CorpusExplorer
OpenSource Software für Korpuslinguist*innen und Text-/Data-Mining Interessierte. Der CorpusExplorer vereint über 50 interaktiven Auswertungsmöglichkeiten mit einer einfachen Bedienung. Routineaufgaben wie z. B. Textakquise, Taggen oder die grafische Aufbereitung von Ergebnissen werden vollständig automatisiert. Die einfache Handhabung erleichtert den Einsatz in der universitären Lehre und führt zu schnellen sowie gehaltvollen Ergebnissen. Dabei ist der CorpusExplorer offen für viele Standards (XML, CSV, JSON, R, uvm.) und bietet darüber hinaus ein eigenes Software Development Kit (SDK) an, mit dem es möglich ist, alle Funktionen in eigene Programme zu integrieren.
Einfacher Einstieg / Frei verfügbare Materialien:
Hilfe bei Problemen:

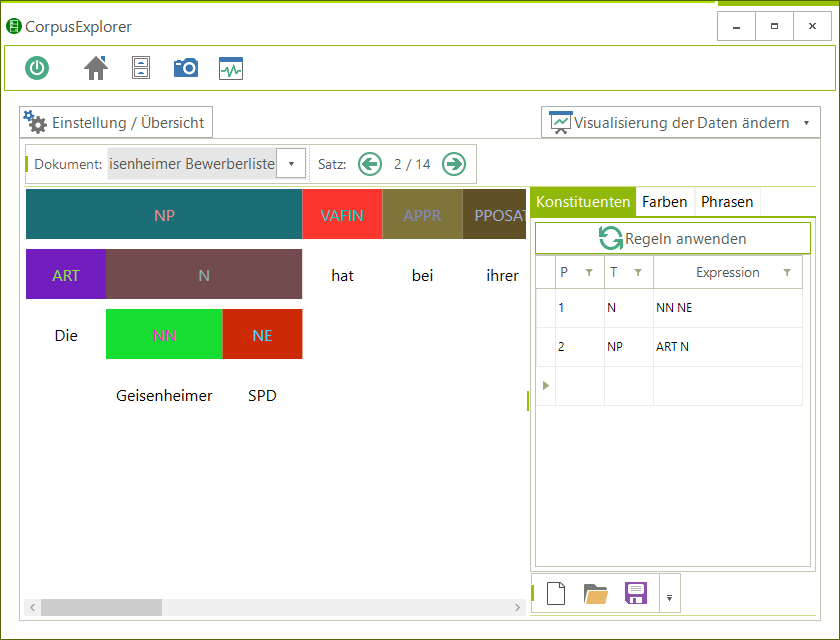
Key Features:
- Unterstützt über 100 unterschiedliche Datei-/Textformate für Im-/Export – inkl. vieler linguistischer XML-Formate.
- Integrierter Webcrawler zum Sammeln eigener Webkorpora.
- Sehr einfache Programmoberfläche / Korpus mit wenigen Mausklicks automatisch bereinigen und annotieren – direkt analysefertig.
- Anbindung unterschiedlicher Tagger – z. B. TreeTagger, OpenNLP, Stanford POS, uvm.
- Erlaubt Analyse unterschiedlichster Quellen – z. B. Transkripte, Zeitungsartikel, PDF, E-Mails, Tweets, Webseiten, eBooks, uvm.
- Kostenfreie analysefertige Korpora (ca. 5 Mrd. Token) zum direkten Download.
- Im Hintergrund arbeitet eine sehr schnelle In-Memory Datenbank – speziell für die Korpusanalyse entwickelt. Diese Datenbank kann gegen verschiedene SQL- (MySQL, SQLite) und NoSQL-Datenbanken (ElasticSearch) ausgetauscht werden.
- Unbegrenzte Korpusgröße – Verteilte Verarbeitung möglich.
- Alle Daten unter ihrer Kontrolle. Nach der Installation ist keine weitere Internetverbindung notwendig (außer für Updates). (Korpus-)Daten werden an keinen Server übermittelt.
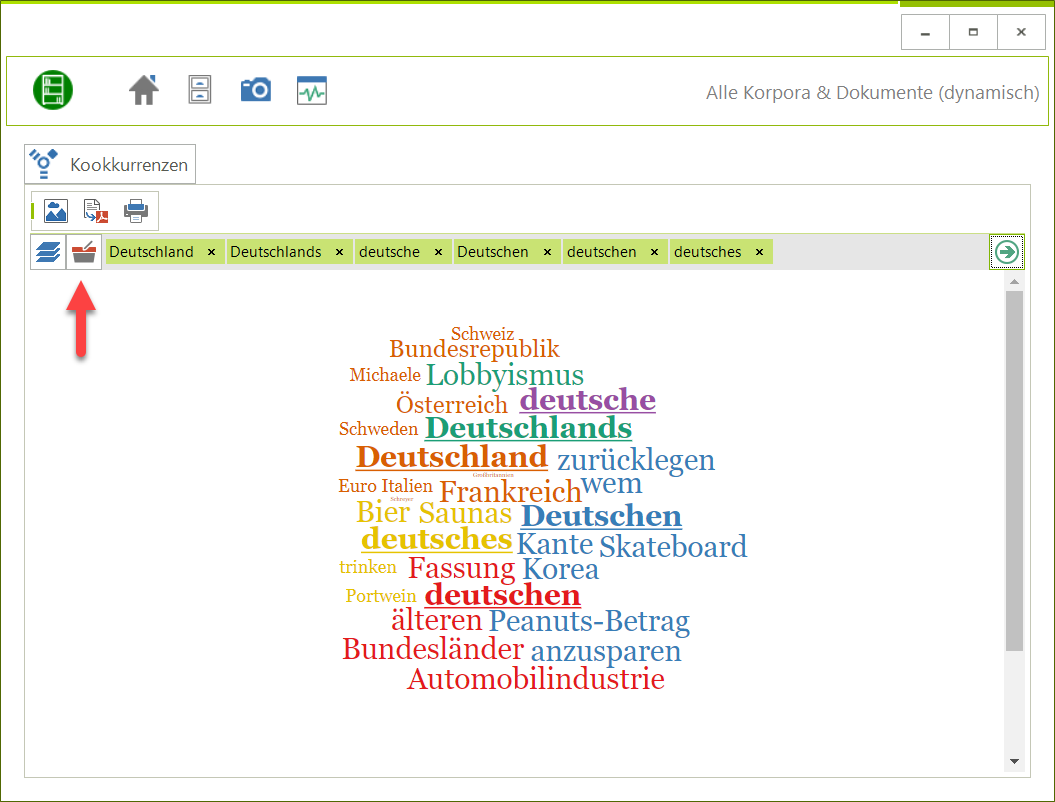
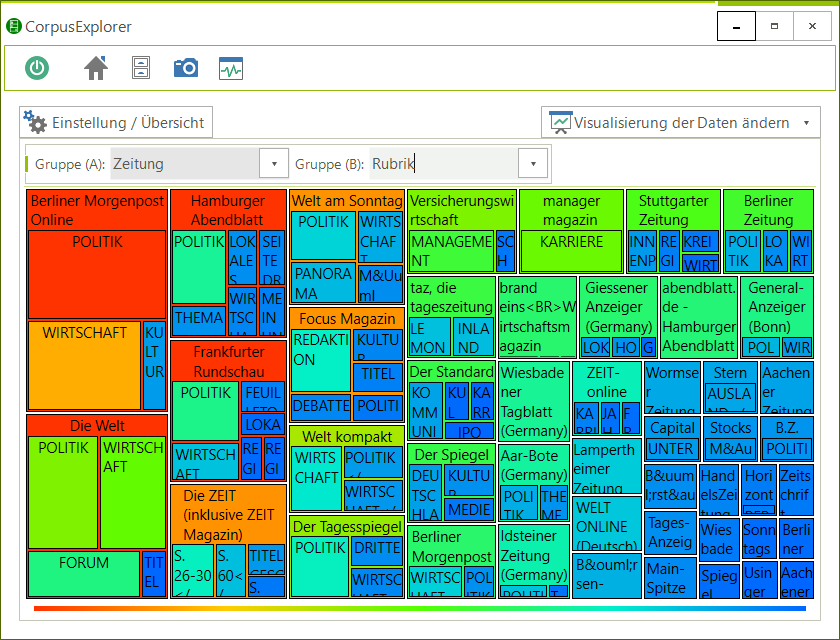
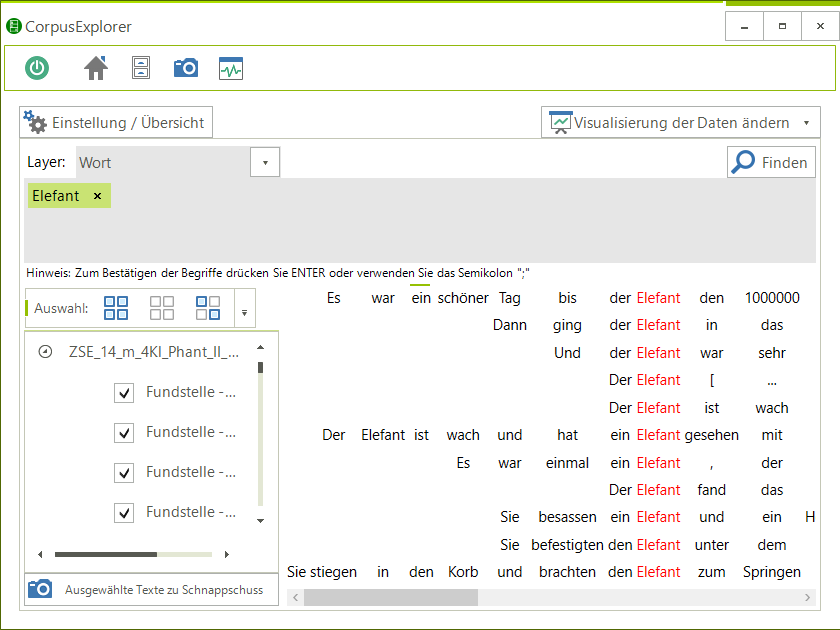
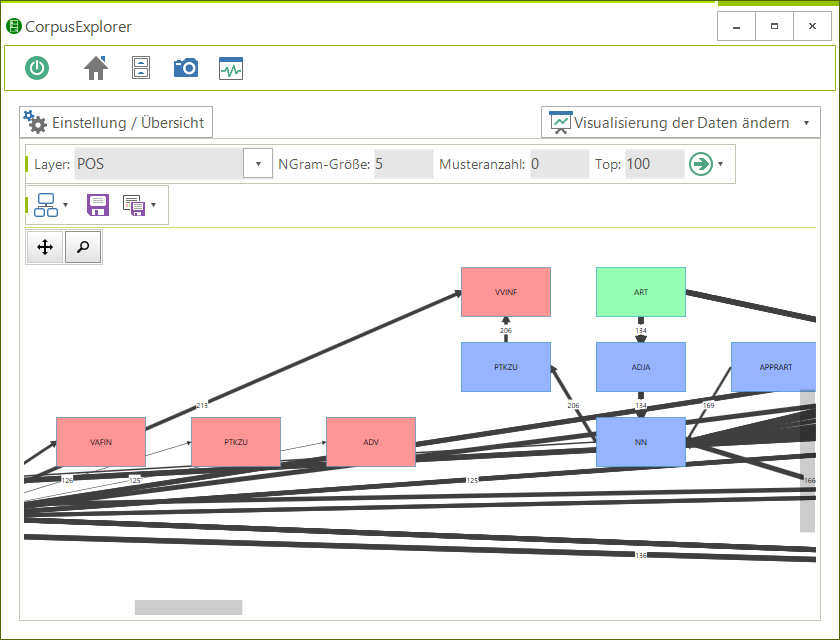
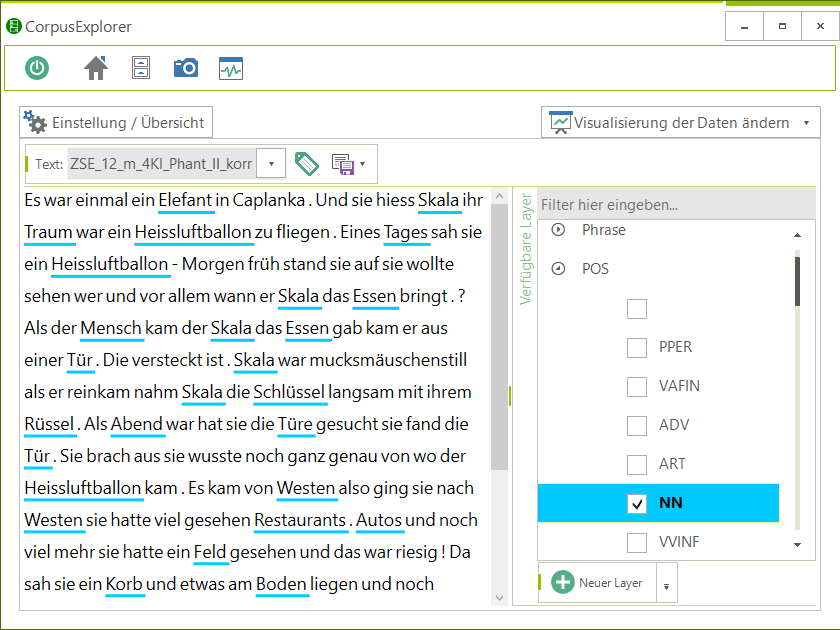
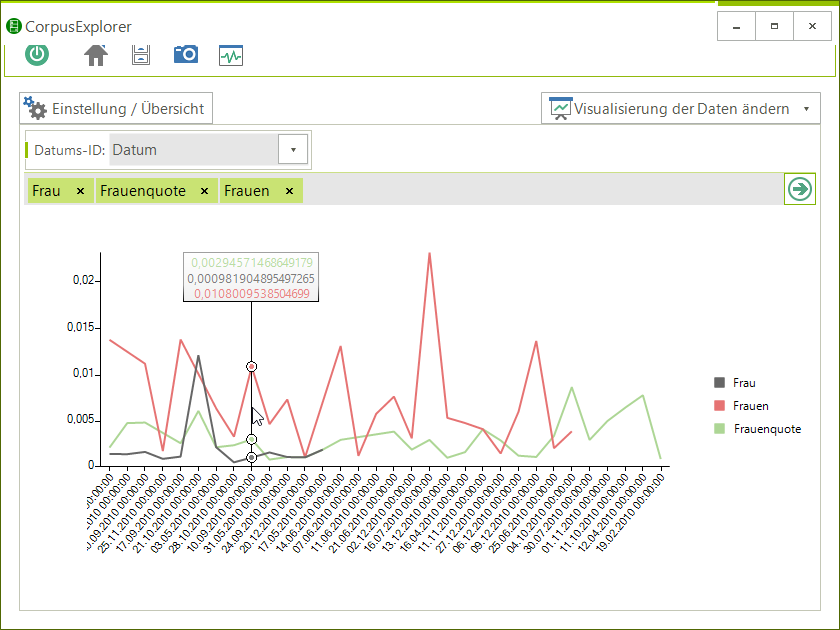
- 51 Analysemodule/Visualisierungen – z. B.: Frequenzanalyse, N-Gramme, Phrasen, Kookkurrenzen, KWIC, DIFF, Stilmetriken, Korpusverteilung.
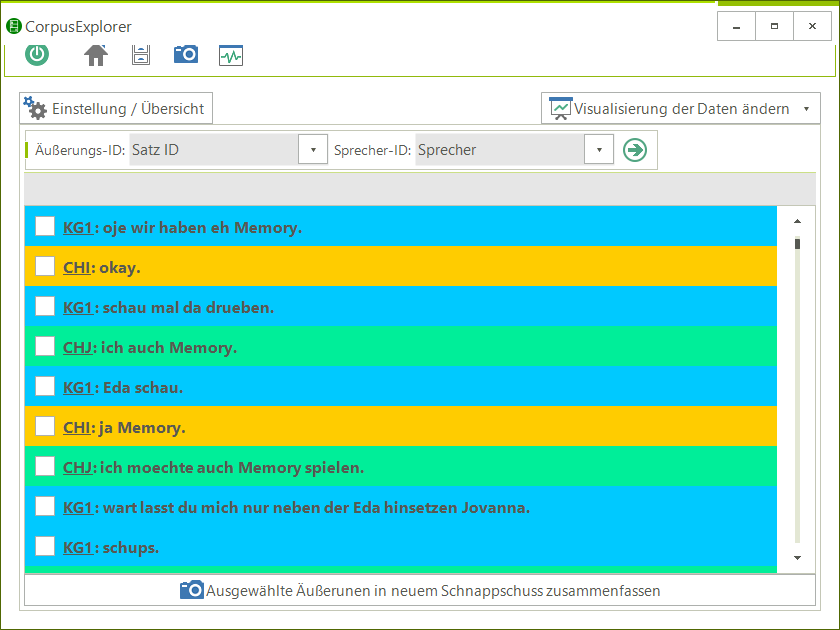
- Auswertungen/Visualisierungen werden vom Ausgangsmaterial/Korpora vollständig durch Schnappschüsse isoliert. Dadurch sind Ergebnisse reproduzierbar, selbst wenn sich das Korpusmaterial ändert.
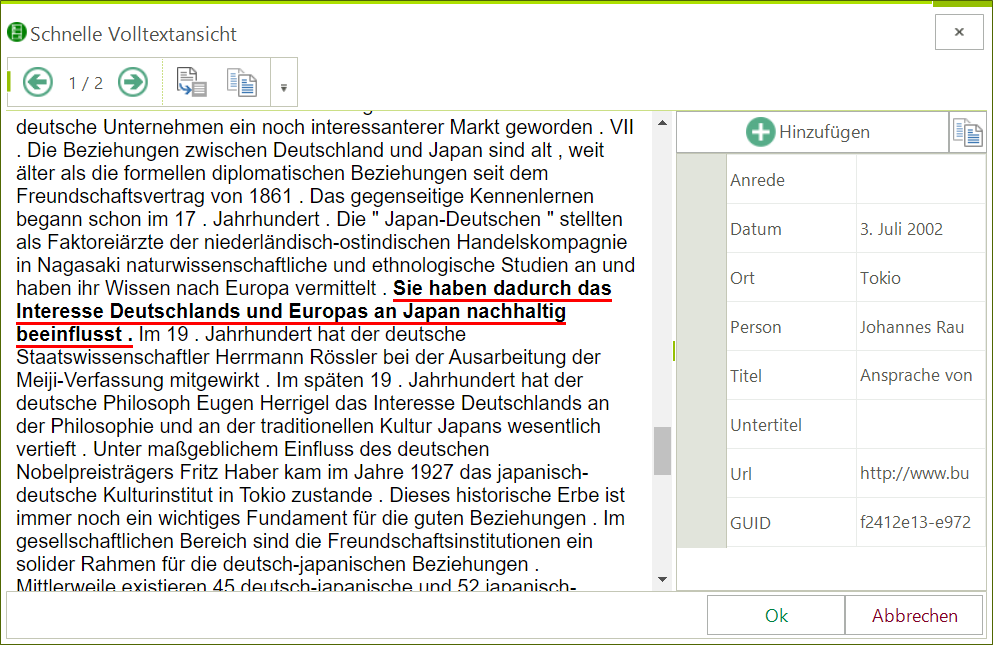
- Export der Analyseergebnisse in verschiedene offene Formate. Ebenso Export der Korpora in unterschiedliche breit genutzte Formate (wie WebLicht, CorpusWorkBench etc.)
- Per Shell/Konsole steuerbar (siehe https://github.com/notesjor/CorpusExplorer.Terminal.Console). Dies ist eine gute Anlaufstelle, wenn Sie den CorpusExplorer in eigene Skripte (R, python, etc.) integrieren möchten.
- Flexibles SDK (Software Development Kit) für alle .NET-Sprachen (https://de.wikipedia.org/wiki/Liste_von_.NET-Sprachen). Erlaubt eigene Erweiterungen für den CorpusExplorer zu entwickeln oder den CorpusExplorer in eigene Anwendungen zu integrieren.
- Korpora können direkt als REST WebService bereitgestellt werden.
- Überprüfbarer und nachvollziehbarer Toolchain durch Erzeugung eines Dummy-Korpus nach eigenen Vorgaben.
Publikationen / Zitation / Feedback / Nennungen
Diese Liste umfasst öffentliche Publikationen, die den CorpusExplorer nutzen und oder im Zusammenhang nennen. Nicht in der Liste enthalten: Publikationen an denen ich beteiligt bin (diese finden Sie hier) – sowie: Publikationen die mir nicht bekannt sind (wenn Sie eine Publikation entdecken oder selbst veröffentlicht haben, können Sie mir gerne eine Nachricht schreiben, dann nehme ich die Publikation auf).
- Tamara Bodden (2023): Kunst und Geld – Eine diskurslinguistische Untersuchung zur documenta 14. Band 59 der Reihe Sprache und Wissen (SuW). De Gruyter. https://doi.org/10.1515/9783111341668
Anmerkung: Promotionsschrift – Für die quantitativen Analysen wurde der CorpusExplorer verwendet. - Arno Strohmeyer, Christina Antenhofer, Christoph Kühberger (2023): Digital Humanities in den Geschichtswissenschaften. Anmerkung: utb Lehrbuch – CorpusExplorer wird als Tool vorgestellt.
- Elena Stroszeck und Jennifer Paetsch (eingereicht). Bilden Schulbücher die Nachhaltigkeitsziele der UN ab? – Ergebnisse einer Korpus- und Topic-Modeling-Analyse mit Schulbüchern. Poster eingereicht auf der Tagung der Gesellschaft für Empirische Bildungsforschung (GEBF), Potsdam.
- Elena Stroszeck und Jennifer Paetsch (2023): BNE-Wortschatz in der Grundschule : Ergebnisse einer Korpusanalyse mit Schulbüchern. In: AEPF-Tagung 2023
- Schuppener (2023), Religiöse Sprache in reichsbürgerlichen Texten. In: Studien zur deutschen Sprache und Literatur
- Lidia Becker, Julia Kuhn, Christina Ossenkop, Claudia Polzin-Haumann, und Elton Prifti, Hrsg. 2023. Digitale romanistische Sprachwissenschaft: Stand und Perspektiven. Romanistisches Kolloquium, Band 34. Tübingen: Narr Francke Attempto.
- Laura Hernández-Lorenzo (2022): Análisis de corpus poéticos con Litcon. In: Revista de Humanidades Digitales. Kontext: Der CorpusExplorer wird im Zusammenhang mit anderen DH-Tools kontextualisiert.
- Stevanović, S. (2022). Sprachliche Anforderungen des Pflegealltags und Bedarfe ausländischer Pflegekräfte. Erste Ergebnisse aus dem Forschungsprojekt Deutscherwerb im medizinischen Pflegekontext. In: mit.sprache.teil.haben – Publikation zur XVII. Internationalen Tagung der Deutschlehrerinnen und Deutschlehrer [IDT 2022]
- Handreichung: SNOMED : Guidelines for Translation of SNOMED CT. Kontext: SNOMED CT wird von der internationalen Standardisierungsorganisation SNOMED International herausgegeben. SNOMED steht für: Systematisierte Nomenklatur der Medizin. Die Guidelines v3 (Stand: 2022-06-20) listen den CorpusExplorer als ein geeignetes Werkzeug.
- Schmidt, C., (2022) KORPUSLINGUISTIK UND MÜNDLICHKEIT. Methodische und technische Herausforderungen bei der Erstellung eines fachspezifischen Korpus zur Verständigung über Literatur im Deutschunterrichtsdiskurs auf der Grundlage archivierter Transkripte Korpora Deutsch als Fremdsprache 2(1), 81-94. doi: https://doi.org/10.48694/kordaf-55
- Herausgeber: Michael Beißwenger, Lothar Lemnitzer und Carolin Müller-Spitzer (2022): Forschen in der Linguistik – Eine Methodeneinführung für das Germanistik-Studium. Kontext: Der CorpusExplorer wird zusammen mit anderen Tools vorgestellt.
- Teresa Gruber und Patricia De Crignis (2022): Tratar el cambio climático en metáforas: la construcción de rasgos semánticos emergentes en el discurso mediático. Kontext: Tagungsbeitrag ‚XXX Congreso Internacional de Lingüística y Filología Románicas‘
- Verena Ruth Hildegard Lyding (2022): Open demands for corpus analysis tools – a user-centered study. Anmerkung: Promotionsschrift – vergleicht verschiedene Tools und erwähnt den CorpusExplorer.
- Michael Bender und Katharina Jacob (2022): Germanistische Korpus-Hermeneutik – digitale Methodik und Mehrdeutigkeiten. Im Rahmen der Tagung „27. Deutscher Germanistentag 2022 – Thema: Mehrdeutigkeiten“. Kontext: Erwähnung als Tool für die Korpus-Hermeneutische-Analyse.
- Friedrich Markewitz, Britt-Marie Schuster, Nicole M. Wilk (2022): Guidelines – zur Annotation von Widerstandspraktiken in CATMA 5.0. Anmerkung: Die Publikation bezieht sich auf das hier verfügbare HtWik-Korpus. Ich habe das Projekt bei der Korpusaufbereitung beraten. Das fertige Korpus liegt in verschiedenen Formaten u. a. CorpusExplorer-kompatibel vor.
- Tina Bartelmeß, J. Godemann (2022). Qualitätskonstruktionen in unternehmerischer Ernährungskommunikation: Gesundheit im Spannungsfeld zwischen Individuum und Gesellschaft. In Cappel, V. & Kappler, K. E. (Hrsg.), Gesundheit – Konventionen – Digitalisierung. Eine politische Ökonomie der (digitalen) Transformationsprozesse von und um Gesundheit. Reihe Soziologie der Konventionen. Wiesbaden: Springer VS. Kontext: Nutzt den CorpusExplorer zur Analyse.
- Schuppener, G. (2022). Kriegsnarrative in reichsbürgerlichen Texten – Inszenierungen des Ausnahmezustandes – In: Studia Germanistica.
- Marti Stephan (2021): Professionalisierungsprozesse in der Lehrerinnenbildung – frameanalytisch gedeutet. Kontext: Der CorpusExplorer wird für eine Analyse verwendet.
- Auftragsstudie des Bundesministeriums der Justiz und für Verbraucherschutz
(BMJV) (2021): Wissenschaftliche Evaluation des Einflusses der gesetzesredaktionellen Arbeit auf die Verständlichkeit von Rechtsvorschriften. Kontext: Die Studie nutzt den CorpusExplorer als Analysewerkzeug. - Attila Mészáros (2021): Der sichtbare Diskurs. Interdisziplinäre Aspekte der Visualisierung von sprachlichen Daten im Kontext des universitären DaF-Unterrichts. In: Wortfolge. Szyk Słów. Kontext: Der CorpusExplorer wird als eines von mehreren Analysetools genutzt.
- Maximilian Paus (2021): Sprachanalyse terroristischer Gruppen in sozialen Netzwerken: Korpuslinguistische Betrachtungen im Kontext extremistischer Aktivitäten im Internet. In: Berliner Handreichungen zur Bibliotheks- und Informationswissenschaft
- Julia Krasselt, Matthias Fluor, Klaus Rothenhäusler, Philipp Dreesen (2021): A Workbench for Corpus Linguistic Discourse Analysis. In: 3rd Conference on Language, Data and Knowledge (LDK 2021)
- Marius Albers (2021): Orwell lässt grüßen! – Korpuslinguistische Untersuchungen zur Aktualität Orwells in Plenardebatten des Bundestags. In: Zeitschrift für Literaturwissenschaft und Linguistik 51, 87–107 (2021).
- Marcel Frey-Endres, Tobias Simon (2021): Digitale Werkzeuge zur textbasierten Annotation, Korpusanalyse und Netzwerkanalyse in den Geisteswissenschaften. In: Digital Philology | Working Papers in Digital Philology 02|2021. Darmstadt: TUPrints
- Georg Glasze, Annika Mattissek (2021): Handbuch Diskurs und Raum: Theorien und Methoden für die Humangeographie sowie die sozial- und kulturwissenschaftliche Raumforschung. transcript Verlag (Bielefeld). ISBN: 978-3839432181
- Robert Hesselbach (2020): „‹Nous sommes en guerre sanitaire› – A Corpus-based Approach of Official French, Italian and Spanish Social Media Discourse in the Light of the Coronavirus Crisis.“ – In: promptus – Würzburger Beiträge zur Romanistik 6: 45–66.
- Christina Schmidt (2020): Die Verständigung über Literatur im Deutschunterricht – Potenziale und Herausforderungen eines korpuslinguistischen Zugangs. In: Fachliche Bildung und digitale Transformation – Fachdidaktische Forschung und Diskurse (Regensburg), 151-155.
- Das Projekt „Sprache und Konfession im Radio“ (DFG-Projekt) nutzt den CorpusExplorer zur Analyse der Projekt-Korpora. [siehe]
- Tina Bartelmeß (2020): Unternehmerische Ernährungskommunikation und -verantwortung: Eine konstruktivistische Betrachtung im Kontext von Nachhaltigkeit.
Anmerkung: Promotionsschrift – nutzt den CorpusExplorer zur Korpusanalyse. Kontext: Ernährungswissenschaft. Forschungseinrichtung: Justus-Liebig-Universität Gießen
Feedback: Der CorpusExplorer hat mir vor allem durch die Visualisierungsmöglichkeiten geholfen und die Veranschaulichung meiner Ergebnisse gut unterstützt. Auch als Nicht-Linguistin und ohne Programmierkenntnisse lassen sich mit ihm einfache Analysen durchführen. Am besten gefallen hat mir, [das der Entwickler] stets ansprechbar für Fragen war uns sich die Zeit genommen hat, den CorpusExplorer in meinem Seminar vorzustellen. Aktuell ist übrigens gerade eine Masterarbeit von einer Teilnehmerin dieses Workshops im Entstehen. - Jan Gemeinholzer (2020): Radverkehr in der Regionalpresse. Eine lexikometrische Analyse des Radverkehrsdiskurses in Regionalzeitungen am Beispiel von Münster und Nürnberg. Anmerkung: Masterarbeit – nutzt den CorpusExplorer zur Korpusanalyse. Kontext: Institut für Geographie. Forschungseinrichtung: FAU Erlangen-Nürnberg
Feedback: Der CorpusExplorer ist super und ermöglicht Studierenden einen intuitiven Einstieg in die Thematik Linguistische Diskursanalyse / Korpusanalysen. Ich habe das Tool auch in meinem Geodatenbanken-Seminar den Studierenden präsentiert. - Nicole Tracy-Ventura, Magali Paquot (2020): The Routledge Handbook of Second Language Acquisition and Corpora. Routledge, 2020. ISBN: 978-1351137898
- Sylwia Dudkiewicz, Kathrin Hamann, Mara Hellmann, Josefin Klewenow, Leon Kostka, André Reichel, Jessica Schütt, Madlin Trümper und Clara Waberer (2020): Sphärenvermischung zwischen Wissenschaft und Politik? – Eine korpushermeneutische Pilotstudie zum Corona-Diskurs im März und April 2020 anhand der Protagonisten Christian Drosten und Jens Spahn. Kontext: Studentisches Projektarbeit.
- Julia Rothenhäusler (2019): Kriesenkommunikation bei Großprojekten – Eine diskurslinguistische Analyse am Beispiel von Stuttgart 21. Anmerkung: Masterarbeit– nutzt den CorpusExplorer zur Korpusanalyse. Kontext: Werbung Interkulturell. Forschungseinrichtung: Katholische Universität Eichstätt-Ingolstadt
- Dominik Steiner und Gëzim Zeneli (2019) – Texploration: Automatische Analyse von grossen Textsammlungen. Kontext: Bachelorarbeit Informatik – Dominik Steiner und Gëzim Zeneli entwickelten gemeinsam ein eigenes Toolset und vergleichen es mit anderen Tools u. a. CorpusExplorer.
- Laurence Anthony, Stephanie Evert (2019) – Embracing the Concept of Data Interoperability in Corpus Tools Development. Kontext: Erwähnung und Einschätzung von CorpusExplorer und ähnlichen Programmen.
- Alexander Geyken, Matthias Boenig, Susanne Haaf, Bryan Jurish, Christian Thomas und Frank Wiegand (2018): „Das Deutsche Textarchiv als Forschungsplattform für historische Daten in CLARIN“ – In: Digitale Infrastrukturen für die germanistische Forschung. – Anmerkung: Erwähnung des CorpusExplorer als Tool der Nachnutzung des DTA.
- Marc Kupietz, Nils Diewald, Peter Fankhauser (2018) How to Get the Computation Near the Data: Improving Data Accessibility to, and Reusability of Analysis Functions in Corpus Query Platforms. Anmerkung: Fachartikel – CorpusExplorer wird in einer Reihe anderer Tools genannt.
- Adrien Barbaresi (2018) A corpus of German political speeches from the 21st century. Kontext: Fachartikel – CorpusExplorer wird in einer Reihe anderer Tools genannt.
- Henning Lobin, Roman Schneider und Andreas Witt (Hrsg.) – Digitale Infrastrukturen für die germanistische Forschung. Kontext: CorpusExplorer wird als ein Infrastruktur-Tool kurz vorgestellt, dass eine Nutzung der DTA-Daten ermöglicht.
- Attila Mészáros (2018) – Perspektiven einer akteursorientierten Diskursanalyse
der Flüchtlingsdebatte in der Slowakei. Kontext: Einordnung des CorpusExplorers im Kontext zu anderen Programmen. - Stefan Jänicke, Judith Blumenstein, Michaela Rücker, Dirk Zeckzer, Gerik Scheuermann (2017) – TagPies: Comparative Visualization of Textual Data. Kontext: Der CorpusExplorer wird als eines von mehreren Tools zitiert, die TagPies implementieren.
Unterstützer*innen:
Folgend Unterstützer*innen gilt mein vollster Dank. Dies gilt einerseits für Firmen, die das Projekt CorpusExplorer langjährig (z. B. mit kostenlosen oder vergünstigen Lizenzen) unterstützt haben, ebenso wie den tollen Kolleg*innen, die OpenSource-Software publizieren auf deren Rücken ich den CorpusExplorer aufbauen konnte – DANKE!
- PostSharp – ist eine kommerzielle Komponente von SharpCrafters, die es erlaubt, aspektorientiert zu programmieren. Aspekte ergänzen das Konzept der objektorientierten Programmierung, indem typische Routineaufgaben wie z. B. das Protokollieren von Fehlern oder das Sammeln von Performance-Daten in Aspekte ausgelagert werden können. Vielen Dank für die langjährige Unterstützung und die Bereitstellung einer kostenfreien akademischen Lizenz.
- TreeTagger – Vielen Dank an Helmut Schmid für die Genehmigung, den TreeTagger mit dem CorpusExplorer gebündelt ausliefern zu dürfen.
Häufige Fragen der Nutzer*innen
Wie zitiert man Software? Wie zitiert man den CorpusExplorer?
Software gehört zu den Hilfsmitteln und muss daher genauso zitiert werden wie Fachliteratur. Einige Literaturverwaltungsprogramme, wie Citavi oder EndNote, bieten bereits Vorlagen für die Zitation von Software.
Hier ein Vorschlag, wie Sie den CorpusExplorer zitieren können:
Rüdiger, Jan Oliver (2018): CorpusExplorer. Version 2.0. Universität Kassel – Universität Siegen. Online verfügbar unter http://corpusexplorer.de
Hier der Vorschlag als BibTeX:
@misc{Ruediger.2018, author = {R{„u}diger, Jan Oliver}, year = {2018}, title = {CorpusExplorer}, url = {url{http://corpusexplorer.de}}, price = {Kostenfrei / OpenSource},address = {Universit{„a}t Kassel – Universit{„a}t Siegen},howpublished = {Download}}
[Weitere Informationen zum Zitieren – inkl. Zitation von Dokumenten innerhalb von Korpora]
Wenn der CorpusExplorer ein Promotionsprojekt war, wird er trotz Abschluss der Promotion noch weiterentwickelt? – Ja, auf jeden Fall. Leider ist es oft so, dass wissenschaftliche Software nach Projektabschluss (z. B. auch Finanzierungsphase) eingestellt und vergessen wird. Man findet in den öffentlichen Repositorien viele Beispiele dafür. Der CorpusExplorer wurde von Anfang an so geplant, dass er weitergepflegt und weiterentwickelt werden kann. Das lohnt sich auch, denn der CorpusExplorer hat mittlerweile eine solide und wachsende Nutzerbasis. Ich selbst verwende den CorpusExplorer auch in fast allen aktuellen Forschungsprojekten. Eine aktive Nutzung ist wichtig, denn nur so sieht man, was eine Software können muss/sollte – es entstehen Ideen für die Weiterentwicklung. Früher (während der Promotion) gab es monatliche Updates. Mittlerweile habe ich den Update-Plan umgestaltet. Es gibt ca. ein Update pro Quartal – dieses ist dann aber größer. Kleiner Qualitätsupdates oder wenn es dringende Wünsche durch Nutzer*innen gibt, werden auch manchmal außer der Reihe veröffentlicht (so schnell wie möglich).
Ich habe gelesen, der CorpusExplorer wird als OpenSource-Projekt entwickelt. Wo finde ich den Quellcode? – Das öffentliche Repository (wird nach jedem Update aktualisiert) finden Sie unter:
https://github.com/notesjor/corpusexplorer2.0
Was sind die Hauptunterschiede zwischen 2.0 und 1.9? – Im Grunde handelt es sich um zwei komplett unterschiedliche Programme. Die Version 2.0 wurde von Grund auf neu entwickelt. Die wesentlichen Unterschiede der Version 2.0 gegenüber 1.9 sind:
- Über 50 verschiedene Analysemodule (Version 1.9 verfügt nur über 10)
- Deutlich höhere Performance.
- Eigene In-Memory Datenbank speziell für linguistische Daten.
- Austauschbares Daten-Backend für unbegrenzt große Korpora. Nutzen Sie MySQL, MS SQL-Server oder ElasticSearch um große Korpora zu speichern.
- Offene Entwicklerplattform die es erlaubt, eigene Erweiterungen, Tagger, Visualisierungen und Auswertungen zu programmieren.
- Projekte und Schnappschüssen erlauben das einfache organisieren und bei der Formulierung von Forschungsfragen.
Ist der CorpusExplorer kommerziell? Welche Kosten fallen an? – Der CorpusExplorer ist OpenSource, d. h. er ist NICHT kommerziell – es fallen keinerlei Kosten an, auch keine versteckten Kosten.
Was sind die Mindestvoraussetzungen (Hardware) für den CorpusExplorer? – Der CorpusExplorer läuft auf allen PCs ab Windows 10. Die Standardinstallation benötigt ca. 700 MB freien Festplattenplatz (davon 50 MB für den CorpusExplorer – der Rest: Drittanbieter z. B. TreeTagger). Es werden min. 8 GB RAM (Arbeitsspeicher) empfohlen. Außerdem empfiehlt sich der Einsatz einer aktuellen CPU mit mindestens 4 Kernen und 64-Bit.
Gibt es eine Linux, MAC – Version? – Wie Sie den CorpusExplorer unter Linux / MacOS installieren, erfahren Sie hier. Wenn Sie den CorpusExplorer nativ auf diesen Plattformen betreiben, müssen Sie aktuell jedoch mit einigen Einschränkungen (z. B. nicht alle Tagger funktionieren) und einer geringeren Performance rechnen. Daher wird die Virtualisierung z. B. mittels VirtualBox empfohlen.
Ist geplant den CorpusExplorer zu kommerzialisieren – also Geld für die Nutzung zu verlangen? – Wie finanziert man die Weiterentwicklung? – Der CorpusExplorer steht unter der GNU Affero General Public License v3.0 – die GNU-Organisation, die hinter dieser Lizenz steht, definiert Freiheit wie folgt: „Freie Software ist Software, die die Freiheit und Gemeinschaft der Nutzer respektiert. Ganz allgemein bedeutet das, dass Nutzer die Freiheit haben, Software auszuführen, zu kopieren, zu verbreiten, zu untersuchen, zu ändern und zu verbessern. Freie Software ist daher eine Frage der Freiheit, nicht des Preises. Um das Konzept zu verstehen, sollte man an frei wie in Redefreiheit denken, nicht wie in Freibier.“ [GNU 2015-08-04] – Für die Nutzung werden also auch in Zukunft keine Lizenzgebühren fällig. Die Entwicklung finanziert sich zum einen durch Sponsoring – sowie durch Projektaufträge. Wenn Sie eine spezielle Anpassung wünschen, entwickele ich diese gerne für Sie – Der Stundensatz richtet sich dabei u.a. danach, ob Sie bereit sind, diese Anpassung mit anderen Nutzer*innen des CorpusExplorer zu teilen oder nicht.
Kann ich die Version 2.0 und die Version 1.9 parallel installieren? – Ja, dies ist ohne Probleme möglich. Korpora können zwischen den Versionen ausgetauscht werden. Auch in Zukunft werden alle CE-Versionen untereinander kompatibel sein.