Auf einem Workshop in Würzburg (2018-11-09) baten mich mehrere Teilnehmer*innen, dass ich Reguläre Ausdrücke (Regular Expression – kurz RegEx) im CorpusExplorer ermöglichen soll. Bisher habe ich RegEx vermieden – oder zumindest in der Oberfläche gut versteckt. Auch weiterhin halte ich diese hässlichen RegEx-Dinger, die mehr an Marsianisch oder Klingonisch erinnern, als an eine Abfragesprache, für überflüssig und hinderlich, wenn es um die Gestaltung einer grafischen Benutzerschnittstelle geht (als Programmierer weiß ich natürlich den Vorteil von RegEx zu schätzen – hier sei nur auf meinen Favoriten „<[^>]*>“ verwiesen, der sämtliche XML-Tags aus einer Datei entfernen kann).
Es gibt aber zwei Argumente die ich für überzeugend halte:
- Es gibt viel existierendes Wissen zu Regulären Ausdrücken – meist in Form mühsam zusammengeklöppelter Abfragen auf Schmierzetteln (ist bei mir nicht anders). Dieses Wissen will man natürlich weiterhin nutzen.
- Bei einigen Abfragen, z. B. bei der Suche nach verschiedenen Wortformen können RegEx der/dem Eingeweihten helfen, schneller ans Ziel zu kommen.
Daher führt dieses Update folgende neue Funktionen ein:
- RegEx für die Erstellung von Schnappschüssen. Mit und ohne Satzgrenzenerkennung.
- RegEx für alle Tabellen-Analysen, zum schnellen Suchen von Werten.
Zusätzlich gibt es folgende neue Funktionen / Verbesserungen:
- Neue Analyse unter „Phrasen & Muster“ > „CutOff-Phrasen“.
Hierbei lässt sich nach Phrasen suchen, die zwischen zwei Begriffen stehen. Eine maximale Spanne kann angegeben werden.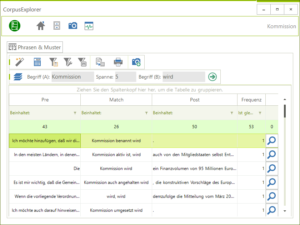
Neue Analyse: CutOff-Phrasen
- Das Problem mit hochauflösenden Bildschirmen kurz HighDPI tauchte leider wieder auf. Für diese Bildschirme wurden neue Korrekturen eingeführt.
- Die Ikonografie für Filter wurde vereinheitlicht / Die Icons auf der Korpusübersichtsseite wurden aufgehübscht.