Das Update für Juni/Juli 2018 bringt folgende Neuerungen und Verbesserungen mit sich:
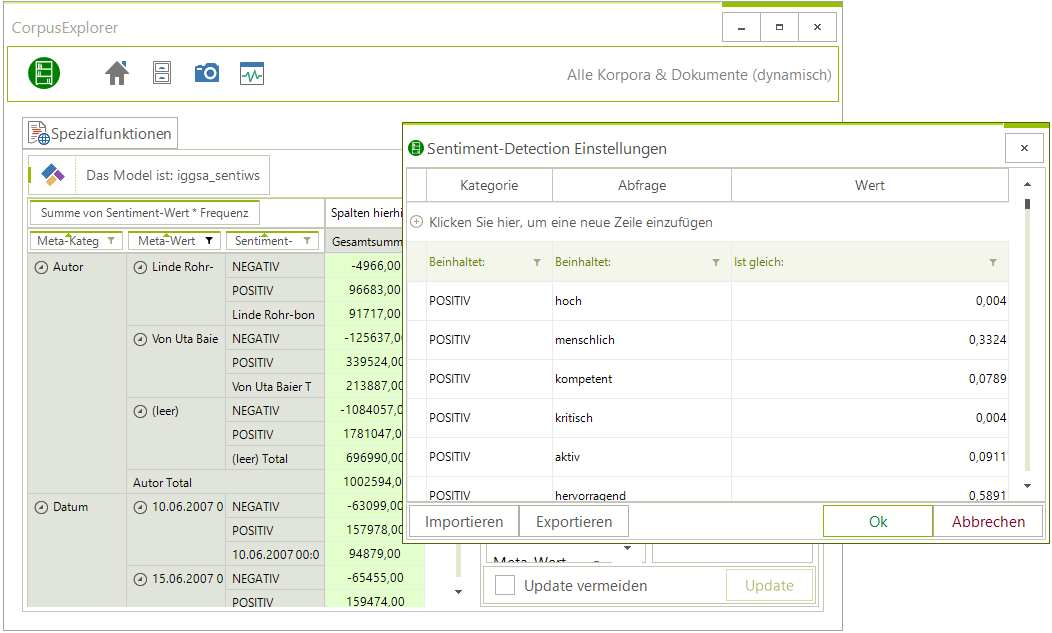
- Sentiment-Detection: Unter den Spezialfunktionen gibt es jetzt das neue Analysemodul „Sentiment Detection“. Damit lassen sich vordefinierte SD-Wörterbücher auf ein(en) Korpus/Schnappschuss anwenden. Eine Besonderheit: Wenn Sie die Analyse starten, können Sie entweder aus einem vorgefertigten Modell wählen, dieses manuell ändern oder ein eigenes Modell laden.
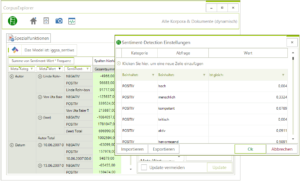
Neu: Sentiment-Detection
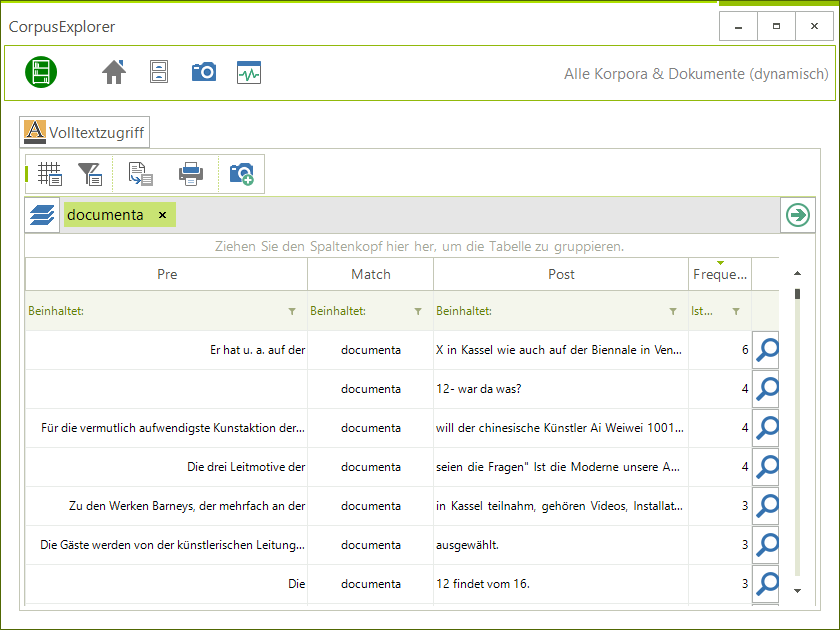
- KWIC Ansicht überarbeitet: Bisher war die KWIC-Ansicht (Volltextzugriff > Texte suchen (KWIC)) sehr umständlich zu bedienen. Man musste einzelne Ergebnisse nach erfolgreicher Suche manuell anwählen. Die neu überarbeitete KWIC Ansicht nutzt die bereits vielfach bewährte Tabellenansicht zur Darstellung von KWIC-Resultaten.
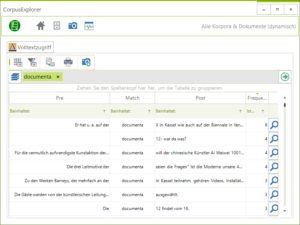
Überarbeitet: KWIC
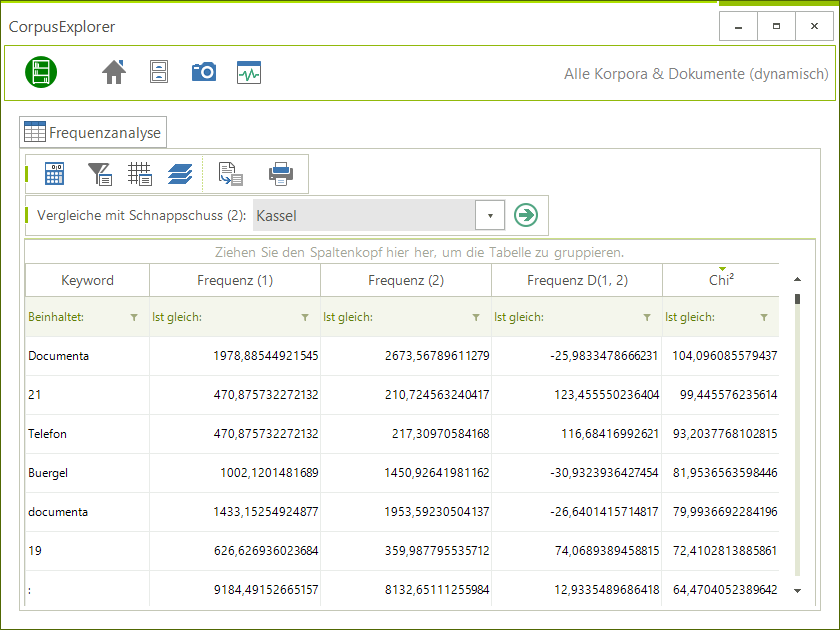
- Keyword-Analyse überarbeitet: Die Keyword-Analyse wurde überarbeitet und bietet jetzt mehr Daten.
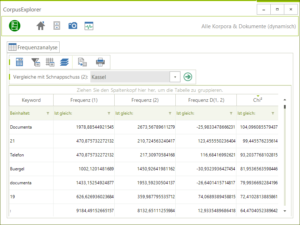
Überarbeitet: Keyword-Analyse
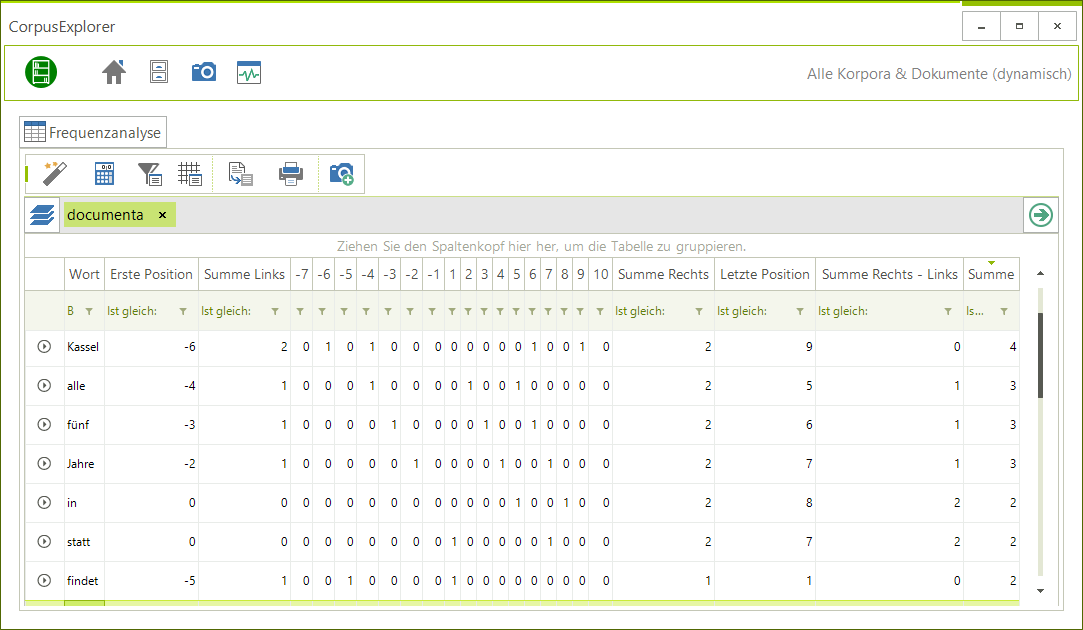
- Links/Rechts-Frequenz überarbeitet: Bisher war es nur möglich zu sehen, ob ein Wort rechts, links oder gar keine Tendenz im Verhältnis zum Suchwort hat. Die neu überarbeitete Fassung bringt eine ganze Fülle neuer Informationen mit sich. So ist jede einzelne Position links oder rechts erkennbar.
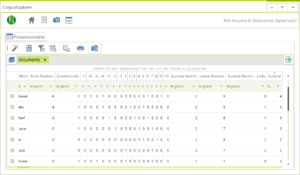
Überarbeitet: Links/Rechts-Frequenz
- Layer, Layer, Layer: Im letzten Update wurde für alle relevanten Analysemodule die Möglichkeit geschaffen, die Daten zu exportieren. Mit dem Juni/Juli 2018 Update kommt jetzt die Möglichkeit, die Analyselayer für fast alle Analyse abzuändern. Damit lassen sich z. B. Kookkurrenzen auf Lemma oder POS Ebene berechnen.
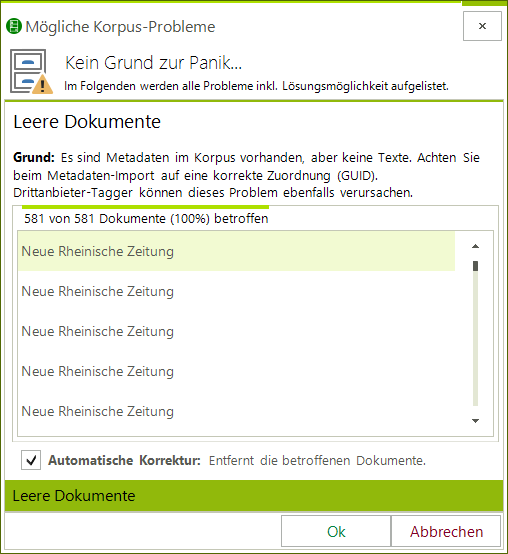
- Korpora – Überprüfung: Wurde alles richtig annotiert? Funktioniert die Satzgrenzenerkennung? Wurde jedes Dokument mit den gleichen Einstellungen annotiert?
Wenn Sie ein neues Korpus laden, überprüft der CorpusExplorer jetzt jede Datei auf Integrität. Nur wenn es Probleme gibt, meldet sich der CorpusExplorer und schlägt Ihnen mögliche Lösungen vor – Aus diesen Lösungen können Sie dann per Mausklick auswählen.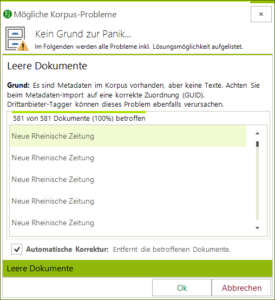
Neu: Korpora werden automatisch überprüft
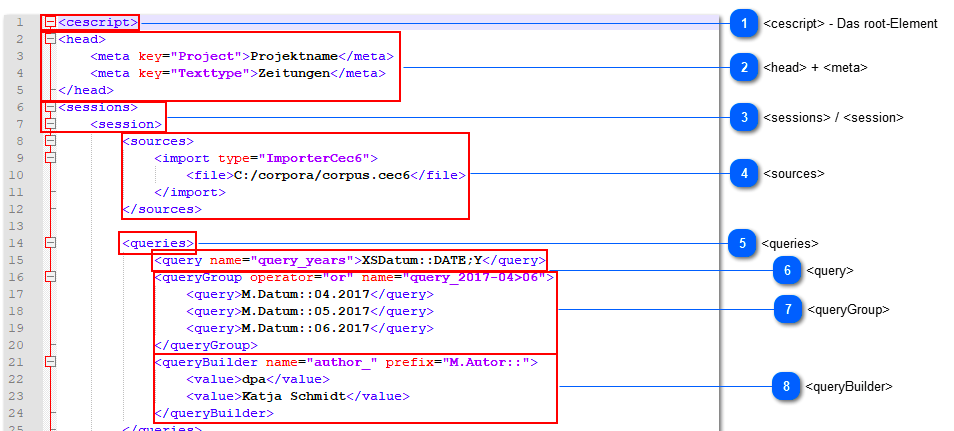
- XML-Skripte für Console: Ein bisher noch wenig genutztes (weil auch bisher wenig dokumentiertes) Feature ist die Möglichkeit, den CorpusExplorer per Konsole (also ohne GUI) zu steuern. Dies ist besonders dann hilfreich, wenn Sie Analysen automatisieren möchten oder wenn der CorpusExplorer aus anderen Programmen/Programmiersprachen z. B. R aufrufen wollen. Dieses Feature wurde jetzt um die Möglichkeit erweitert, mehrere Befehle in einem XML-Skript zu speichern. Außerdem wurde das Feature jetzt besser Dokumentiert: [siehe]
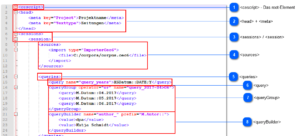
Neu: Abfragen mit XML-Skript
- ElasticSearch: Der CorpusExplorer ist nun kompatibel mit ElasticSearch 6.x
- Vereinheitlichung GUI: Die Eingabemasken für Suchausdrücke wurden vereinheitlicht. Der Farbauswahldialog (beta im letzten Update) ist jetzt für weitere Analysen verfügbar. Außerdem wurde der Dialog zum Anwählen alternativer Schnappschüsse (z. B. in Vergleichsanalysen) überarbeitet.
- Fehler „Korpusname“: Wurde im Prozess „Dokumente annotieren“ ein Korpusname vergeben, der ungültige Pfadzeichen (wie z. B. „, :, \) enthielt, dann konnte dies zu zerstückelten Korpusnamen führen. Das Update behebt den Fehler, indem ungültige Pfadzeichen zukünftig durch Unterstriche „_“ ersetzt werden.
- Überarbeitetes Installations-/Update-Packaging: Durch die neue Paketierung sind einzelnen Downloads kleiner – gerade Nutzer*innen mit schlechter Internetanbindung profitieren davon.
- Aktiver Speicherschutz: Der CorpusExplorer ist so konzipiert, dass er das Maximum an Performance aus einem Rechner herausholt. Mehrere parallele Berechnungen und intensive Nutzung des Arbeitsspeichers erlauben Analysen, die viele andere Programme nicht oder nur wesentlich langsamer verarbeiten. Auf einigen Rechnern kann dies zu Problemen führen, insbesondere wenn weitere Programme im Hintergrund laufen und der Arbeitsspeicher knapp ist. Der neue Schutzmechanismus soll vermeiden, dass der Arbeitsspeicher überläuft – damit sollte der CorpusExplorer auf den betroffenen Rechnern weniger Abstürze verursachen.
- Allgemeine Korrekturen und kleiner Bugfixes