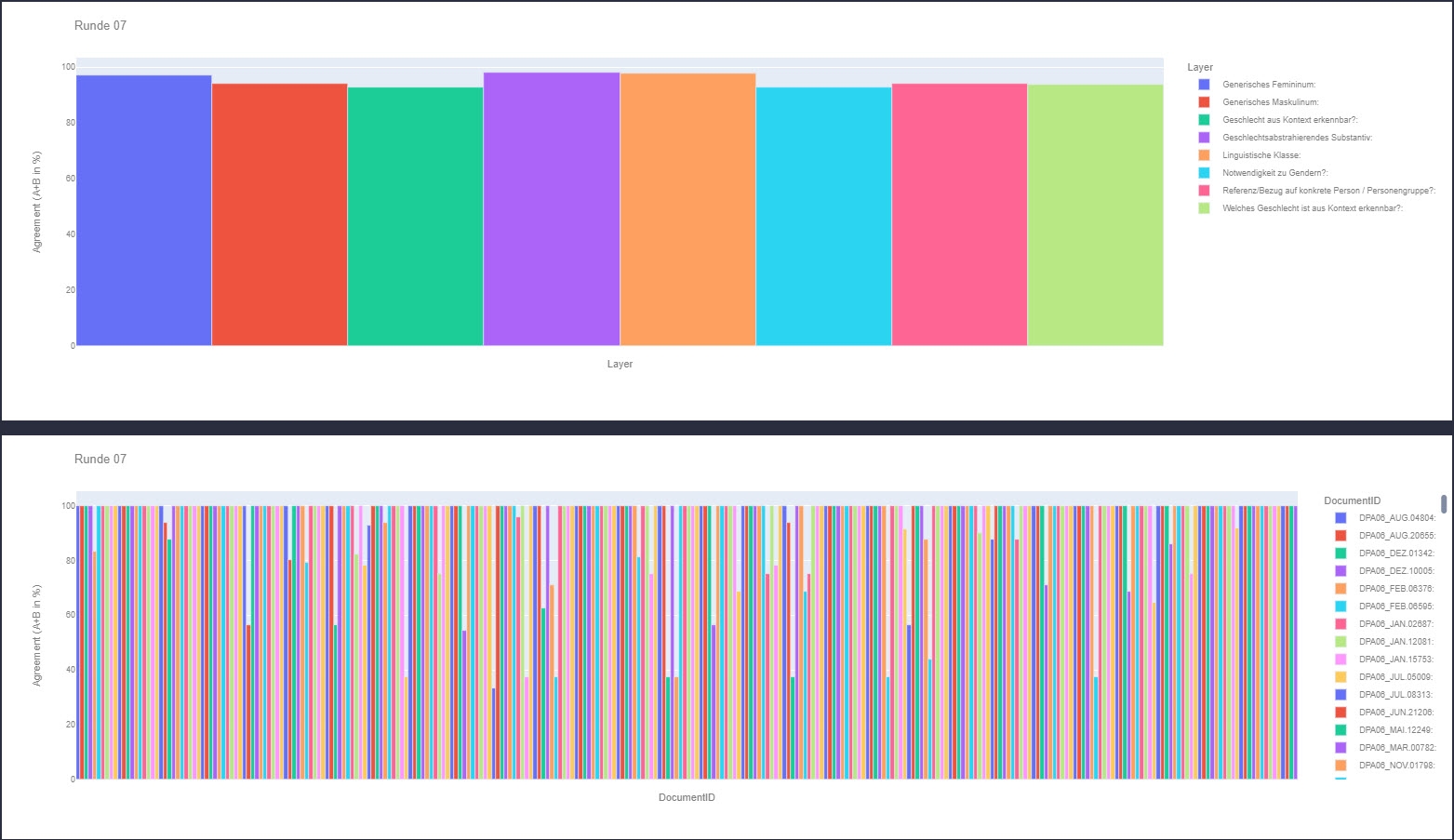
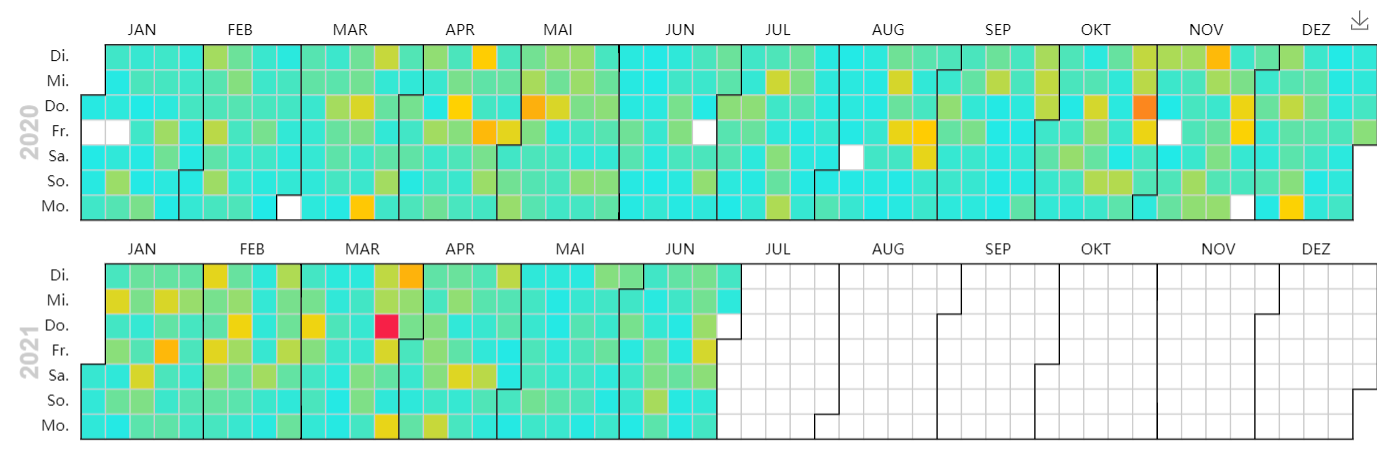
QuickAnnotator – Auswertung
Die folgende Auswertung bezieht sich auf eine beispielhafte Charge. Analysiert wird das Inter-Annotator-Agreement auf der Ebene der Layer und den Dokumenten. So lassen sich z. B. strittige Annotationen oder Dokumente finden.
QuickAnnotator
Der QuickAnnotator entstand als Prototyp für das Projekt „Empirische Genderlinguistik„. Der Editor erlaubt die Abbildung komplexer Annotationsschemata und assistiert den Annotationsprozess, indem nur relevante (abhängige) Annotationen angezeigt werden. Mehrere Personen können parallel annotieren – dabei sieht jede Person nur die eigenen Annotationen. Die Kommunikation mit dem Server basiert auf einer RESTful-API. Der Server speichert alle Annotationshandlungen und erlaubt Analysen und Vergleiche auf den annotierten Daten.
Die mit dem QuickAnnotator erstellten Annotationen liefern z. B. Daten für folgende Projekte/Paper:
TFRES-TinyFastRestEndpointServer
TFRES wurde als Minimal-Fork des WatsonWebservers entwickelt. TFRES reduziert die Funktionalitäten des ursprünglichen Webservers auf ein absolutes Minimum und wurde für folgende Aspekte optimiert: Geschwindigkeit, Sicherheit und einfache Benutzung – mit speziellem Fokus auf Micro-Service-Architekturen. Der Quellcode (s. u. – ausklappbar) illustriert für einen einfachen REST-WebService. Der Zugriff auf GET-Parameter und HTTP-ContentBody (z. B. per POST/PUT / inkl. einer integrierten De-/Serialisierung von JSON) ist sehr einfach gestaltet und das Streaming von Daten wird unterstützt. Im Gegensatz zu WCF basierten REST-WebServices verfügen TFRES über einen wesentlich geringeren Memory-Footprint (WCF verbraucht schnell mehr als 100 MB RAM – TFRES kommt mit ca. 5-20 MB aus). Wichtig: TFRES unterstützt keine Transportverschlüsselung (KISS-Prinzip). Wenn Sie eine Transportverschlüsselung benötigen, müssen Sie diese mittels Reverse Proxy realisieren (Anleitung). TFRES kommt im CorpusExplorer (Bereitstellung von Korpora als WebService), im Diskursmonitor (für die Micro-Service Architektur), für das Projekt OpenSourceTelemetrie (für den Bau der WebService-Komponenten) sowie in Drittanwendungen zum Einsatz. [Den OpenSource Quellcode finden Sie hier]
Ältere Projekte
(keine aktive Weiterentwicklung)
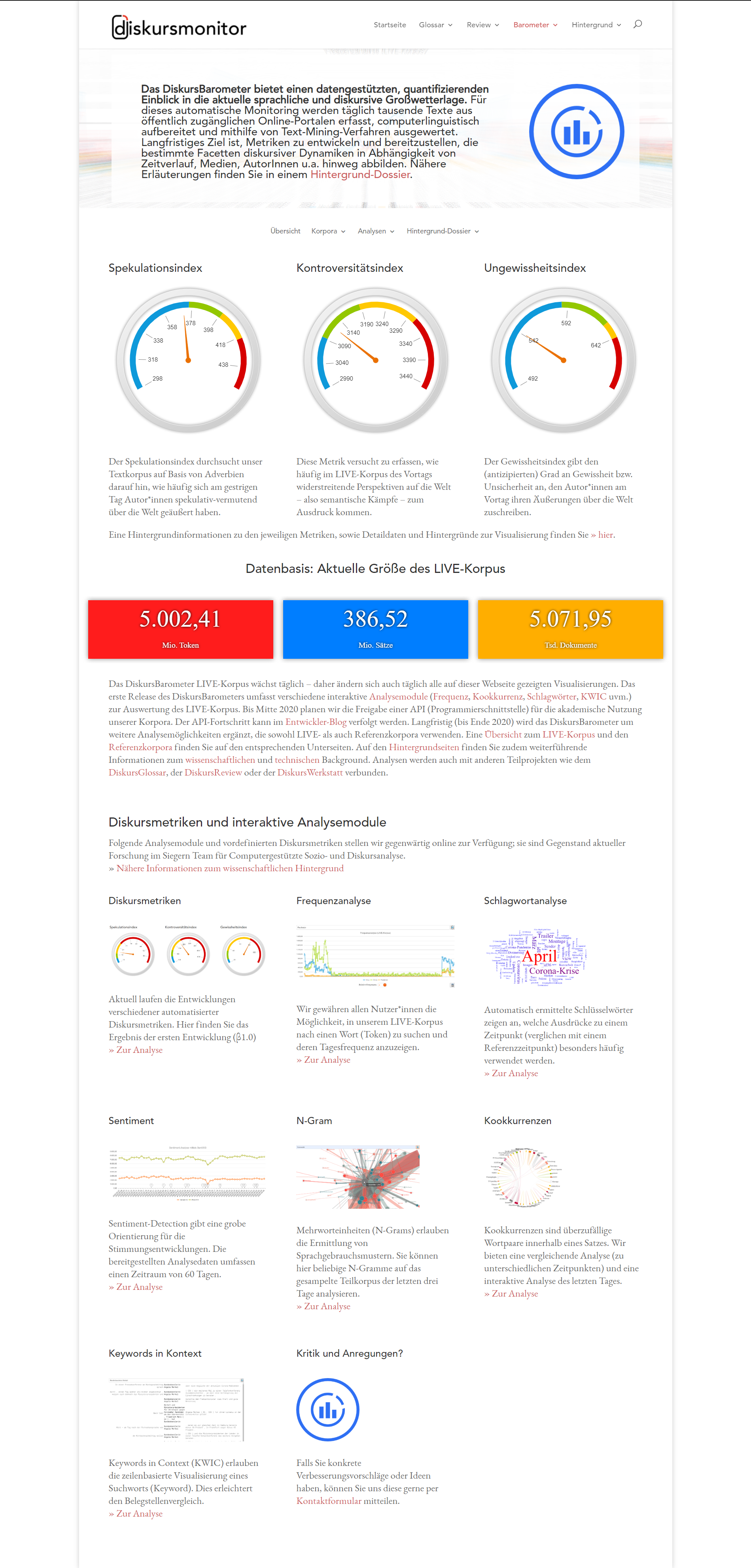
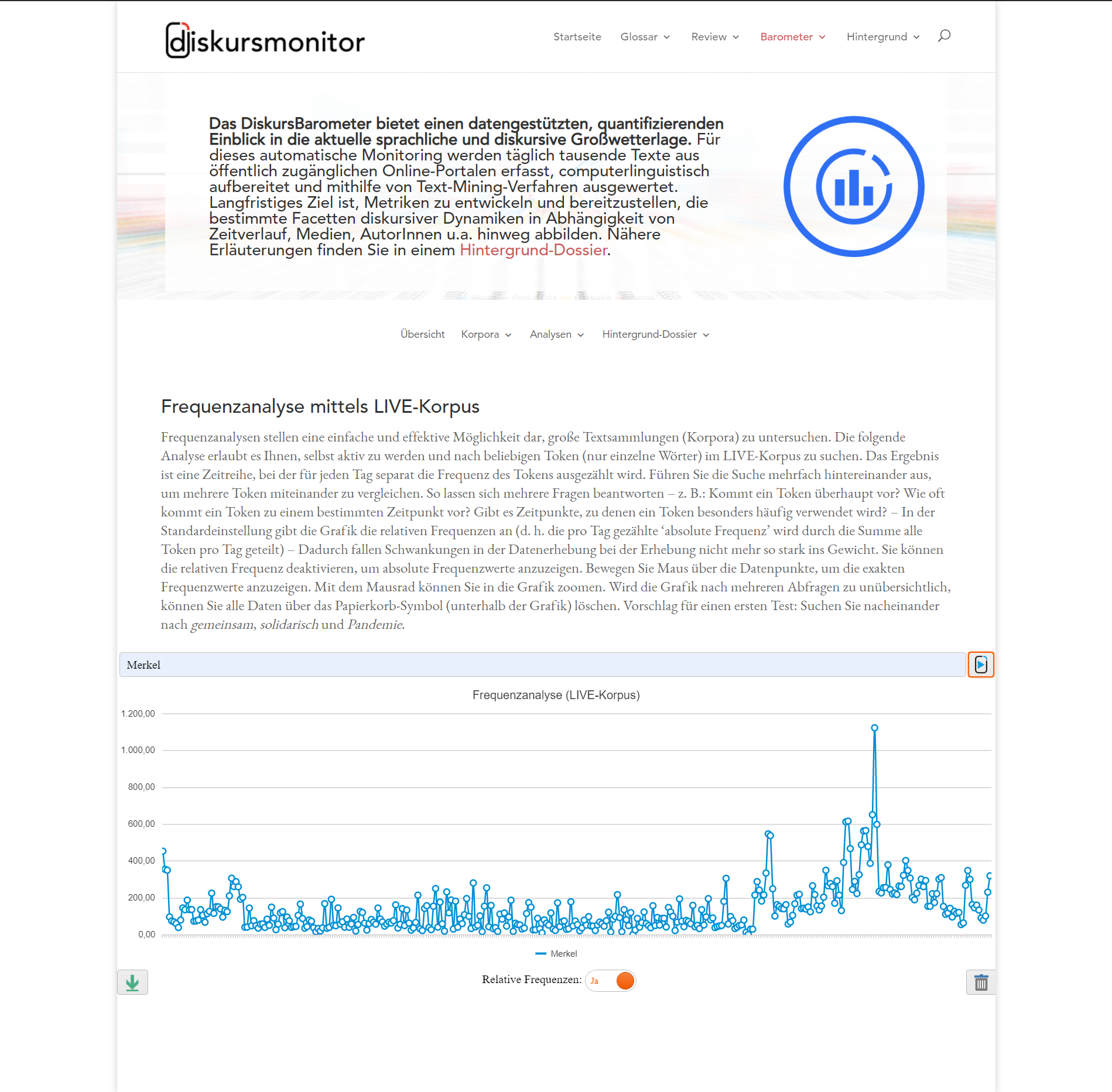
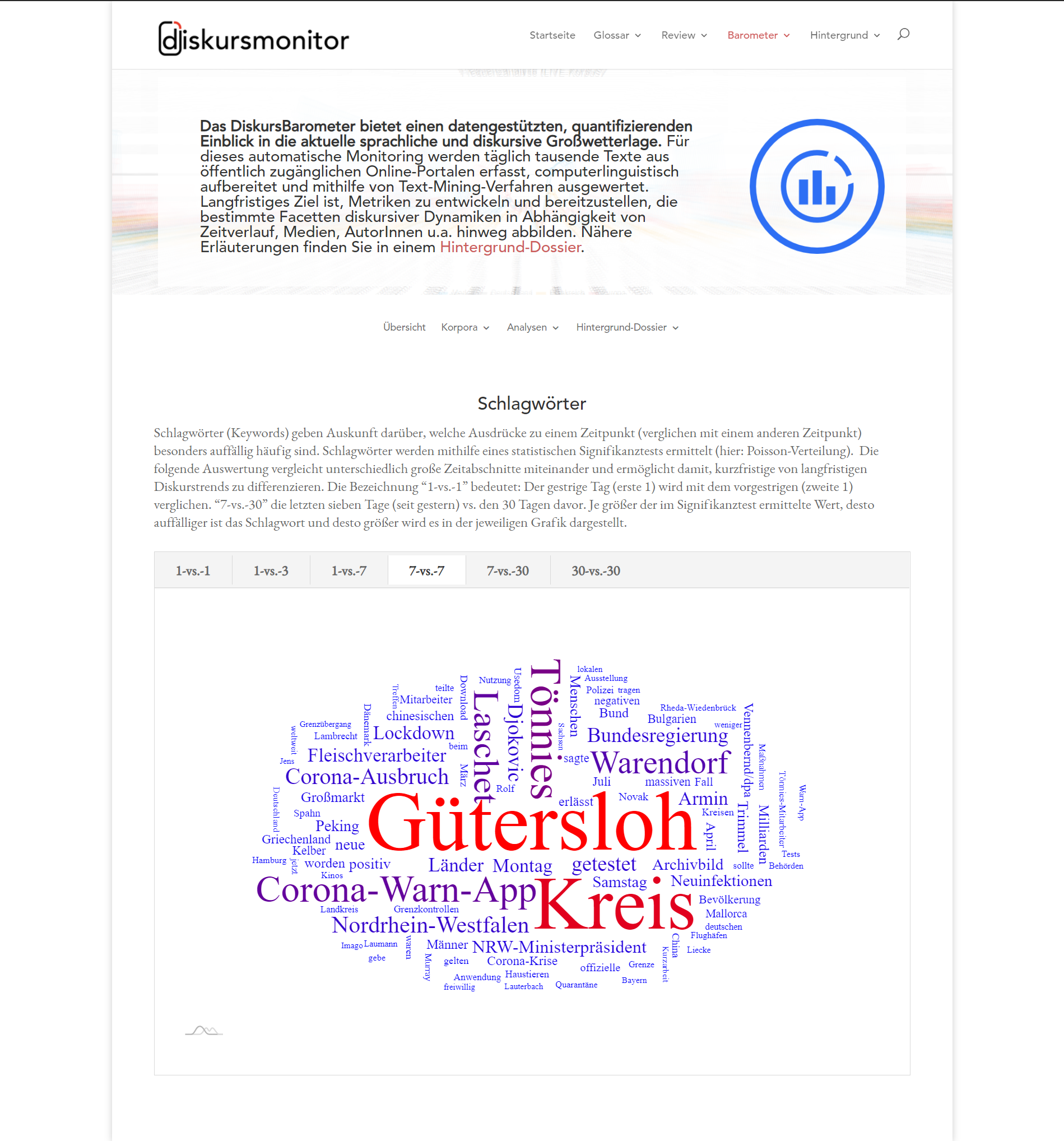
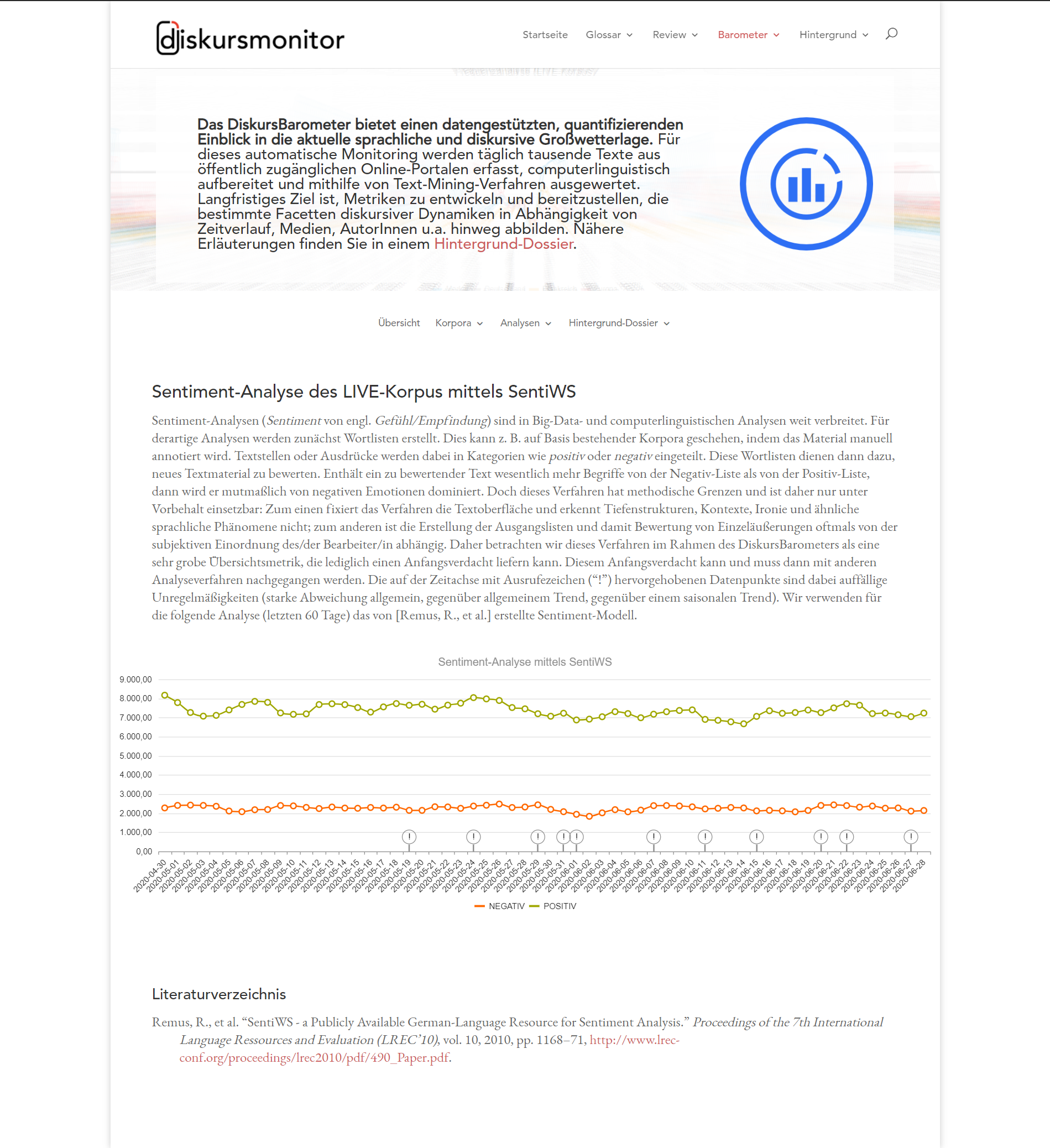
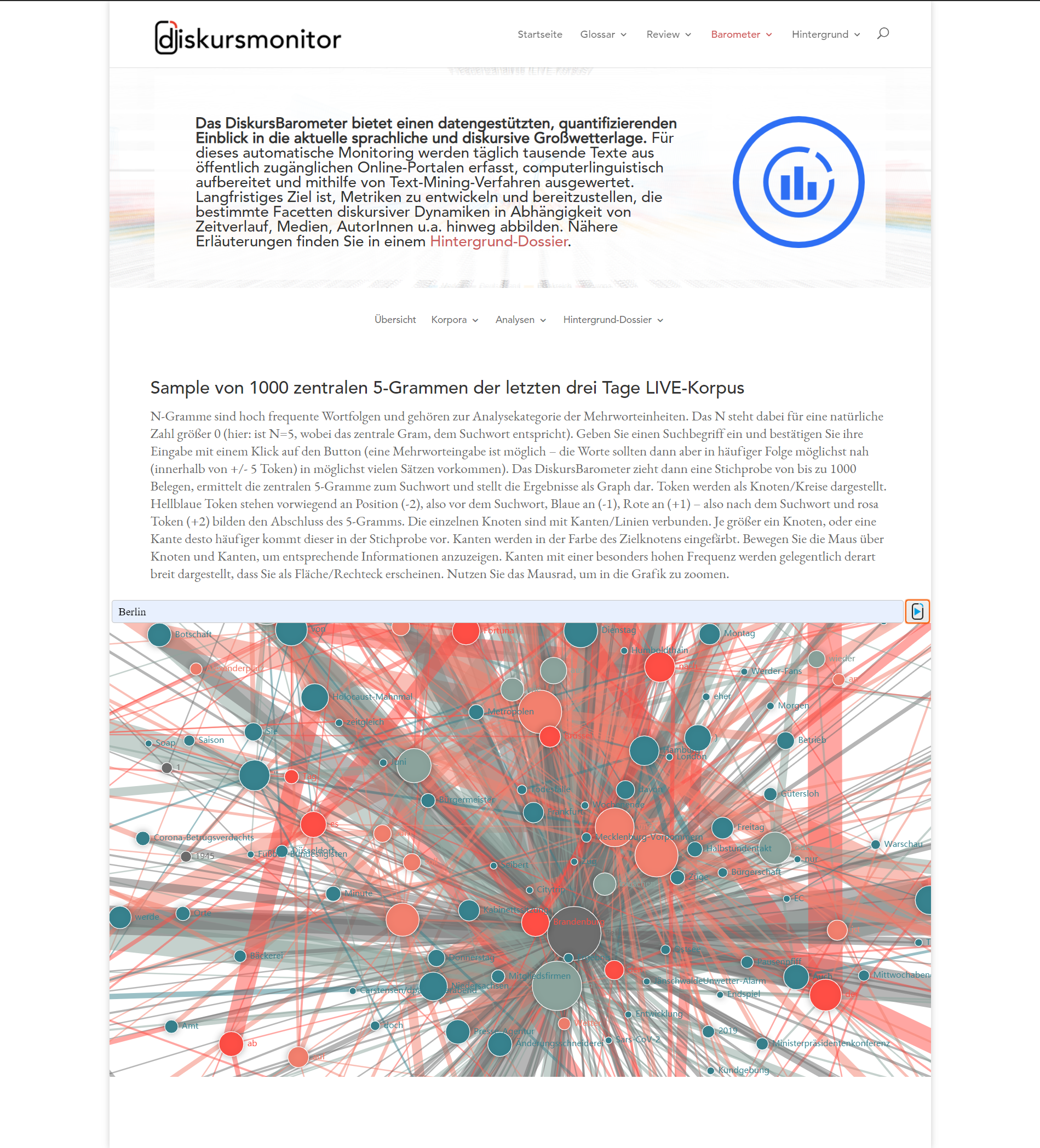
DiskursBarometer
Das DiskursBarometer ist ein Teilprojekt der Online-Plattform diskursmonitor.de („Der Diskursmonitor, eine gemeinschaftlich erarbeitete Online-Plattform zur Aufklärung und Dokumentation von strategischer Kommunikation.“). Das DiskursBarometer bietet einen datengestützten, quantifizierenden Einblick in die aktuelle sprachliche und diskursive Großwetterlage. Für dieses automatische Monitoring werden täglich tausende Texte aus öffentlich zugänglichen Online-Portalen erfasst (Zeitungen, Blogs, Webseiten, etc.), computerlinguistisch aufbereitet und mithilfe von Text-Mining-Verfahren ausgewertet (die Auswertung erfolgt mittels CorpusExplorer und einer eigens für das Projekt entwickelten Microservice Infrastruktur). Langfristiges Ziel ist, Metriken zu entwickeln und bereitzustellen, die bestimmte Facetten diskursiver Dynamiken in Abhängigkeit von Zeitverlauf, Medien, AutorInnen u. a. hinweg abbilden. Einen Einblick bietet die Projektwebseite:
[https://diskursmonitor.de/barometer/]
Nähere Erläuterungen finden Sie in einem Hintergrund-Dossier (inkl. einer Beschreibung der Microservice Architektur).



Siegener Social Media Data Lake (SSMDL)
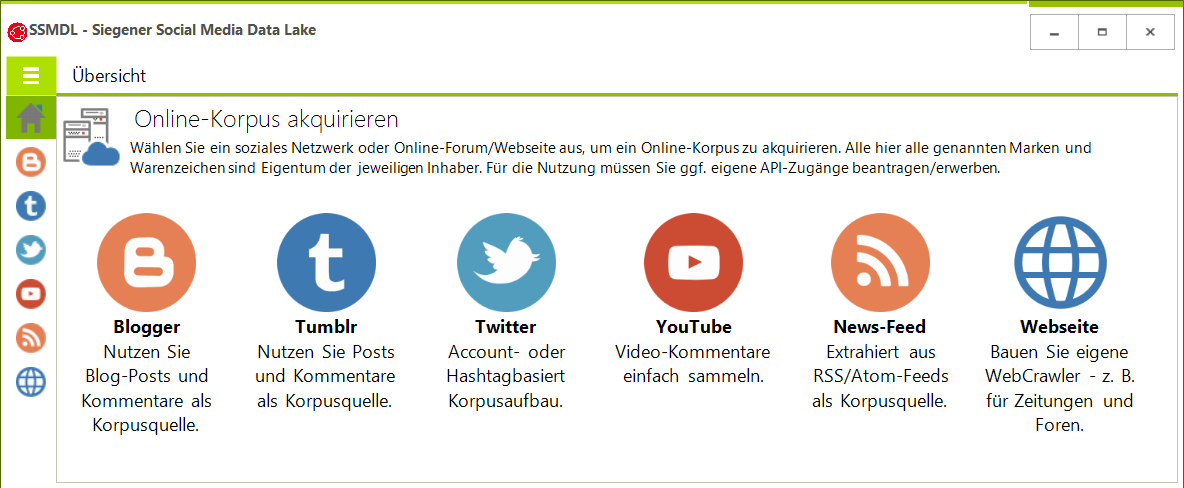
Die Erfassung von Daten aus ‚Sozialen Netzwerken‘ ist zunächst einfach. Da die Daten originär in maschinenlesbaren Formaten vorliegen. Zudem stellen viele Netzwerke sogenannte APIs bereit. Eine API kann von Entwickler*innen genutzt werden, um Daten zu sammeln und mit eigener Software auszuwerten. Dabei stellen sich zwei wichtige Hürden, die der SSMDL adressiert: (1) Ist für die Nutzung der APIs technisches Know-how notwendig, (2) sind die APIs uneinheitlich und müssen für jedes Netzwerk neu erlernt und programmiert werden.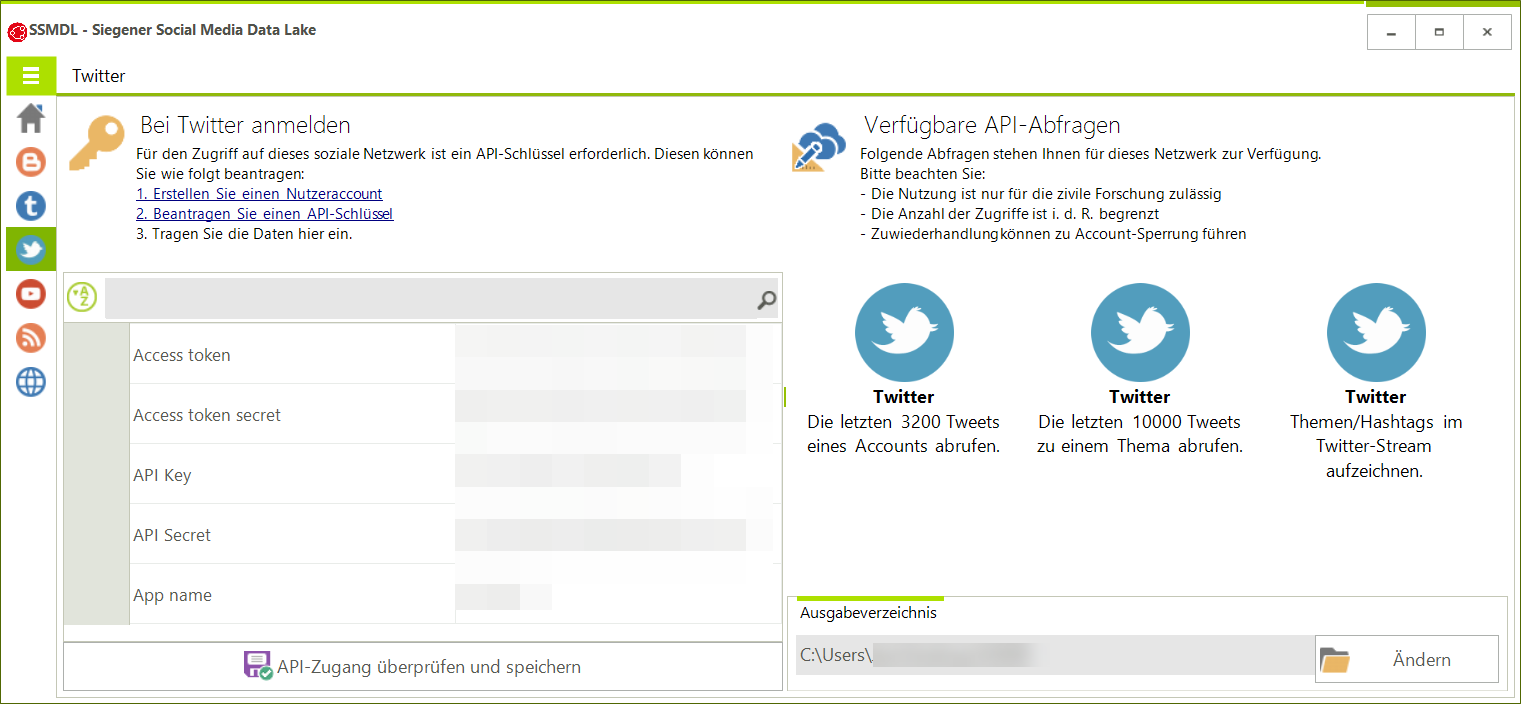
Der SSMDL bietet eine einfache und einheitliche Programmoberfläche für alle damit erfassbaren Netzwerke. Dadurch lassen sich die APIs ohne Programmierkenntnisse nutzen. Eine programmbegleitende interaktive Dokumentation unterstützt Nutzer*innen bei der Konfiguration. Aktuell stellt der SSMDL nur Zugriff auf wenige Netzwerke bereit – weitere Netzwerke sind geplant. Facebook und Instagram sind gegenwärtig nicht nutzbar (Facebook hat nach dem Datenskandal um #CambridgeAnalytica als Konsequenz alle Zugriffe auf die relevanten APIs unterbunden – sobald der Zugang seitens Facebook freigegeben wurde, werden die Netzwerke im SSMDL reaktiviert). Das Programm befindet sich aktuell in einem offenen Beta-Test, es kann daher noch einige Fehler enthalten. [Download]
VideoPlausch (Plauschi)
 Durch Corona entfallen viele Möglichkeiten für einen kleinen zufälligen Plausch. Zum Beispiel eine Einführungsveranstaltung für Erstsemester – normalerweise würde man sich aufgeregt in den Vorlesungssaal setzen und sich links und rechts mit seinen Sitznachbarn austauschen (vor, während oder nach der Vorlesung). Diese Software simuliert genau diese Art von unkonventioneller Kommunikation und ist dabei fast so niederschwellig zu nutzen, wie ein Plausch im realen Leben. Die Software kann (kosten-)frei genutzt werden (OpenSource) und ist mit verschiedenen Online-Video-Diensten kompatibel (siehe Dokumentation).
Durch Corona entfallen viele Möglichkeiten für einen kleinen zufälligen Plausch. Zum Beispiel eine Einführungsveranstaltung für Erstsemester – normalerweise würde man sich aufgeregt in den Vorlesungssaal setzen und sich links und rechts mit seinen Sitznachbarn austauschen (vor, während oder nach der Vorlesung). Diese Software simuliert genau diese Art von unkonventioneller Kommunikation und ist dabei fast so niederschwellig zu nutzen, wie ein Plausch im realen Leben. Die Software kann (kosten-)frei genutzt werden (OpenSource) und ist mit verschiedenen Online-Video-Diensten kompatibel (siehe Dokumentation).
[Download & weitere Informationen finden Sie hier]
 KAMOKO-Digitalizer
KAMOKO-Digitalizer

Dieser Editor wurde speziell für die Bedürfnisse des KAMOKO-Projekts (s.u.) entwickelt. Der Editor erlaubt die schnelle Erfassung von Beispielsätzen und Satzvarianten sowie die dazugehörigen Sprecherbewertungen. KAMOKO ist eine strukturierte und kommentierte Sammlung von Textbeispielen zur französischen Sprache und Linguistik, die nahezu alle zentralen Strukturen der französischen Sprache aus linguistischer Sicht behandelt.
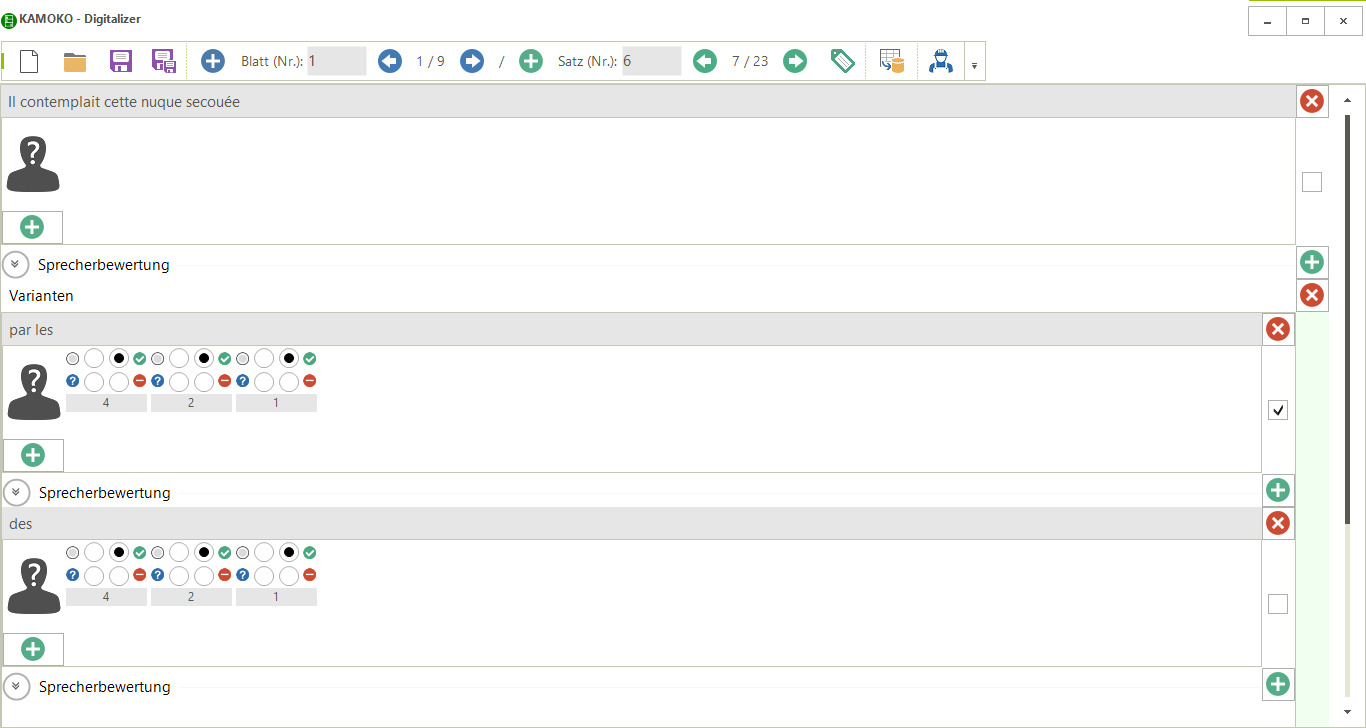
Derzeit wird das digitalisierte Korpus für die Nutzung über einen Online-Zugriff vorbereitet. Mithilfe des KAMOKO-Korpus können Studierende die Funktionen sprachlicher Formen in thematisch gegliederten Lehreinheiten für sich erschließen. Jede Einheit stellt ein sprachliches Phänomen (wie z. B. Tempus und Aspekt) anhand von Textbeispielen dar, die aufeinander aufbauen und zunehmend komplexere Verwendungen einer Form darstellen und erklären. Zentral ist dabei das Muster von Original und Variante, bei dem der Originaltext in unterschiedlicher Weise verändert wird. Die so entstandenen Varianten und neuen Lesarten illustrieren dann das funktionale Profil einer sprachlichen Form und deren Wirken in verschiedenen Kontexten. Auf diese Weise vermittelt KAMOKO in korpusbasierter Anschaulichkeit komplexe linguistische Inhalte.
[Download & weitere Informationen finden Sie hier]
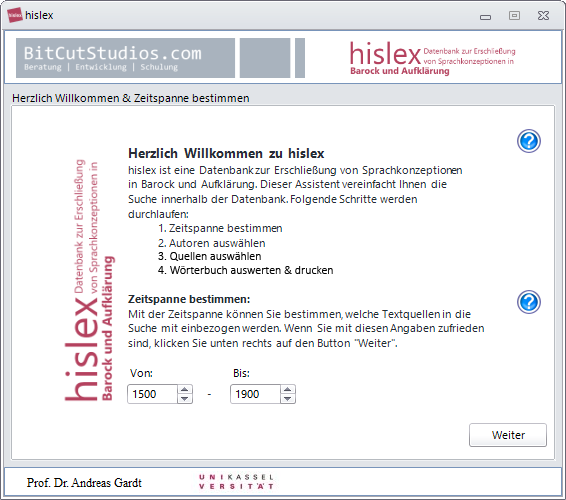
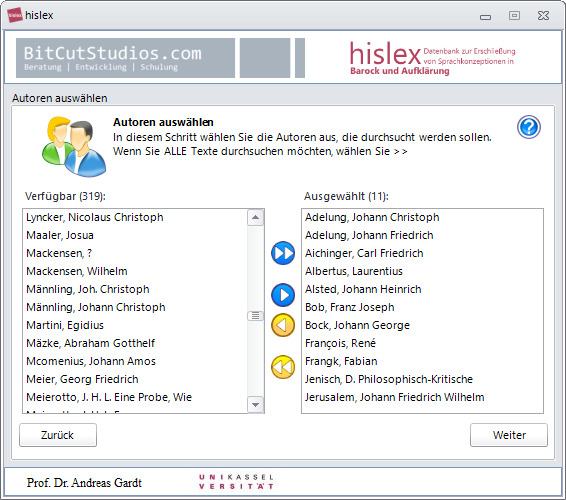
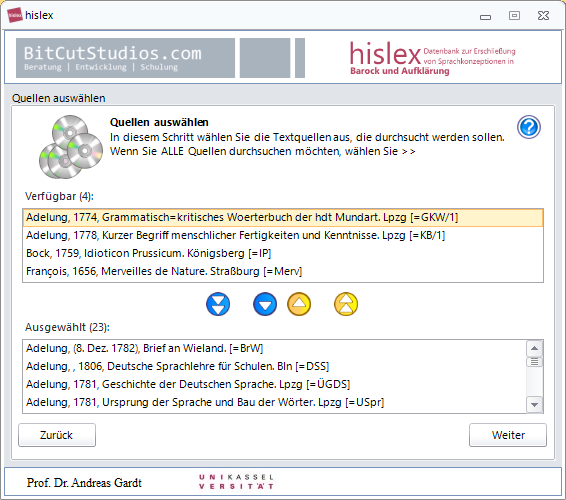
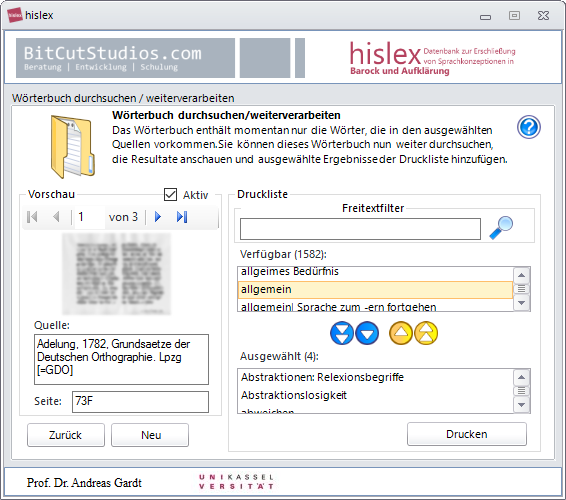
 HISLEX
HISLEX

Historisches Lexikon zur Erforschung von Sprachkonzeptionen in Barock und Aufklärung. Die Datenbank wurde in den 1990er Jahren entwickelt. Meine Aufgabe bestand darin, die alte und nicht mehr funktionstüchtige Datenbank wiederherzustellen. Die neue Datenbank basiert auf SQLite und ruft die Ergebniskarten von einem Server des ITS-Kassel (Hochschulrechenzentrum) ab. Die Datenbank ist nicht frei zugänglich, bei Interesse wenden Sie sich an den Auftraggeber Prof. Dr. Andreas Gardt. HISLEX wurde für die folgende Publikation eingesetzt:
Roelcke, Thorsten – Latein, Griechisch, Hebräisch. Studien und Dokumentationen zur deutschen Sprachreflexion in Barock und Aufklärung. Berlin, Boston: de Gruyter, 2014 (Studia Linguistica Germanica 119).
OpenSourceTelemetrie
OST ist eine Lösung (API + Serverkomponenten) für Softwareentwickler*innen und war die erste datenschutzfreundliche und komplett auf OpenSource basierende Telemetrie-Lösung (entwickelt seit 2017 – veröffentlicht 2019). Seit Ende 2019/Anfang 2020 gibt es in diesem Feld vermehrte Anstrengungen durch andere Projekte (vergl. hierzu https://opentelemetry.io). Was ist Telemetrie? – Telemetrie bedeutet soviel wie Fernmessung (Tele- = fern / -metrie = Messung). Die meisten modernen Computer- und Smartphone-Anwendungen nutzen Telemetrie. Anwendungen wie Windows 10, CandyCrush bis hin zu WhatsApp sammeln so genannte Nutzungsdaten. Solche Datenerhebungen sollte man mit Recht kritisch hinterfragen. Im besten Fall werden nur nutzerunabhängige Daten gesammelt. Wie z. B. Fehler-/Abstürze durch das Programm, oder welche Funktionen im Programm genutzt werden. Diese Daten sind wichtig für die Weiterentwicklung und Verbesserung der Anwendung. Im schlechtesten Fall werden aber auch personenbezogenen Daten erhoben oder mit den Anwendungsdaten verknüpft. Am Markt gibt es mehrere Lösungen für Entwickler*innen um Telemetrie-Daten zu erfassen – leider haben mit diesen Lösungen Entickler*innen nur bedingt Kontrolle über diese Daten (da die Daten oft auf den Servern der Lösungsanbieter wie Azure liegen). In diese Lücke stößt OST – eine einfache und leichtgewichtige WebService-Lösung, die auf jedem Webserver (Linux/Windows) installiert werden kann. Die Daten liegen damit immer nur auf dem Server der Entwickler*innen der jeweiligen App. Außerdem ist die API, in alle .NET Anwendungen integrierbar. Sowohl Server als auch API sind so konzipiert, dass sich nur personenunabhängige Daten erheben lassen. Der OpenSource Quellcode erlaubt zudem Transparenz und Nachvollziehbarkeit. [Weitere Infos zum Projekt und OpenSource Quellcode]

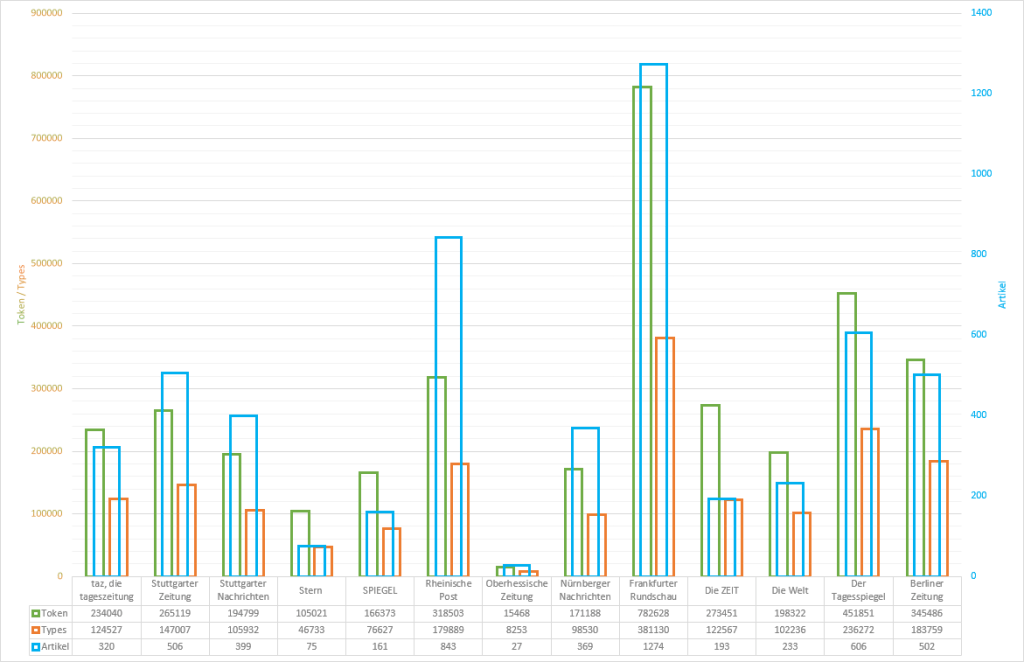
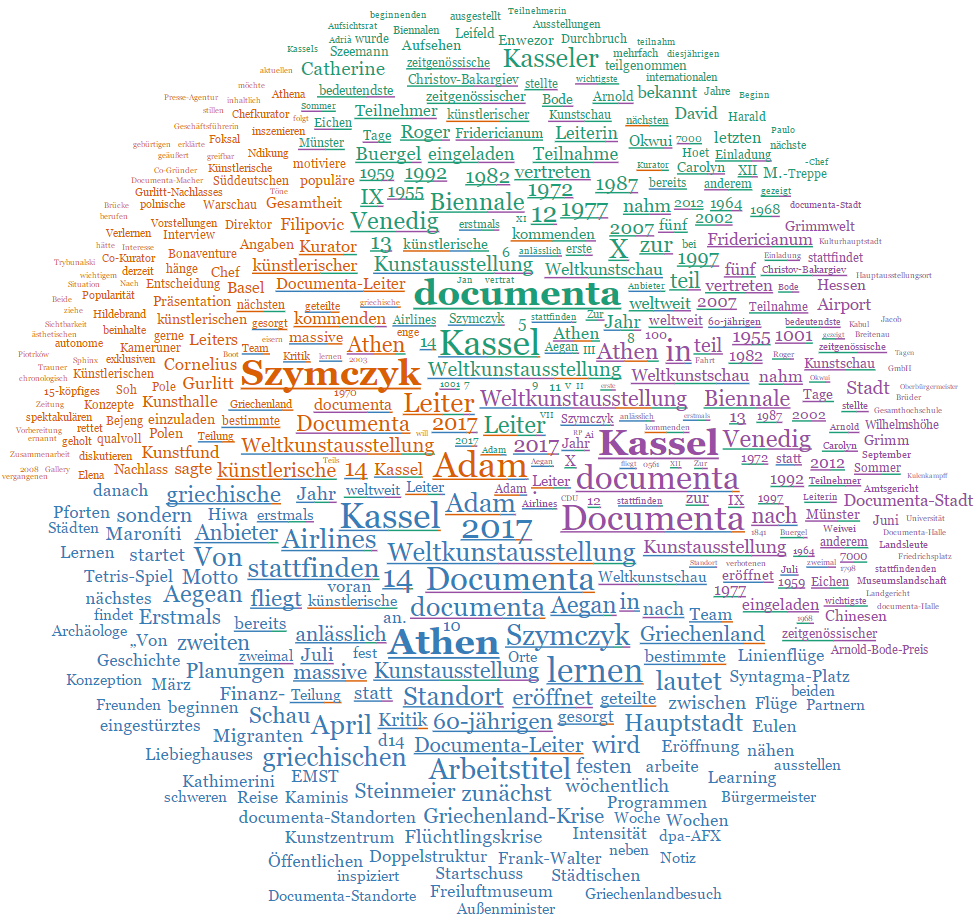

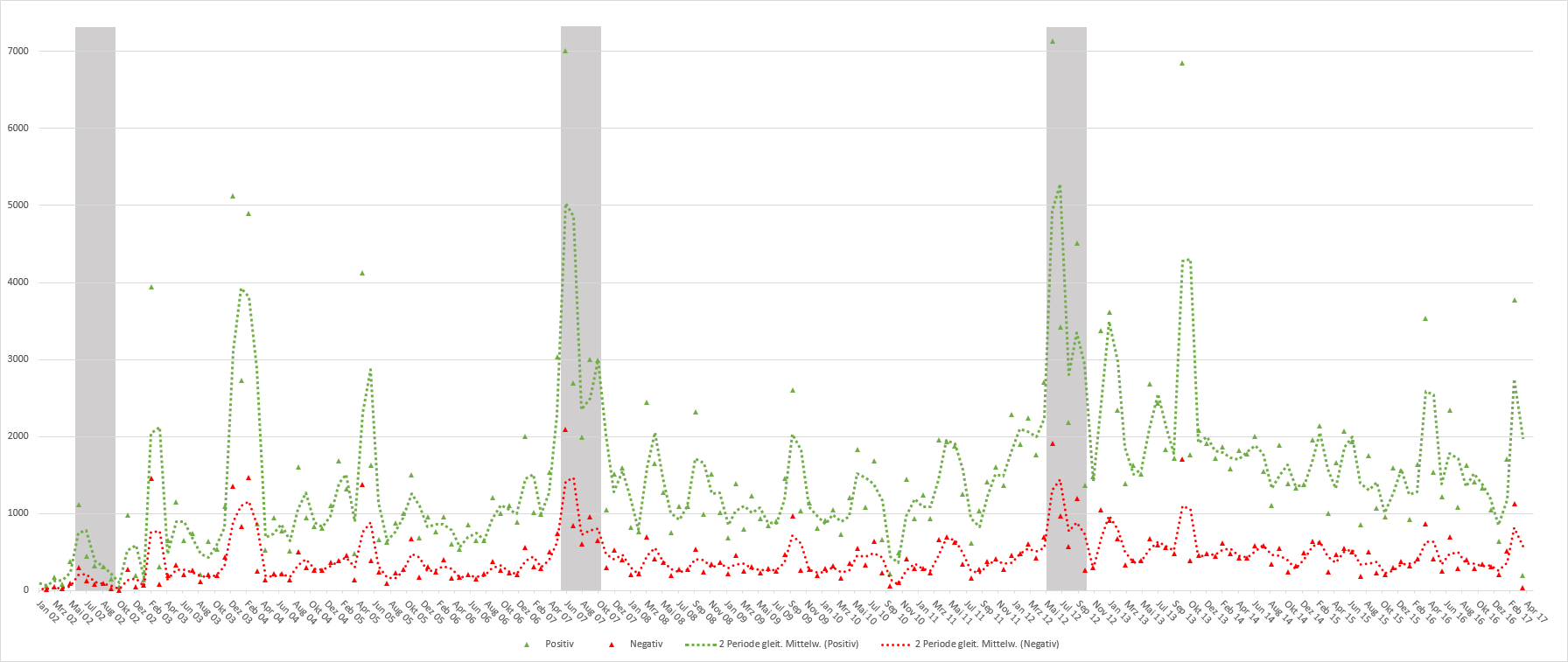
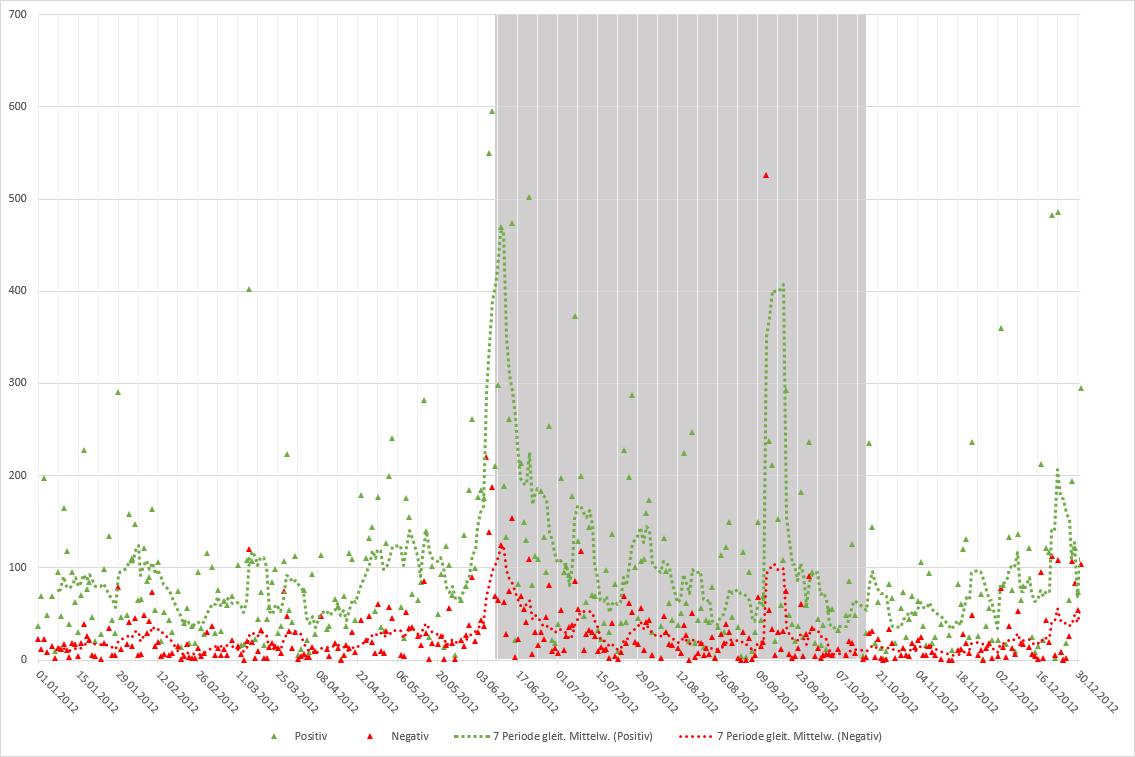
Reden über Kunst – d14 (Projektbeitrag: echtZEIT)
Als experimenteller Beitrag zum Projekt „Reden über Kunst – d14“ (Universität Kassel – Prof. Dr. Andreas Gardt) wurde eine Software (Arbeitstitel: echtZEIT) entwickelt, die Tweets weltweit in Echtzeit erfasst, aufbereitet und analysiert. Die Aufbereitung basiert im Kern auf dem CorpusExplorer (siehe oben). Erkenntnisse und Erfahrungen flossen in verschiedene Folgeprojekten ein (z. B. CorpusExplorer [siehe oben], Diskursmonitor [siehe oben] und SSMDL [siehe oben]). Im Projekt wurden die so erhobenen Korpora für verschiedene Auswertungen genutzt. Weitere Informationen finden Sie auf der Projekt-Seite.
Der Quellcode wurde unter https://github.com/notesjor/reden-ueber-kunst/ publiziert.
SiegenerXmlNarrator
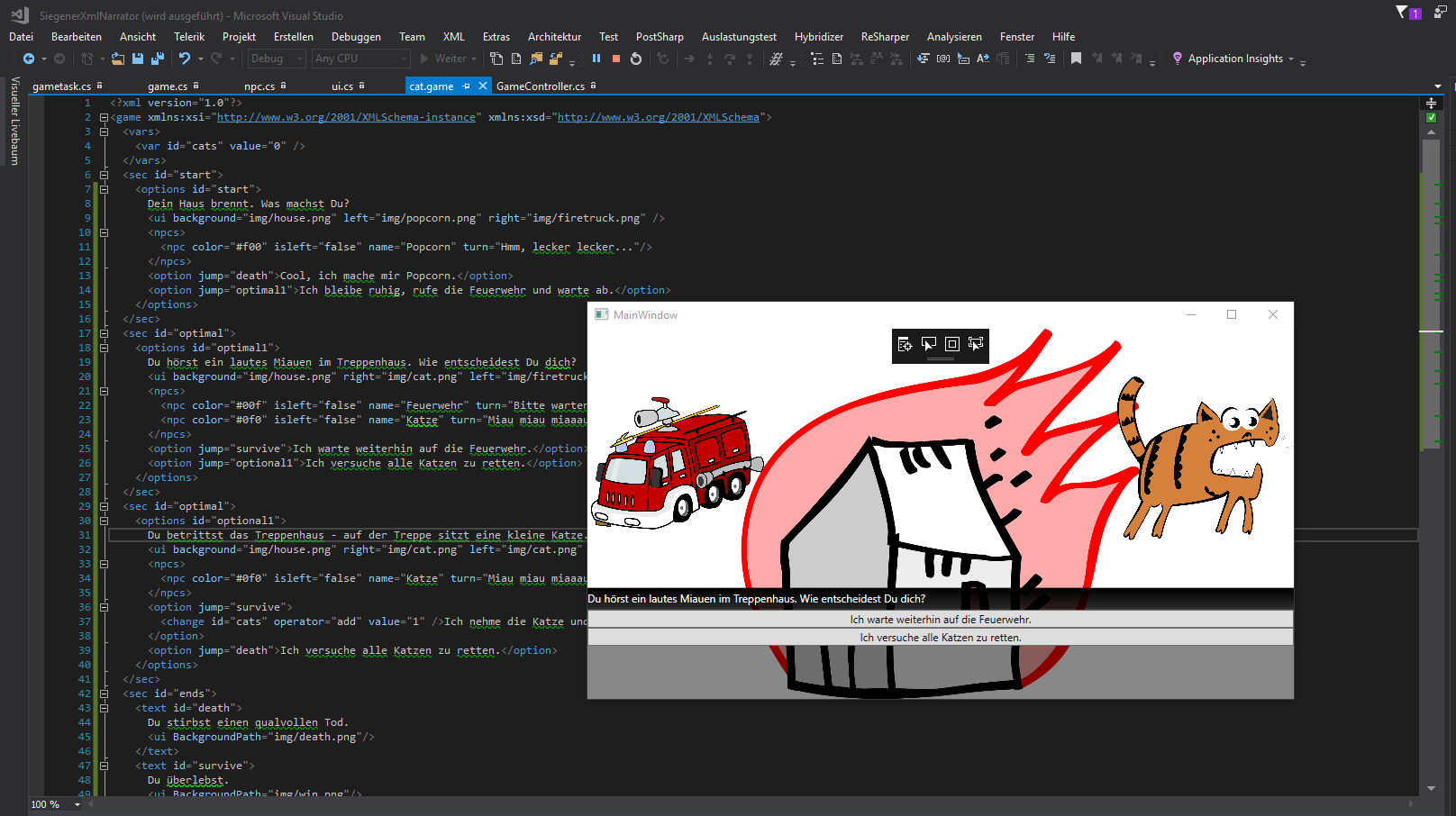 Editor/Betrachter für grafische Textadventures auf Basis von XML/XAML/C# – hervorgegangen aus dem Seminar „Programmieren für Linguist*innen“ (Universität Siegen – SomSe 2019).
Editor/Betrachter für grafische Textadventures auf Basis von XML/XAML/C# – hervorgegangen aus dem Seminar „Programmieren für Linguist*innen“ (Universität Siegen – SomSe 2019).
Im Rahmen des Seminar „Programmieren für Linguistinnen“ wurden mit den Studierenden das Programm SiegenerXmlNarrator entwickelt. Es basiert auf C#/WPF (d.h. die GUI ist in XAML einem XML-Dialekt geschrieben). Der Quellcode basiert auf C#. Das Programm liest eine Spieldatei ein (endet auf .game – beinhaltet Spielanweisungen in XML). Die Spielerin kann zwischen verschiedenen Optionen wählen. Dem Spiel liegt ein einfaches Beispiel inkl. OpenAccess-Grafiken bei.
 IWD – Fernstudium2.0
IWD – Fernstudium2.0

Von 2008 bis zur Auflösung des An-Instituts (2014) wurde die integrative Softwarelandschaft zur Teilnehmerverwaltung und E-Learning durch mich entwickelt und betreut. IWD steht hierbei für den Namen des An-Instituts (Institut zur Weiterbildung in Deutsch als Fremdsprache an der Universität Kassel). Die Hauptdatenbank diente der Teilnehmer*innen-Verwaltung. Dies umfasste auch Kurs-, Test- und Gutachterverwaltungen. Die zu Projektbeginn existierende Access-Datenbank wurde durch eine verteilte Datenbank (Server/Client-Struktur) abgelöst. Dadurch wurde das verteilte Arbeiten ermöglicht. Die Datenbank überwachte selbstständig Fristen und synchronisierte sich selbstständig mit der Lernplattform (moodle).
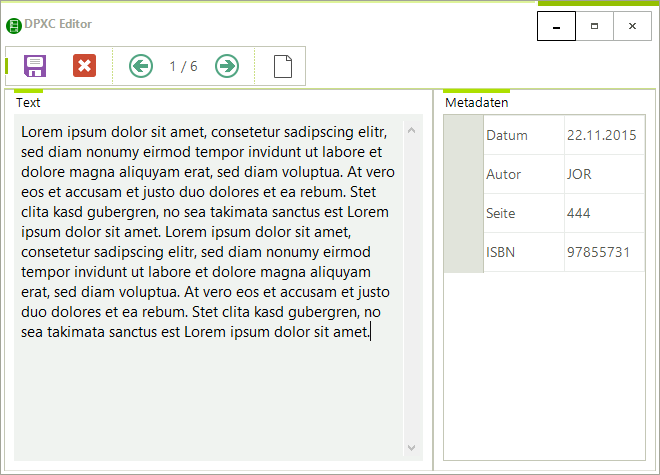
 DPXC
DPXC

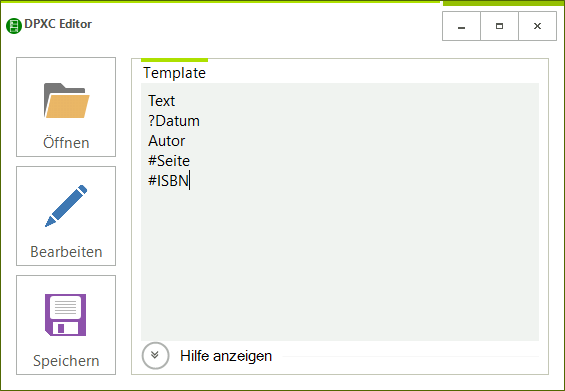
DPXC ist ein editorbasiertes Korpusformat für alle Unentschlossenen. Sie können ein Korpus erheben, ohne es bereits in ein endgültiges Datenkorsett pressen zu müssen. Dabei trennen Sie den Text von seinen Metadaten. Sie können jederzeit neue Metadaten korpusweit hinzufügen, löschen und natürlich alle Daten (Text-/Metadaten) über einen komfortablen Editor bearbeiten. Dieser Editor schützt Sie davor Fehler in das XML-Format einzubauen. Die Erfahrung zeigt, dass gerade derartige Fehler den Projektworkload immens erhöhen können. Für Metadaten gibt es aktuell drei Typen – Freitext, Zahl, Datum. DPXC-Dateien können Sie ganz leicht mit dem CorpusExplorer einlesen (Dokumente annotieren > DPXC wählen > fertig). Der CorpusExplorer annotiert die Textdaten automatisch. Sinnvollerweise verändert der CorpusExplorer die DPXC-Eingabedatei NICHT, daher können Sie später weitere Daten hinzufügen, entfernen oder löschen. Seien Sie einfach mal unentschlossen! – Wenn Ihr Projekt zu einem späteren Zeitpunkt konkretere Züge angenommen hat, können Sie oder externe Entwickler die DPXC-Datei in jedes beliebige XML-Format konvertieren. [Downloads & weitere Informationen finden Sie hier.]
 Video-Re-Tone
Video-Re-Tone

Wurde im Auftrag für Prof. Dr. Iris Kruse entwickelt. Die Funktion ist sehr simpel, ein beliebiges Video wird abgespielt, jedoch ohne Ton. Dafür wird parallel zum Video der Mikrofoneingang aufgezeichnet. Das Programm sollte zur Stärkung der narrativen Kompetenzen bei Grundschulkindern eingesetzt werden – Kinder erzählen, was Sie sehen oder versuchen den Figuren eine Stimme zu geben.