CorpusExplorer – Ein Programm, das aus meiner Magisterarbeit erwachsen ist und im aktuellen Promotionsprojekt weiterentwickelt wird. Der CorpusExplorer vereint eine Vielzahl bekannter computer-/korpuslinguistischer Tools. Er vereinfacht das Arbeiten mit großen Textmengen und erlaubt es, Korpora als Wissensquelle neu zu entdecken … Das Ziel: Sprache und Technik ein Stück näher zusammenzubringen.
CorpusExplorer (Update Q1 2022)
Alle Nutzer*innen des CorpusExplorers wünsche ich ein frohes, gesundes und erfolgreiches Jahr 2022. Der CorpusExplorer startet dieses Jahr früh mit dem ersten Quartals-Release Q1-2022. Es gibt einige spannende Neuerungen und viele weitere sind für 2022 bereits in...
CorpusExplorer (Update Q4 2021)
Das 2021Q4-Update für den CorpusExplorer bringt folgende Neuerungen/Verbesserungen: LDA-Topic Modeling Der CorpusExplorer verfügt jetzt über die Möglichkeit ein Topic-Modell zu erzeugen. Grundlage ist hierfür LightLDA (https://github.com/microsoft/LightLDA) eine...
CorpusExplorer (Update Q2/Q3 2021)
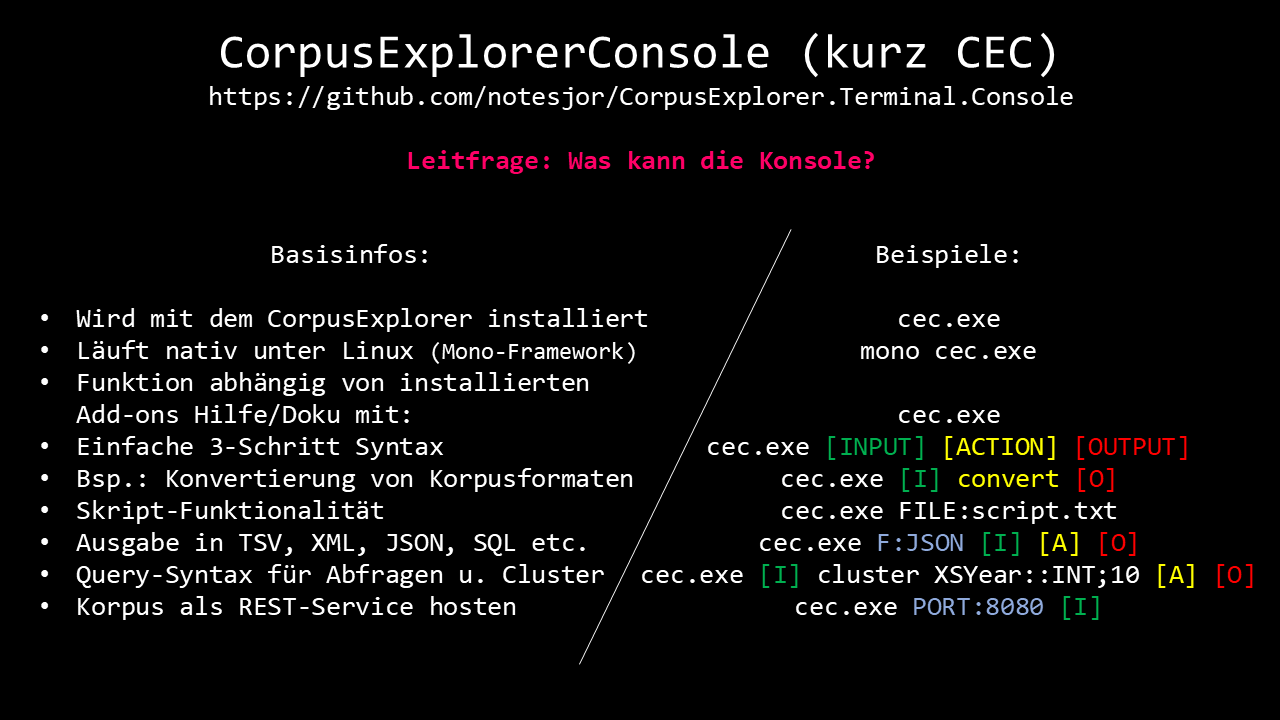
Das gebündelte Q2/Q3 Update bringt einige neue und verbesserte Funktionen mit sich. Außerdem markiert es den ersten Meilenstein einer längeren Entwicklung - der CEC-UI. Neue Funktionen: Scaper- und Import-Unterstützung für "IDS KorAP - XML" Import-Unterstützung für...
CorpusExplorer (Update Q1 2021 – SP1)
Kleines zusätzliches Update - zusätzlich zum Update Q1 2021. Neuerungen: Neues Format für: FOLKER/OrthoNormal FLN (annotieren & Import). Der Post-Analyse-Filter für korrespondierende Layer-Werte kann jetzt auch über die Konsole/Shell genutzt werden. Verbseerungen:...
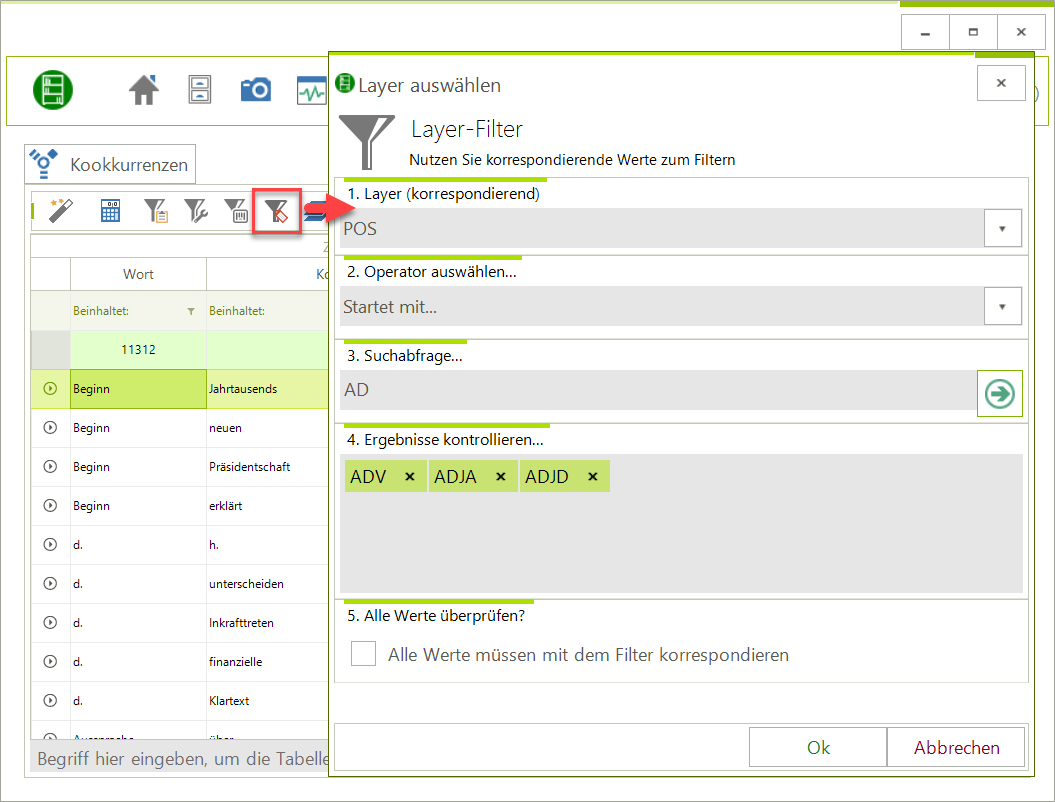
CorpusExplorer (Update Q1 2021)
Vielleicht irre ich mich - aber ich glaube, in 2021 werden einige große Dinge mit dem CorpusExplorer passieren. Zumindest haben sich viele Funktionen angesammelt, die darauf warten veröffentlicht zu werden. Also starten wir mir den Änderungen für Q1 2021: DPXC-Editor...
57. Jahrestagung des Leibniz-Instituts für Deutsche Sprache: 9. bis 11. März 2021
Das Programm der IDS Jahrestagung kann hier eingesehen werden: https://www1.ids-mannheim.de/aktuell/veranstaltungen/tagungen/2021/programm.html Eine Anmeldung ist über https://www.ids-mannheim.de/org/tagungen/anmeldung.html möglich.

ZOOM-Vortrag 26.03.2021: vDHd2021
Der Diskursmonitor ist eine gemeinschaftlich erarbeitete Online-Plattform zur Aufklärung und Dokumentation strategischer Kommunikation. 2019 als offenes Lehrstuhlprojekt gestartet, umfasst der Diskursmonitor mittlerweile vier stetig wachsende Teilprojekte: Glossar:...
ZOOM-Vortrag 16.12.2020 an der Friedrich-Alexander-Universität (Erlangen-Nürnberg)
Im Rahmen des "Oberseminars Computerlinguistik (WS 2020/21)" - an der Friedrich-Alexander-Universität (Erlangen-Nürnberg) wird mit dem Vortrag "Einführung in den CorpusExplorer" nicht nur in die Grundlagen des CorpusExplorers eingeführt - sondern auch die vertiefende...

‚Posterslam‘ – 2. DigitalHumanities-Tag der WWU Münster
Das Projekt „Sprache und Konfession im Radio“ stellt sich und den CorpusExplorer im Rahmen des Posterslams vor (2. DigitalHumanities-Tag der WWU Münster).
Video-Player
00:00
02:06
Zum Projekt: Das Christentum hat die deutsche Sprache Jahrhunderte lang stark beeinflusst. Die jüngste Frühe Neuzeitforschung konnte zeigen, dass sogar die Reformation und die anschließende Etablierung verschiedener Konfessionen zu Sprachgebrauchsdifferenzen zwischen Katholiken und Protestanten geführt haben. Für die Gegenwartssprache hingegen ist eine große Forschungslücke bezüglich des Zusammenhangs von Sprache und Konfession zu konstatieren: Untersuchungen zur Pluralität sprachlicher Ausdrucksformen haben Konfession als möglichen sprachlicher Variationsfaktor noch kaum berücksichtigt. Eine Umfrage in 2014 hat jedoch Hinweise darauf gefunden, dass Katholiken und Protestanten mit jeweils unterschiedlichem Wortgebrauch und Sprachstilen, ja sogar differierender Textstrukturierung verbunden werden. Linguistisch untersucht worden sind diese Zuordnungen bislang noch nicht. Ziel dieses Projekts ist es daher, Texte der heutigen öffentlichen Glaubensverkündigung im Radio auf verschiedenen sprachlichen Ebenen von der Themenwahl, der Textstruktur über die Syntax und Wortbildung bis hin zur Lexik zu analysieren und herauszufinden, ob auch heute noch – 500 Jahre nach der Reformation – konfessionelle Sprachgebrauchsdifferenzen festzustellen sind. Damit kann die deutsche Sprachgeschichte um ein wichtiges Kapitel erweitert werden. [Weitere Informationen zum Projekt]
Summer School (RUB Bochum) – 24. bis 28. August 2020: „tl;dr“ Too long; didn’t read (?) Große Textmengen computergestützt analysieren
Die Summer School beschäftigt sich mit computergestützten Verfahren, um große Mengen digitaler Texte, wie z. B. Internet-Blogs, Social Media-Einträge oder twitter Posts, zu extrahieren (Web Scraping), zu analysieren und für empirischen Forschungsprojekte und Abschlussarbeiten zu nutzen. Von korpuslinguistischen Verfahren (Frequenz- und Kollokationsanalysen) bis zu Machine Learning-Algorithmen werden methodische Ansätze aus vielfältigen Disziplinen zusammengebracht und aus der jeweils fachwissenschaftlichen Sicht diskutiert und in Hands-on Sessions in kleinen Gruppen an konkreten Fragestellungen praktisch eingeübt. Die Ergebnisse werden abschließend im Plenum präsentiert und diskutiert. Zur Vorbereitung der Summer School werden den Studierenden 1-2 tägige Workshops angeboten, um sich mit den theoretischen Grundlagen (Lektüre) und den erforderlichen Software-Tools Vertraut zu machen.