2018-11-14 | CorpusExplorer, InAppNote
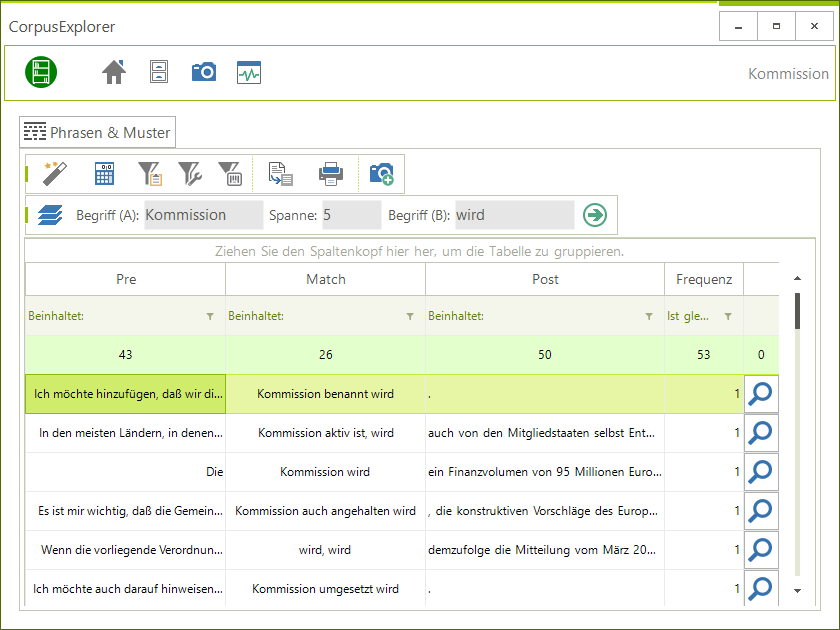
Auf einem Workshop in Würzburg (2018-11-09) baten mich mehrere Teilnehmer*innen, dass ich Reguläre Ausdrücke (Regular Expression – kurz RegEx) im CorpusExplorer ermöglichen soll. Bisher habe ich RegEx vermieden – oder zumindest in der Oberfläche gut...
2017-11-13 | CorpusExplorer
So langsam gewöhnt sich der CorpusExplorer an einen dreimonatigen Update-Zyklus. Über einige ausgewählte Funktionen wird es in den kommenden Tagen noch zusätzliche Blog-Beiträge geben. Neue Funktionen: Unterstützung von anderen Encodings/Codepages als UTF-8. Dies kann...
2016-11-09 | CorpusExplorer
Das DTA-Kernkorpus ist ab jetzt als Korpus-Addon verfügbar. Für Sie heißt das: Einfache Installation, bereits analysefertiges Material, Updates erfolgen vollautomatisch. Das DTA-Korpus-Addon können Sie hier herunterladen: [Download]. Weitere Informationen zum Addon...
2016-11-05 | CorpusExplorer
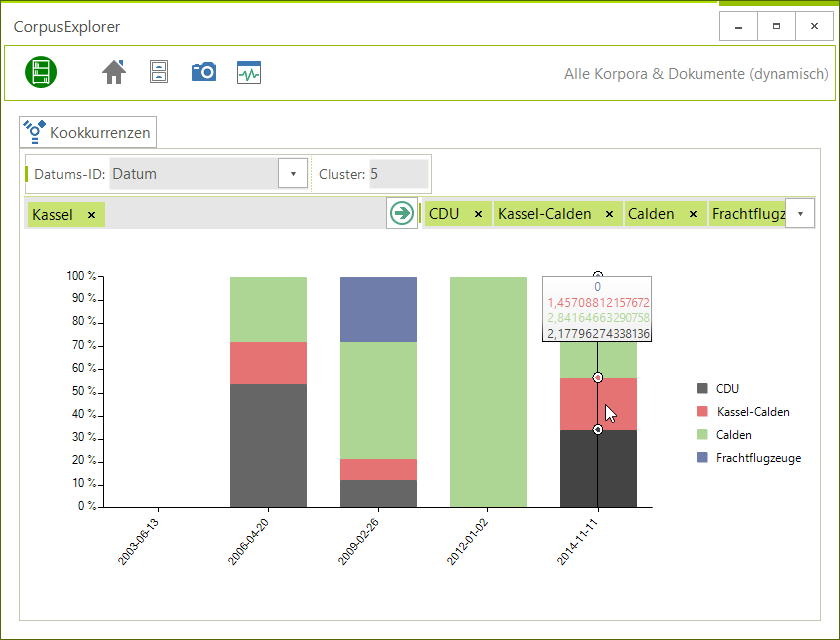
Das November Update bringt viele neue Funktionen für Freunde von Zeitreihenanalysen. Neuerungen / Verbesserungen : Frequenzanalyse > Zeitliche Verteilung – Bisher war diese Funktion unter den Spezialfunktionen zu finden. Jetzt hat diese Analyseform endlich den...