Notes – das sind meine persönlichen Notizen zur Sprachwissenschaft, gemischt mit Quellcode, Ideen und Dingen, die mich sonst so bewegen. Der fragmentarische Charakter einer Sammelbox ist daher gewollt. Bilder, Fotos und Illustrationen sind nicht nur bunt, sondern visualisieren mein Denken. Daher ist der Blog nicht nur Sammelbox, sondern auch im ursprünglichen Sinn ein gedankliches Tagebuch.
CorpusExplorer – Ein Programm, das aus meiner Magisterarbeit erwachsen ist und im aktuellen Promotionsprojekt weiterentwickelt wird. Der CorpusExplorer vereint eine Vielzahl bekannter computer-/korpuslinguistischer Tools. Er vereinfacht das Arbeiten mit großen Textmengen und erlaubt es, Korpora als Wissensquelle neu zu entdecken … Das Ziel: Sprache und Technik ein Stück näher zusammenzubringen.
Kontakt / Vernetzung
dieser Blog ist unter:
https://notes.jan-oliver-ruediger.de/@me
im Fediverse/Mastodon verfügbar. Wer mir aus dem Fediverse/Mastodon schreiben möchte, verwendet bitte den Account:
@notesjor@fediscience.org
über Bluesky:
notesjor.bsky.social
weitere soziale Netzwerke sind hier zu finden:
LINK-TREE
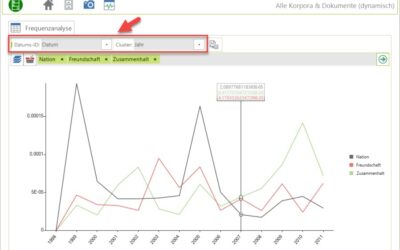
CorpusExplorer (Update Q4 2025)
CorpusExplorer – Releasenotes Q4 / 2025 Wichtige Neuerungen Überarbeitete Zeitverlaufs-Analysen Die Analyse über Zeitverläufe wurde grundlegend überarbeitet und flexibler gestaltet: Datentyp unabhängige Zeitangaben: Es ist nun nicht mehr erforderlich, dass Zeitangaben...
CorpusExplorer (Update Q3 2025)
Dieses Update umfasst nur kleinere Korrekturen und Fehlerbehebungen. Größere Neuerungen werden dann in Q4 2025 folgen. Genießt den Sommer
CorpusExplorer (Update Q2 2025)
Das Q2-Update für 2025 hält folgende Änderungen/Neuerungen bereit: Neue Import-Formate: Rotterdam Exchange Format Initiative (REFI-QDA). Daten die z. B. als QDA-Tools als REFI-kompatibel exportiert werden, lassen sich importieren. QDA-Tools wie MaxQDA (o. ä.) erlauben...
CorpusExplorer (Update Q1 2025)
Das erste Quartals-Update (Q1) für 2025 bringt folgende Neuerungen und Verbesserungen: Verbesserung der Performance für verschiedene Volltext-Filter/Suchen. Insbesondere für exakte und flexible Phrasen. Filter um Multi-Layer NGramme selektiv zu filtern. Die Analysen...
CorpusExplorer (Update Q4 2024)
So, das letzte Update für dieses Jahr. Ich wünsche euch schon einmal frohe Feiertage und einen guten Start ins Jahr 2025. Folgende Neuerungen / Änderungen und Verbesserungen gibt es: Salt-XML kann jetzt direkt importiert werden. Eine Installation von Salt&Pepper...
CorpusExplorer (Update Q3 2024)
Folgende Neuerungen / Änderungen sind in Q3 2024 enthalten: CWB/CQPweb - Export verbessert: Dateien sind jetzt kleiner und lassen sich einfacher in CWB/CQPweb importieren. CEC6-Daten werden jetzt schneller eingelesen. GermaParlTEI: Neues Format zum Einlesen von...
CorpusExplorer (Update Q2 2024)
Das Q2-2024 Update beinhaltet die folgenden Neuerungen/Verbesserungen: Import / Export für FoLiA-XML Import für RelAnnis Fehler behoben: Unter bestimmten Umständen (hohe Bildschirm-Skalierungswerte) wurden die Checkmarks in der Checkliste (Startseite des...
CorpusExplorer (Update Q1 2024)
Das Q1-2024 Update bringt folgende Verbesserungen / Neuerungen: Die KWIC-Suche unterstützt jetzt die Suche nach Phrasen. (Checkbox: "Phrasen-Suche?") Der DPXC-Editor behebt jetzt automatisch falsch formatierte GUIDs (aus anderen Programmen). Kleinere Optimierungen,...
CorpusExplorer (Update Q4 2023)
Kurz vor Jahresende gibt es noch ein kleines Update für den CorpusExplorer. Folgende neue und geänderte Funktionen gibt es: Wichtig: Die Systemvoraussetzung wurde auf .NET 4.6.2 angehoben. Es ist absehbar, dass Microsoft den Support auch hierfür bald einstellt und...
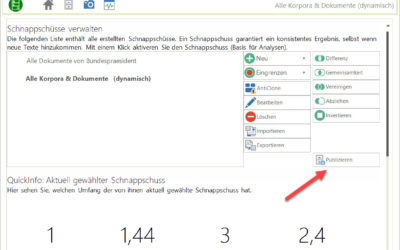
CorpusExplorer (Update Q3 2023)
Dieses Update bringt größere Neuerungen mit sich und steht ganz im Zeichen "Wie kommen Daten in den CorpusExplorer und aus dem CorpusExplorer heraus?". Folgende Neuerungen gibt es: Der Publishing-Wizzard Diese Funktion ist in der "Schnappschuss-Übersicht" zu finden....
CorpusExplorer (Update Q2 2023)
Eigentlich gibt es im Mai immer ein neues, größeres Update für den CorpusExplorer. Dieses Mal werde ich 'größere' Änderungen auf Q3/Q4 verschieben müssen. Das Update umfasst neben verschiedenen Fehlerkorrekturen nur ein paar geringfügige Neuerungen: Der Befehl...
CorpusExplorer (Update Q1 2023) – SP1
Kleines Service-Pack für das Q1-Update. Folgende Neuerungen und Verbesserungen wurden eingepflegt: Neues Format für CMS-Exporte. Neuer Query-Editor für Tabellenabfragen. CEC Cluster kann jetzt im Modus Loop exportieren. Fehler im WebCrawler wurden behoben....
CorpusExplorer (Update Q1 2023)
Für das Jahr 2023 wünsche ich Euch alles Gute. Ein kleines Update gibt es ganz zum Jahresanfang. Es behebt primär einige kleine Fehler und bietet ein paar Neuerungen: Neue Funktionen: Neuer Export für die verbesserte Version der CWB (CorpusWorkBench). Diese wurde im...
CorpusExplorer (Update Q3/Q4 2022)
Mit etwas Verspätung erscheint das Q3-Release des CorpusExplorers. Evtl. wird es noch ein weiteres Update in diesem Jahr geben. Folgendes ist neu oder wurde geändert: Neuerung: Mit MDA (Multidimensional Document Analyzer) gibt es jetzt eine relativ einfache wie auch...
CorpusExplorer (Update Q2 2022)
Eigentlich hatte ich das Update für das Q2 2022 erst für Mai 2022 geplant. Es wird auch ein Mai-Update geben, denn traditionell gibt es im Q2/Mai eines jeden Jahres das größte Update. Trotzdem haben sich jetzt einige Aktualisierungen und Korrekturen angesammelt -...
CorpusExplorer (Update Q1 2022) – SP1
Der CorpusExplorer unterstützt ab jetzt "Sketch Engine VERT" sowohl für den Im- als auch den Export.
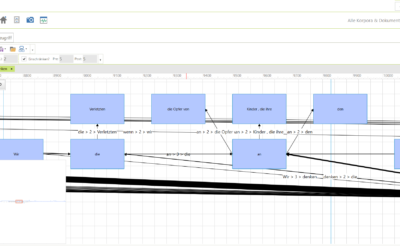
CorpusExplorer (Update Q1 2022)
Alle Nutzer*innen des CorpusExplorers wünsche ich ein frohes, gesundes und erfolgreiches Jahr 2022. Der CorpusExplorer startet dieses Jahr früh mit dem ersten Quartals-Release Q1-2022. Es gibt einige spannende Neuerungen und viele weitere sind für 2022 bereits in...
CorpusExplorer (Update Q4 2021)
Das 2021Q4-Update für den CorpusExplorer bringt folgende Neuerungen/Verbesserungen: LDA-Topic Modeling Der CorpusExplorer verfügt jetzt über die Möglichkeit ein Topic-Modell zu erzeugen. Grundlage ist hierfür LightLDA (https://github.com/microsoft/LightLDA) eine...
CorpusExplorer (Update Q2/Q3 2021)
Das gebündelte Q2/Q3 Update bringt einige neue und verbesserte Funktionen mit sich. Außerdem markiert es den ersten Meilenstein einer längeren Entwicklung - der CEC-UI. Neue Funktionen: Scaper- und Import-Unterstützung für "IDS KorAP - XML" Import-Unterstützung für...
CorpusExplorer (Update Q1 2021 – SP1)
Kleines zusätzliches Update - zusätzlich zum Update Q1 2021. Neuerungen: Neues Format für: FOLKER/OrthoNormal FLN (annotieren & Import). Der Post-Analyse-Filter für korrespondierende Layer-Werte kann jetzt auch über die Konsole/Shell genutzt werden. Verbseerungen:...
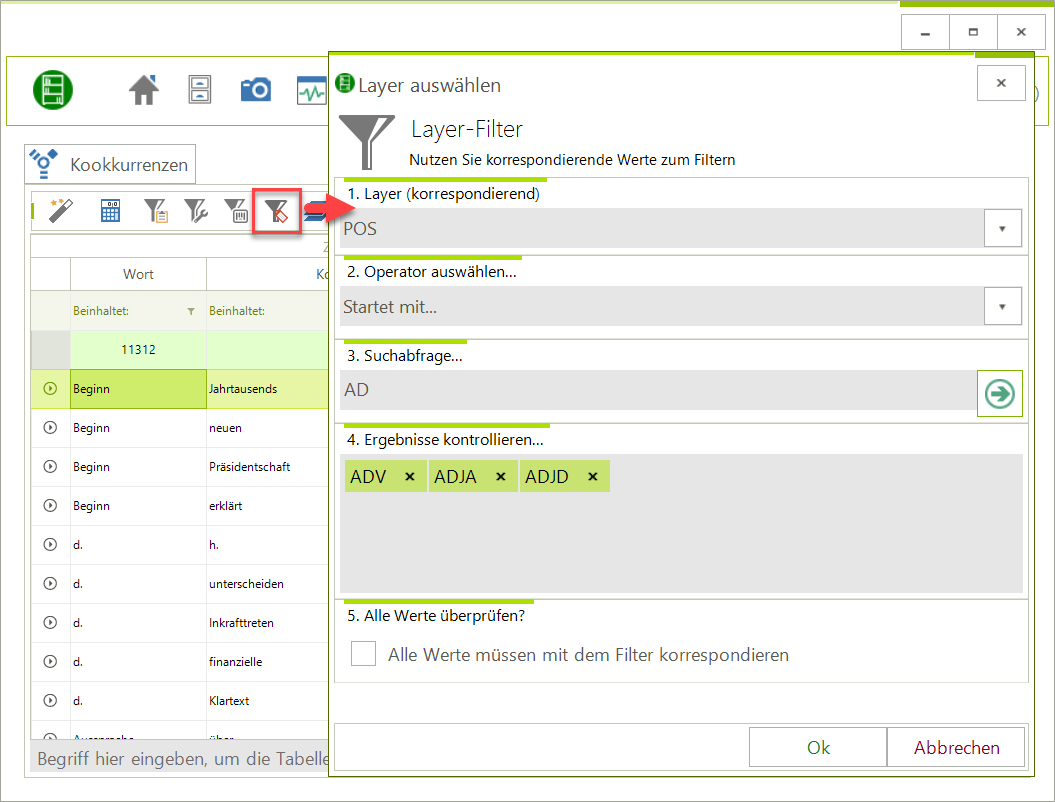
CorpusExplorer (Update Q1 2021)
Vielleicht irre ich mich - aber ich glaube, in 2021 werden einige große Dinge mit dem CorpusExplorer passieren. Zumindest haben sich viele Funktionen angesammelt, die darauf warten veröffentlicht zu werden. Also starten wir mir den Änderungen für Q1 2021: DPXC-Editor...
57. Jahrestagung des Leibniz-Instituts für Deutsche Sprache: 9. bis 11. März 2021
Das Programm der IDS Jahrestagung kann hier eingesehen werden: https://www1.ids-mannheim.de/aktuell/veranstaltungen/tagungen/2021/programm.html Eine Anmeldung ist über https://www.ids-mannheim.de/org/tagungen/anmeldung.html möglich.

ZOOM-Vortrag 26.03.2021: vDHd2021
Der Diskursmonitor ist eine gemeinschaftlich erarbeitete Online-Plattform zur Aufklärung und Dokumentation strategischer Kommunikation. 2019 als offenes Lehrstuhlprojekt gestartet, umfasst der Diskursmonitor mittlerweile vier stetig wachsende Teilprojekte: Glossar:...
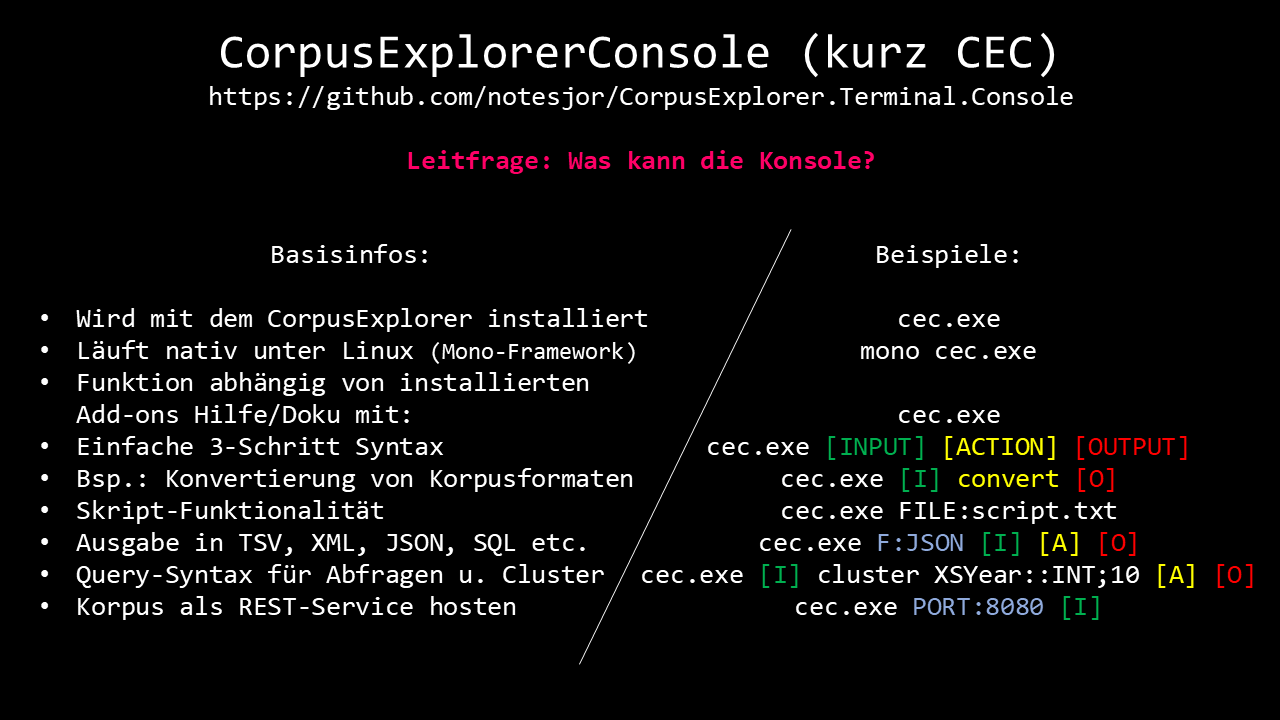
ZOOM-Vortrag 16.12.2020 an der Friedrich-Alexander-Universität (Erlangen-Nürnberg)
Im Rahmen des "Oberseminars Computerlinguistik (WS 2020/21)" - an der Friedrich-Alexander-Universität (Erlangen-Nürnberg) wird mit dem Vortrag "Einführung in den CorpusExplorer" nicht nur in die Grundlagen des CorpusExplorers eingeführt - sondern auch die vertiefende...

‚Posterslam‘ – 2. DigitalHumanities-Tag der WWU Münster
Das Projekt „Sprache und Konfession im Radio“ stellt sich und den CorpusExplorer im Rahmen des Posterslams vor (2. DigitalHumanities-Tag der WWU Münster).
Video-Player
00:00
02:06
Zum Projekt: Das Christentum hat die deutsche Sprache Jahrhunderte lang stark beeinflusst. Die jüngste Frühe Neuzeitforschung konnte zeigen, dass sogar die Reformation und die anschließende Etablierung verschiedener Konfessionen zu Sprachgebrauchsdifferenzen zwischen Katholiken und Protestanten geführt haben. Für die Gegenwartssprache hingegen ist eine große Forschungslücke bezüglich des Zusammenhangs von Sprache und Konfession zu konstatieren: Untersuchungen zur Pluralität sprachlicher Ausdrucksformen haben Konfession als möglichen sprachlicher Variationsfaktor noch kaum berücksichtigt. Eine Umfrage in 2014 hat jedoch Hinweise darauf gefunden, dass Katholiken und Protestanten mit jeweils unterschiedlichem Wortgebrauch und Sprachstilen, ja sogar differierender Textstrukturierung verbunden werden. Linguistisch untersucht worden sind diese Zuordnungen bislang noch nicht. Ziel dieses Projekts ist es daher, Texte der heutigen öffentlichen Glaubensverkündigung im Radio auf verschiedenen sprachlichen Ebenen von der Themenwahl, der Textstruktur über die Syntax und Wortbildung bis hin zur Lexik zu analysieren und herauszufinden, ob auch heute noch – 500 Jahre nach der Reformation – konfessionelle Sprachgebrauchsdifferenzen festzustellen sind. Damit kann die deutsche Sprachgeschichte um ein wichtiges Kapitel erweitert werden. [Weitere Informationen zum Projekt]