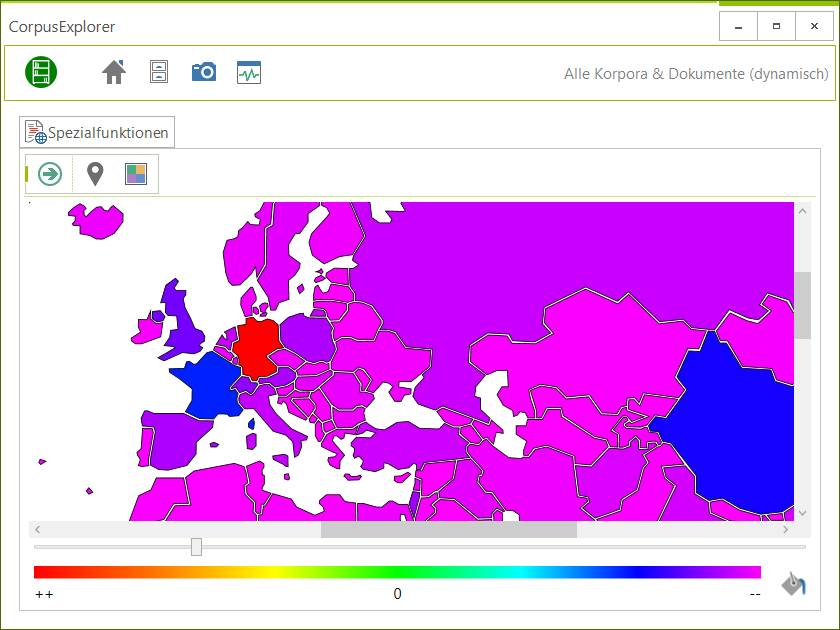
2018-06-25 | CorpusExplorer
Das Update für Juni/Juli 2018 bringt folgende Neuerungen und Verbesserungen mit sich: Sentiment-Detection: Unter den Spezialfunktionen gibt es jetzt das neue Analysemodul „Sentiment Detection“. Damit lassen sich vordefinierte SD-Wörterbücher auf ein(en)...
2017-11-13 | CorpusExplorer
So langsam gewöhnt sich der CorpusExplorer an einen dreimonatigen Update-Zyklus. Über einige ausgewählte Funktionen wird es in den kommenden Tagen noch zusätzliche Blog-Beiträge geben. Neue Funktionen: Unterstützung von anderen Encodings/Codepages als UTF-8. Dies kann...