2024-09-29 | CorpusExplorer, InAppNote
Folgende Neuerungen / Änderungen sind in Q3 2024 enthalten: CWB/CQPweb – Export verbessert: Dateien sind jetzt kleiner und lassen sich einfacher in CWB/CQPweb importieren. CEC6-Daten werden jetzt schneller eingelesen. GermaParlTEI: Neues Format zum Einlesen von...
2024-05-22 | Allgemein, CorpusExplorer, InAppNote
Das Q2-2024 Update beinhaltet die folgenden Neuerungen/Verbesserungen: Import / Export für FoLiA-XML Import für RelAnnis Fehler behoben: Unter bestimmten Umständen (hohe Bildschirm-Skalierungswerte) wurden die Checkmarks in der Checkliste (Startseite des...
2024-03-23 | CorpusExplorer, InAppNote
Das Q1-2024 Update bringt folgende Verbesserungen / Neuerungen: Die KWIC-Suche unterstützt jetzt die Suche nach Phrasen. (Checkbox: „Phrasen-Suche?“) Der DPXC-Editor behebt jetzt automatisch falsch formatierte GUIDs (aus anderen Programmen). Kleinere...
2023-12-20 | CorpusExplorer, InAppNote
Kurz vor Jahresende gibt es noch ein kleines Update für den CorpusExplorer. Folgende neue und geänderte Funktionen gibt es: Wichtig: Die Systemvoraussetzung wurde auf .NET 4.6.2 angehoben. Es ist absehbar, dass Microsoft den Support auch hierfür bald einstellt und...
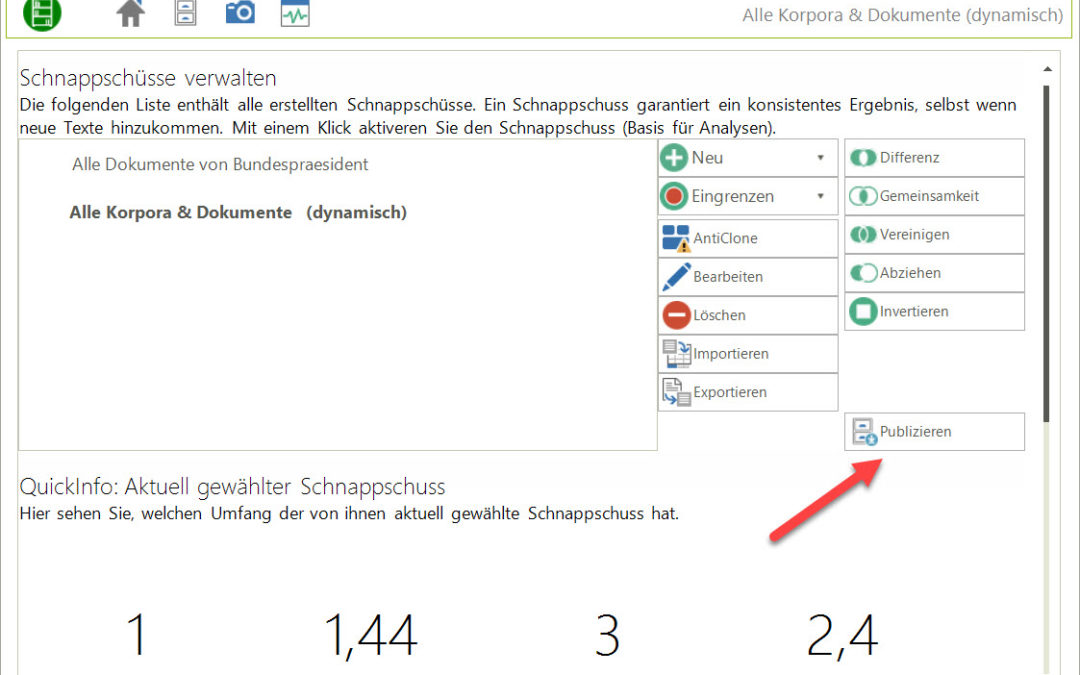
2023-07-02 | CorpusExplorer, InAppNote
Dieses Update bringt größere Neuerungen mit sich und steht ganz im Zeichen „Wie kommen Daten in den CorpusExplorer und aus dem CorpusExplorer heraus?“. Folgende Neuerungen gibt es: Der Publishing-Wizzard Diese Funktion ist in der...
2023-05-29 | CorpusExplorer, InAppNote
Eigentlich gibt es im Mai immer ein neues, größeres Update für den CorpusExplorer. Dieses Mal werde ich ‚größere‘ Änderungen auf Q3/Q4 verschieben müssen. Das Update umfasst neben verschiedenen Fehlerkorrekturen nur ein paar geringfügige Neuerungen: Der...