2019-05-25 | CorpusExplorer, InAppNote
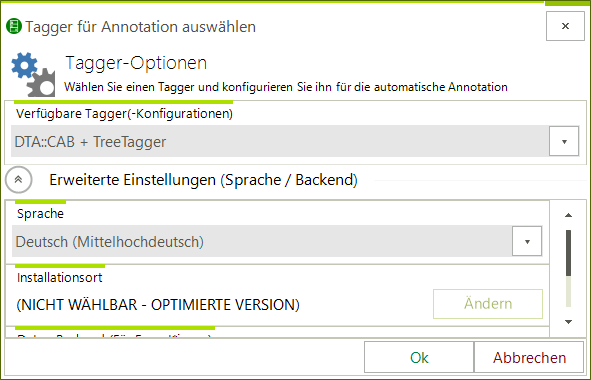
DTA::CAB ist ein orthographischer Normalisierer für historische Sprachstufen des Deutschen (entwickelt von Bryan Jurish, Zentrum für digitale Lexikographie, Berlin-Brandenburgische Akademie der Wissenschaften). Mit diesem Add-on können Sie frühneuhochdeutsche und...
2016-11-09 | CorpusExplorer
Das DTA-Kernkorpus ist ab jetzt als Korpus-Addon verfügbar. Für Sie heißt das: Einfache Installation, bereits analysefertiges Material, Updates erfolgen vollautomatisch. Das DTA-Korpus-Addon können Sie hier herunterladen: [Download]. Weitere Informationen zum Addon...