TED – Was wir von 5 Millionen Büchern gelernt haben
Ein Vortrag über den „Google Labs NGram Viewer“ – Datenbasis ist „Google Books“ mit ca. 5 Mio....Beispielübung und Lösung
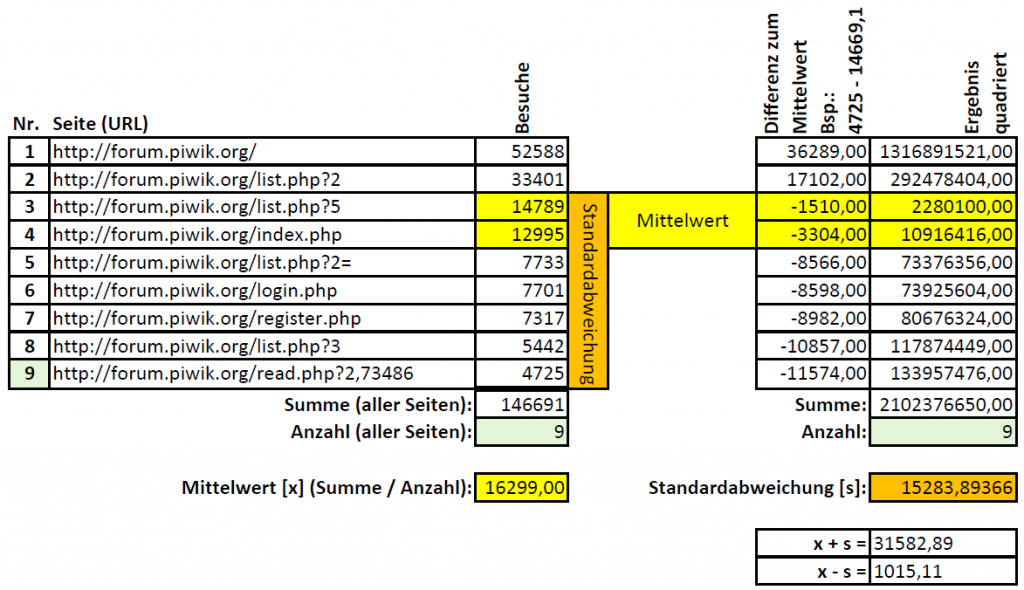
Beispielübung Loesung für BeispielübungStatistik: Idee für einen Grundsatz
Nach welchen Dingen suchen wir überhaupt? – Grundsätzlich gibt es zwei Dinge, die interessieren, die Regel und die Ausnahme. Regel: Wir möchten wissen wie ein Text (Oberflächen-/Tiefenstruktur) oder sogar ein ganzer Diskurs zusammenh ängt – hier...TED – Erin McKean definiert das Wörterbuch neu
Auuuu! – Wer dachte Lexikografie sei laaangweilig, wird hier eines besseren belehrt. Aber VORSICHT, dieser Vortrag ist sehr amerikanisch (Tinnitus-Gefahr). Dafür ist der Vortrag ein sehr buntes Plädoyer gegen eine normative...Geschützt: Exzerpt: „Sprachgebrauchsmuster: Korpuslinguistik als Methode der Diskurs- und Kulturanalyse“
Passwortgeschützt
Um dieses geschützten Beitrag anzusehen, unten das Passwort eingeben.: