2026-03-15 | CorpusExplorer, InAppNote
Das Release Q1 2026 enthält keine neuen Features – nur kleinere und größere Fehlerkorrekturen (insbesondere durch Updates von Drittanbieter-Komponenten). Aktuell teste ich, ob HDF5 eine Alternative zum CEC6-Format sein kann. Es laufen auch größere Umbauarbeiten...
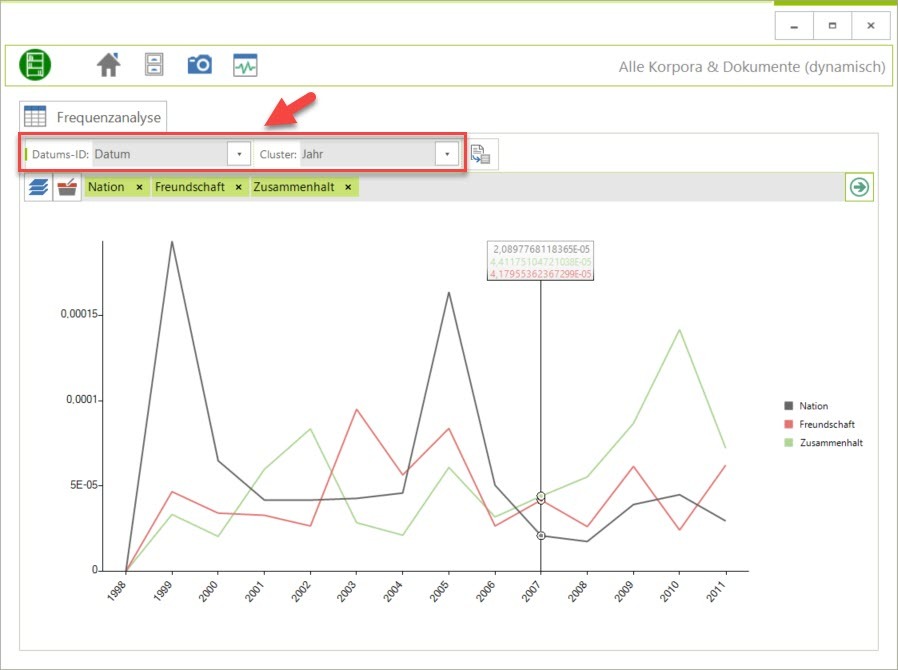
2025-10-11 | CorpusExplorer, InAppNote
CorpusExplorer – Releasenotes Q4 / 2025 Wichtige Neuerungen Überarbeitete Zeitverlaufs-Analysen Die Analyse über Zeitverläufe wurde grundlegend überarbeitet und flexibler gestaltet: Datentyp unabhängige Zeitangaben: Es ist nun nicht mehr erforderlich, dass Zeitangaben...
2025-08-26 | CorpusExplorer, InAppNote
Dieses Update umfasst nur kleinere Korrekturen und Fehlerbehebungen. Größere Neuerungen werden dann in Q4 2025 folgen. Genießt den Sommer
2025-06-28 | CorpusExplorer, InAppNote
Das Q2-Update für 2025 hält folgende Änderungen/Neuerungen bereit: Neue Import-Formate: Rotterdam Exchange Format Initiative (REFI-QDA). Daten die z. B. als QDA-Tools als REFI-kompatibel exportiert werden, lassen sich importieren. QDA-Tools wie MaxQDA (o. ä.) erlauben...