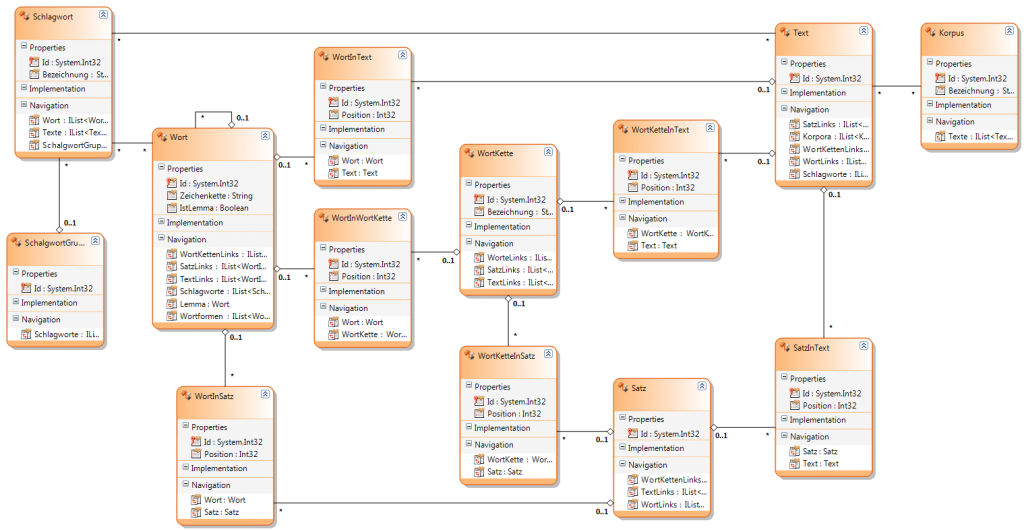
In der Literatur tauchen immer wieder Datenbanken (DB) und Datenformate (wie z.B. XML) auf, die in der Regel für spezielle Aufgaben zugeschnitten sind. Mach mehreren Versuchen diese Datenquellen zu vereinfachen, bin ich zu folgendem Vorschlag gekommen.
Anmerkung (25.07.2012): Das System funktioniert leider nicht so wie gewünscht.
Das es ein gigantisches Ausmaß annimt, Wort/Satz-Positionen zu speichern hätte ich anfangs nie gedacht. Beispiel: „Faust – I“ ist als Plaintext ca. 190 KB groß. Nach dem Parsing/Tagging mit TreeTagger fast die Datei ca. 780 KB. Werden die Daten mit meinem Lieblings OR-Mapper in eine Datenbank (nach folgendem Schema) eingetragen fasst die Datenbank ca. 9000 KB. Nach diversen Optimierungen konnte die DB-Größe auf ca. 5300 KB reduziert werden. Das ist immer noch zuviel. 5300 / 190 = Faktor 27,8.
Bei größeren Textmengen (z. B. Projekt-Gutenberg 4GB * 27,8 = 111,2GB) ist neben dem Datenvolumen auch die Verarbeitungszeit zu langwierig. Ich werde daher nach einer alternativen Lösung suchen müssen.
