Alle Nutzer*innen des CorpusExplorers wünsche ich ein frohes, gesundes und erfolgreiches Jahr 2022. Der CorpusExplorer startet dieses Jahr früh mit dem ersten Quartals-Release Q1-2022. Es gibt einige spannende Neuerungen und viele weitere sind für 2022 bereits in Arbeit.
Neuerungen:
- Zusätzliche Annotationen
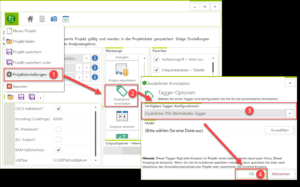
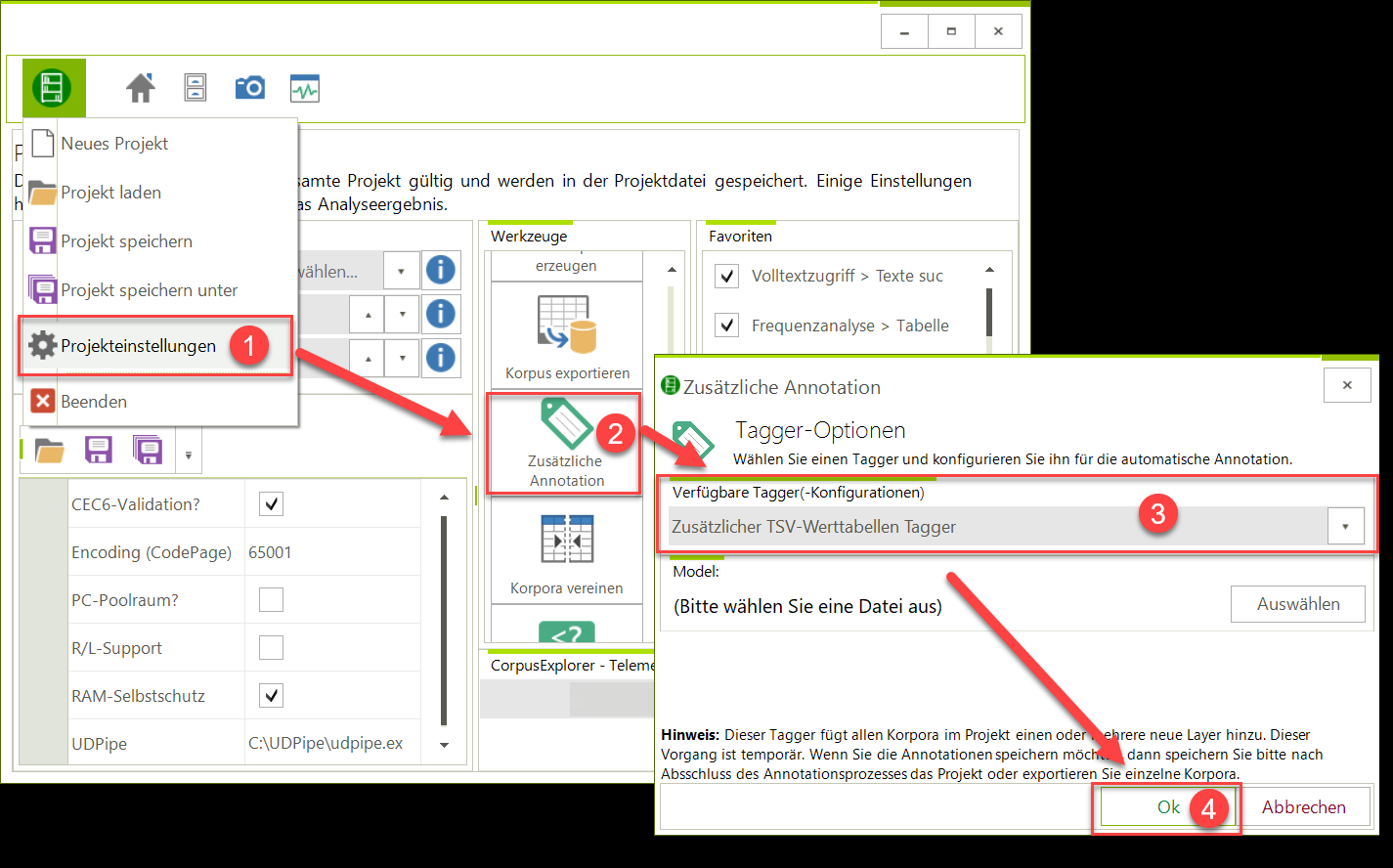
Unter „Projekteinstellungen“ gibt es schon länger das Tool „Zusätzliche Annotationen“. Bisher war diese Funktion nur für zusätzliche wertbasierte Annotationen gedacht. Ab jetzt können alle installierten Tagger/Sprachen genutzt werden. Dies erlaubt es z. B. ein Korpus parallel mit dem TreeTagger und dem RFTagger zu annotieren.
- Neue Im-/Exporter:
- Importer für „IMS Open Corpus Workbench (CWB)“
- Importer und Exporter für „OPUS Corpus Collection“ https://opus.nlpl.eu/
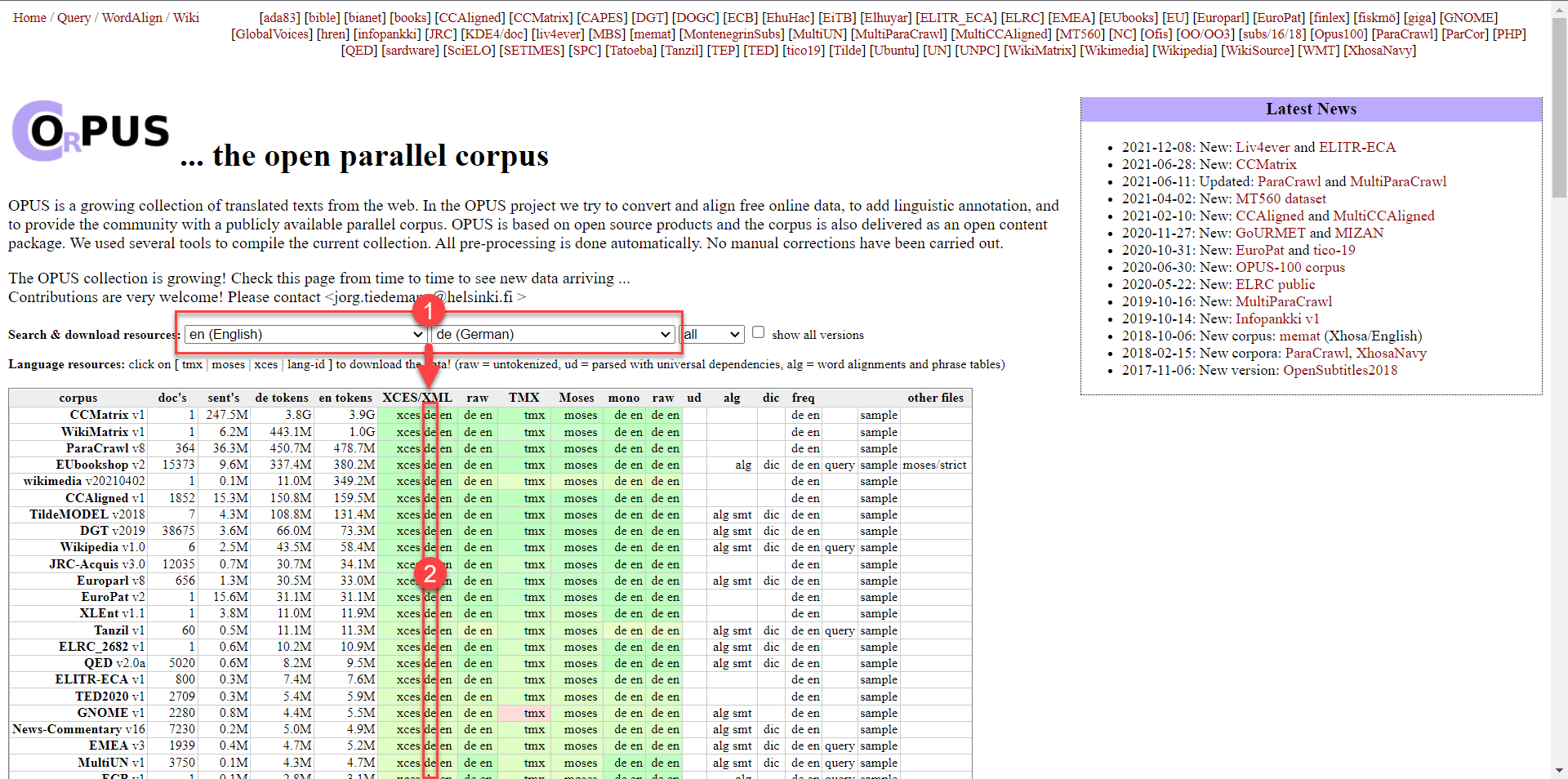
So laden Sie Korpora für den Importer von https://opus.nlpl.eu/ herunter:
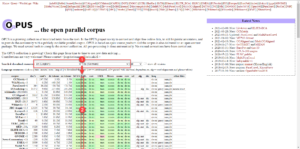
- Wählen Sie zunächst ein Sprachenpaar aus. z. B. Englisch und Deutsch. Es erscheint eine Download-Tabelle mit verschiedenen Formaten.
- Klicken Sie dann in der Spalte „XCES/XML“ auf die gewünschte Sprache (bitte nicht auf XCES klicken – dies ist ein anderes Format.).
- Entpacken Sie die ZIP-Datei und laden Sie die Dateien über „Korpus importieren“.
Verbesserungen:
- KWIT (Keyword in Tree)
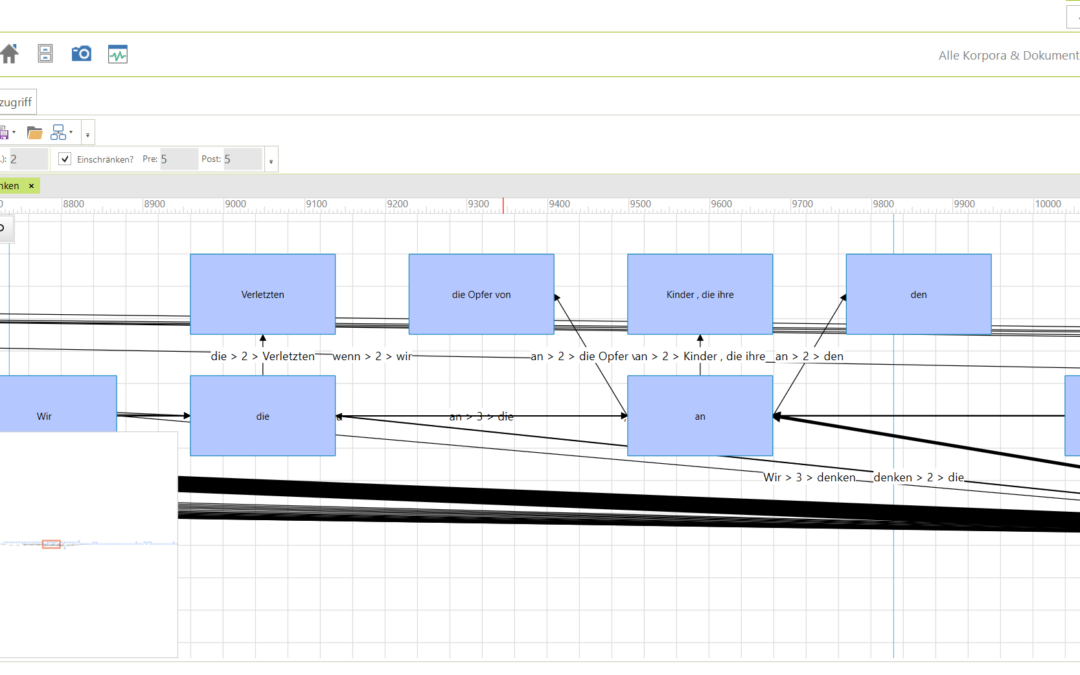
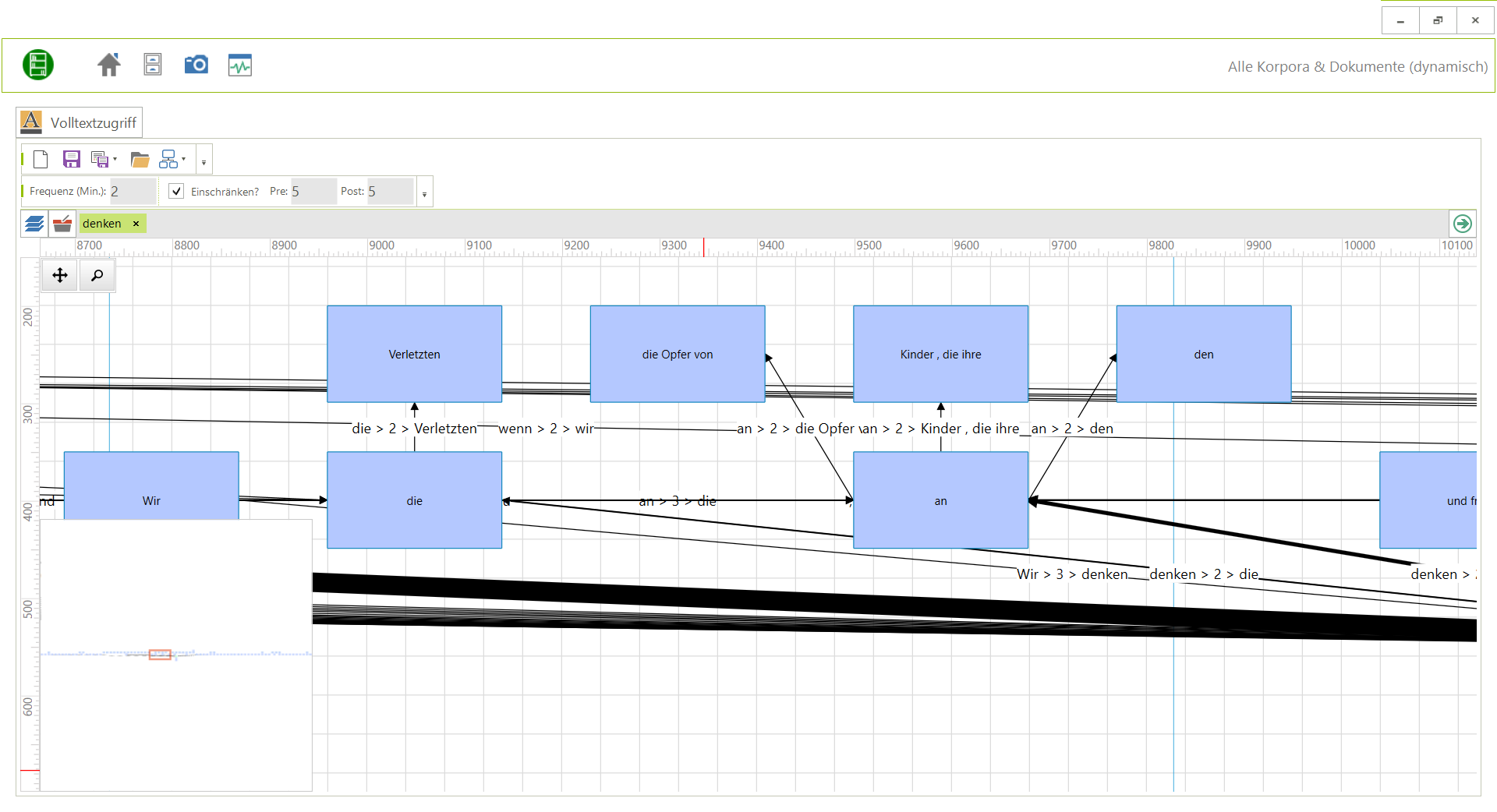
Bisher war eine einfache Analyse mittels KWIT mit viel Wartezeit verbunden. Dies lag unter anderem daran, dass auch einmalige Sätze in die Analyse mit aufgenommen wurden und das komplette Sätze verarbeitet wurden. Dies ist aber in den meisten Fällen nicht nötig. Daher wurde ein Einschränkungsfilter entwickelt. Unter „Frequenz (Min.)“ ist jetzt eine Mindesfrequenz von 2 voreingestellt – d. h. werden einmalige Belege nicht berücksichtigt (Sie können den Wert aber auf 1 herabsetzen, um alle Belege einzubeziehen – Achtung: länger Wartezeiten). Außerdem gibt es die Option „Einschränken?“ – damit wird nur um das Suchwort herum gesucht – die Standardeinstellung 5 Token davor (pre) und 5 Token danach (post). Entfernen Sie den Haken bei „Einschränken?“, um die Einschränkung vollständig aufzuheben. Wenn Sie z. B. ‚devor/pre‘ auf 0 setzen, werden keine Token vor dem Suchwort betrachtet.
Analyse in einem Korpus zu Reden verschiedener Bundespräsidenten. Gesucht nach: „denken“
- Verbesserter Export für „IMS Open Corpus Workbench (CWB)“
- Allgemeine Verbesserungen und Korrekturen
- Vorbereitung für eine Übersetzung des CorpusExplorers laufen.
CorpusExplorerConsole GUI (CEC-UI)
Die GUI für die Erstellung von Skripten zur Automatisierung des CorpusExplorer wurde verbessert. Das erzeugte XML konnte u. U. kodierte Zeichen enthalten, die für Menschen schwer lesbar sind. Kleiner UI-Fehler wurde korrigiert.
WebConverter (webbasierter Konverter für linguistische Korpusformate):
Der WebConverter wird jetzt schon eine Zeit lang von mir als Nebenprojekt entwickelt. Mit ihm lassen sich verschiedene linguistische Korpusformate ineinander konvertieren. Der WebConverter ist unter https://convert.corpusexplorer.de/ erreichbar. Mit diesem Release wird der WebConverter in die Releaseplanung mit aufgenommen. Zukünftige CorpusExplorer-Releases, die neue Import/Export-Formate beinhalten, führen damit automatisch zu einer neuer WebConverter-Version.