Notes – das sind meine persönlichen Notizen zur Sprachwissenschaft, gemischt mit Quellcode, Ideen und Dingen, die mich sonst so bewegen. Der fragmentarische Charakter einer Sammelbox ist daher gewollt. Bilder, Fotos und Illustrationen sind nicht nur bunt, sondern visualisieren mein Denken. Daher ist der Blog nicht nur Sammelbox, sondern auch im ursprünglichen Sinn ein gedankliches Tagebuch.
CorpusExplorer – Ein Programm, das aus meiner Magisterarbeit erwachsen ist und im aktuellen Promotionsprojekt weiterentwickelt wird. Der CorpusExplorer vereint eine Vielzahl bekannter computer-/korpuslinguistischer Tools. Er vereinfacht das Arbeiten mit großen Textmengen und erlaubt es, Korpora als Wissensquelle neu zu entdecken … Das Ziel: Sprache und Technik ein Stück näher zusammenzubringen.
Fediverse / Mastodon / eX – Sie können diesen Blog im Fedivers – also z. B. auch in Mastodon – folgen. Nutzen Sie dazu bitte die folgende Adresse:
https://notes.jan-oliver-ruediger.de/@me
oder:
@me@notes.jan-oliver-ruediger.de
Bitte beachten Sie: Nachdem Sie dem Blog folgen, erhalten Sie alle neuen Beiträge in ihrer Timeline. Ältere Beiträge werden i. d. R. von Mastodon nicht angezeigt.
CorpusExplorer v2.0 – Mai Update
Normalerweise ist der Mai einer der wichtigsten Update-Monate für den CorpusExplorer. Dieses Jahr fällt das Mai Update etwas kleiner aus. Das liegt daran, dass ich mich auf drei Dinge fokussieren muss. 1. Wollen einige Artikel geschrieben werden. 2. Dieses Update...
Repository „notesjor/kamoko-digitalizer“ auf GitHub veröffentlicht
"notesjor/kamoko-digitalizer" By notesjor May 24, 2016 at 09:55PM via GitHub http://ift.tt/1qHN4Qv
CorpusExplorer v2.0 – April Update
Das April Update ist 100%-iges BugFix-Update. Was wurde verbessert: Die neue HTML5-Engine Wichtig: Wer zwischen dem 25.03.2016 und 07.04.2016 ein Update durchgeführt hat, steckt wohl möglich in einer Updateschleife fest. Grund: Der CorpusExplorer wird nicht korrekt...

Lisa Lena Opas-Hänninen Young Scholar Prize 2016
Da fährt man nichtsahnend nach Leipzig zur DHd2016 und kommt völlig überrascht mit einem "Lisa Lena Opas-Hänninen Young Scholar Prize" zurück. Den prämierten Vortrag kann man [hier herunterladen]. Das vorgestellte Programm ist, wie könnte es anders sein, der...
CorpusExplorer v2.0 – 2016 is here!
Mit dem ersten Update in 2016 ändert sich sehr viel für den CorpusExplorer denn er wird offen und flexibel. Add-on System Bisher gab es mehrere spezielle Projektversionen - Zusätlich zu den drei bisherigen (Standard, PC-Poolraum, Insider). Unter der folgenden URL...
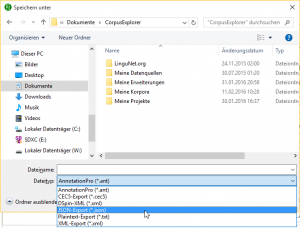
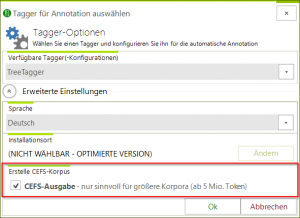
CorpusExplorer v2.0 – Dezember Update
Das Update bringt viele kleine Verbesserungen mit sich. Die zwei wichtigsten hier: Das Export-System wurde komplett neu entwickelt. Damit ist es jetzt möglich, eigene Exporter für den CorpusExplorer zu schreiben. Für Nutzer*innen biete das neue Export-System bereits...
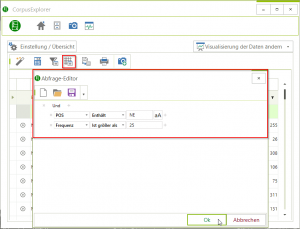
CorpusExplorer v2.0 – November Update
Das November Update ist unscheinbar. Eine wichtige aber für Nutzer*innen vorerst unsichtbare Änderung: Der CorpusExplorer kann ab jetzt für viele verschiedene Datenformate genutzt werden (kein Import nötig). Dank Adapter-Pattern (Insider für OOP-Entwickler*innen). Die...
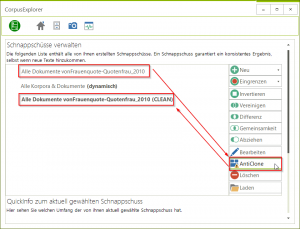
CloneDetection
Egal ob Tweets oder Zeitungsartikel - viele Korpora enthalten Textsorten, die per se zu Duplikaten neigen. Der CorpusExplorer kann jetzt diese automatisch entfernen. Laden Sie ein Korpus. Rufen Sie die Schnappschuss-Detailansicht auf und klicken Sie auf AntiClone....
Repository „notesjor/KAMOKO“ auf GitHub veröffentlicht
"notesjor/KAMOKO" By notesjor KAsseler MOrgenstern KOrpus – korpusbasierte Linguistik für Studierende des Französischen October 24, 2015 at 07:09PM via GitHub http://ift.tt/1i4aNG1
CorpusExplorer v2.0 – Oktober Release
Was ist neu im Oktober Release des CorpusExplorers? Neue Scraper für EPUB, DSpin-XML & PDF. Neuer Scraper "Auf gut Glück!" - versucht aus allen Dateien den größtmöglichen Textinhalt zu extrahieren. Mengenoperationen für Schnappschüsse (inner/outer join, diff)....