2019-08-26 | CorpusExplorer, InAppNote
Das Q3 2019 Update des CorpusExplorers bringt folgende Neuerungen und Verbesserungen: Neue Funktionen: Neue Formate: FoLiA XML RSS Feeds Speedy (Import/Export) – Danke an/Thanks to: Iian Neill & Andreas Kuczera YouTube JSON Wiktionary Redewiedergabe –...
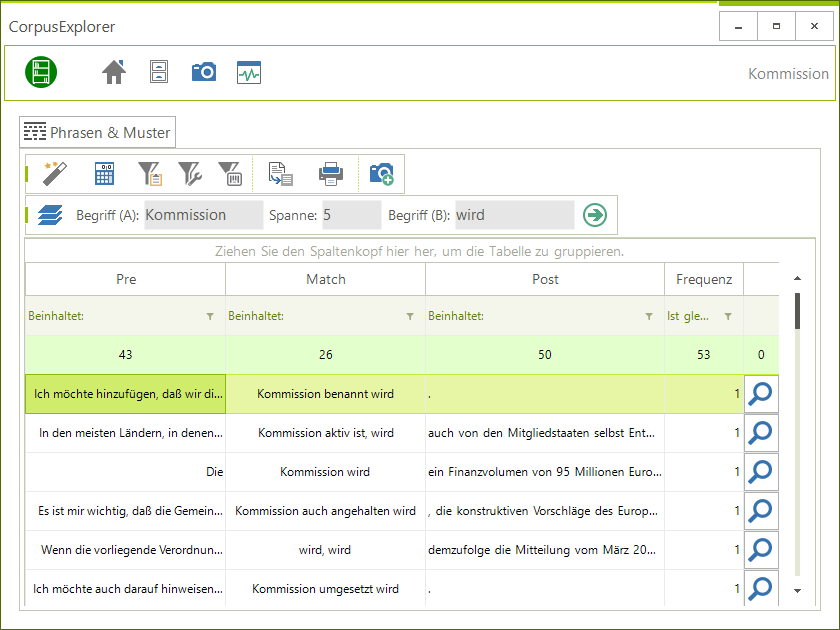
2018-11-14 | CorpusExplorer, InAppNote
Auf einem Workshop in Würzburg (2018-11-09) baten mich mehrere Teilnehmer*innen, dass ich Reguläre Ausdrücke (Regular Expression – kurz RegEx) im CorpusExplorer ermöglichen soll. Bisher habe ich RegEx vermieden – oder zumindest in der Oberfläche gut...