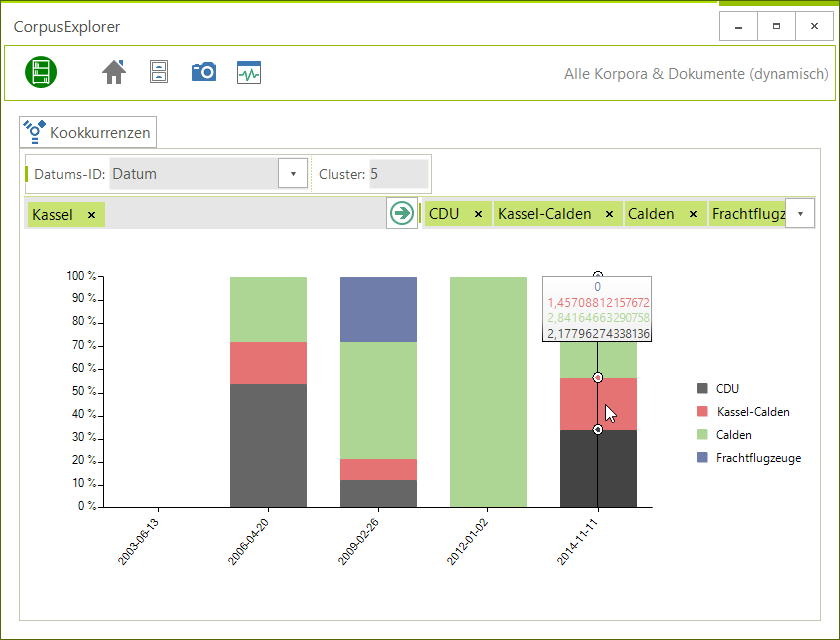
2016-11-05 | CorpusExplorer
Das November Update bringt viele neue Funktionen für Freunde von Zeitreihenanalysen. Neuerungen / Verbesserungen : Frequenzanalyse > Zeitliche Verteilung – Bisher war diese Funktion unter den Spezialfunktionen zu finden. Jetzt hat diese Analyseform endlich den...

2016-10-02 | GIT, GitHub, Repositories
„notesjor/kamoko“ By notesjor KAsseler MOrgenstern KOrpus – korpusbasierte Linguistik für Studierende des Französischen October 2, 2016 at 01:15AM via GitHub http://ift.tt/2dxovQ9
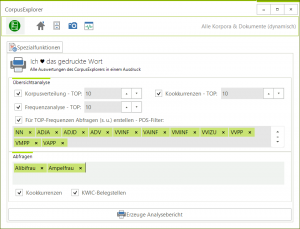
2016-07-25 | CorpusExplorer
Neues Update – Neue Funktion – Der „PaperLinguist“ ist jetzt verfügbar (Spezialanalysen). Dadurch wird es möglich, die wichtigsten Analysen in einem Rutsch auszudrucken bzw. als PDF, Word, Excel oder CSV zu exportieren. Aber vorsicht, bei...
2016-05-31 | CorpusExplorer
Normalerweise ist der Mai einer der wichtigsten Update-Monate für den CorpusExplorer. Dieses Jahr fällt das Mai Update etwas kleiner aus. Das liegt daran, dass ich mich auf drei Dinge fokussieren muss. 1. Wollen einige Artikel geschrieben werden. 2. Dieses Update...
2016-05-24 | GIT, GitHub, Repositories
„notesjor/kamoko-digitalizer“ By notesjor May 24, 2016 at 09:55PM via GitHub http://ift.tt/1qHN4Qv
2016-04-09 | CorpusExplorer
Das April Update ist 100%-iges BugFix-Update. Was wurde verbessert: Die neue HTML5-Engine Wichtig: Wer zwischen dem 25.03.2016 und 07.04.2016 ein Update durchgeführt hat, steckt wohl möglich in einer Updateschleife fest. Grund: Der CorpusExplorer wird nicht korrekt...

2016-03-13 | Allgemein, CorpusExplorer
Da fährt man nichtsahnend nach Leipzig zur DHd2016 und kommt völlig überrascht mit einem „Lisa Lena Opas-Hänninen Young Scholar Prize“ zurück. Den prämierten Vortrag kann man [hier herunterladen]. Das vorgestellte Programm ist, wie könnte es anders sein,...
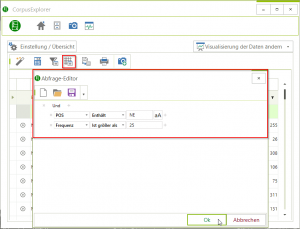
2016-01-14 | CorpusExplorer
Mit dem ersten Update in 2016 ändert sich sehr viel für den CorpusExplorer denn er wird offen und flexibel. Add-on System Bisher gab es mehrere spezielle Projektversionen – Zusätlich zu den drei bisherigen (Standard, PC-Poolraum, Insider). Unter der folgenden...
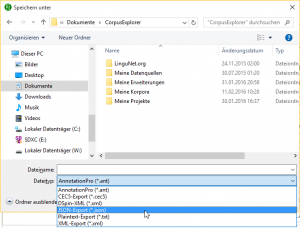
2015-12-15 | CorpusExplorer
Das Update bringt viele kleine Verbesserungen mit sich. Die zwei wichtigsten hier: Das Export-System wurde komplett neu entwickelt. Damit ist es jetzt möglich, eigene Exporter für den CorpusExplorer zu schreiben. Für Nutzer*innen biete das neue Export-System bereits...
2015-11-20 | CorpusExplorer
Das November Update ist unscheinbar. Eine wichtige aber für Nutzer*innen vorerst unsichtbare Änderung: Der CorpusExplorer kann ab jetzt für viele verschiedene Datenformate genutzt werden (kein Import nötig). Dank Adapter-Pattern (Insider für OOP-Entwickler*innen). Die...