Vielleicht irre ich mich – aber ich glaube, in 2021 werden einige große Dinge mit dem CorpusExplorer passieren. Zumindest haben sich viele Funktionen angesammelt, die darauf warten veröffentlicht zu werden. Also starten wir mir den Änderungen für Q1 2021:
- DPXC-Editor „Der DPXC-Editor ist tot, lang lebe der DPXC-Editor“.
Der DPXC-Editor ist ein Add-on, dass das Sammeln von Korpora per Copy&Paste erlaubt. Was als kleiner Nutzer*innen-Wunsch begann (bei dem ich gedacht hätte: nette Nischenfunktion) wird mittlerweile von einem halben Dutzend (mir bekannten) Projekten aktiv eingesetzt (Projektgrößen: Masterarbeiten bis hin zu DFG-Projekten). Daher habe ich etwas Zeit investiert um den Editor (A) besser zu machen und (B) ihn stärker in den CorpusExplorer zu integrieren.- Integration:
Der Editor wird jetzt direkt mit dem CorpusExplorer installiert (er muss nicht mehr als Add-on nachinstalliert werden).
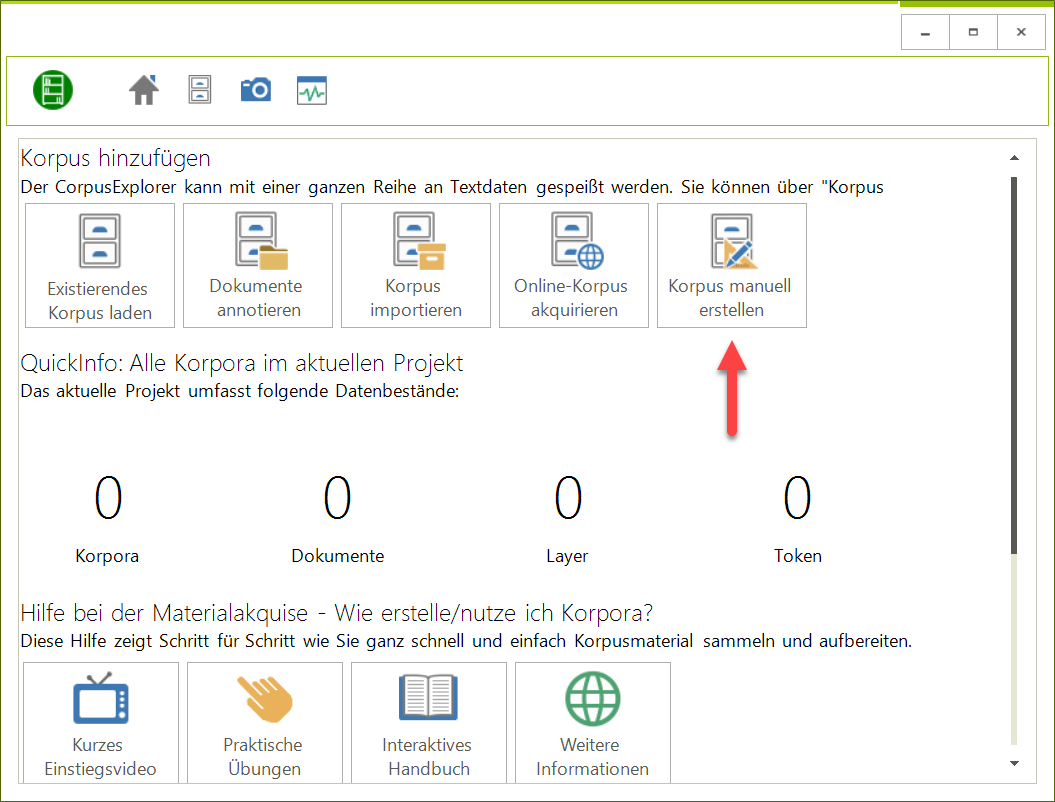
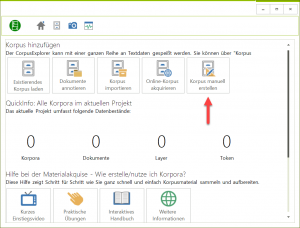 Der Editor kann jetzt unter „Korpus Übersicht“ über die Option „Korpus manuell erstellen“ aufgerufen werden.
Der Editor kann jetzt unter „Korpus Übersicht“ über die Option „Korpus manuell erstellen“ aufgerufen werden.
Hinweis: Die Möglichkeit den DPXC-Editor als „Add-on“ zu installieren (siehe CorpusExplorer – Startseite) bleibt weiterhin bestehen. Wird der DPXC-Editor als Add-on installiert so wird ein Link zum direkten Aufruf auf dem Desktop platziert. - Verbesserungen:
 Der Editor hat eine ganze Reihe von Verbesserungen:
Der Editor hat eine ganze Reihe von Verbesserungen:
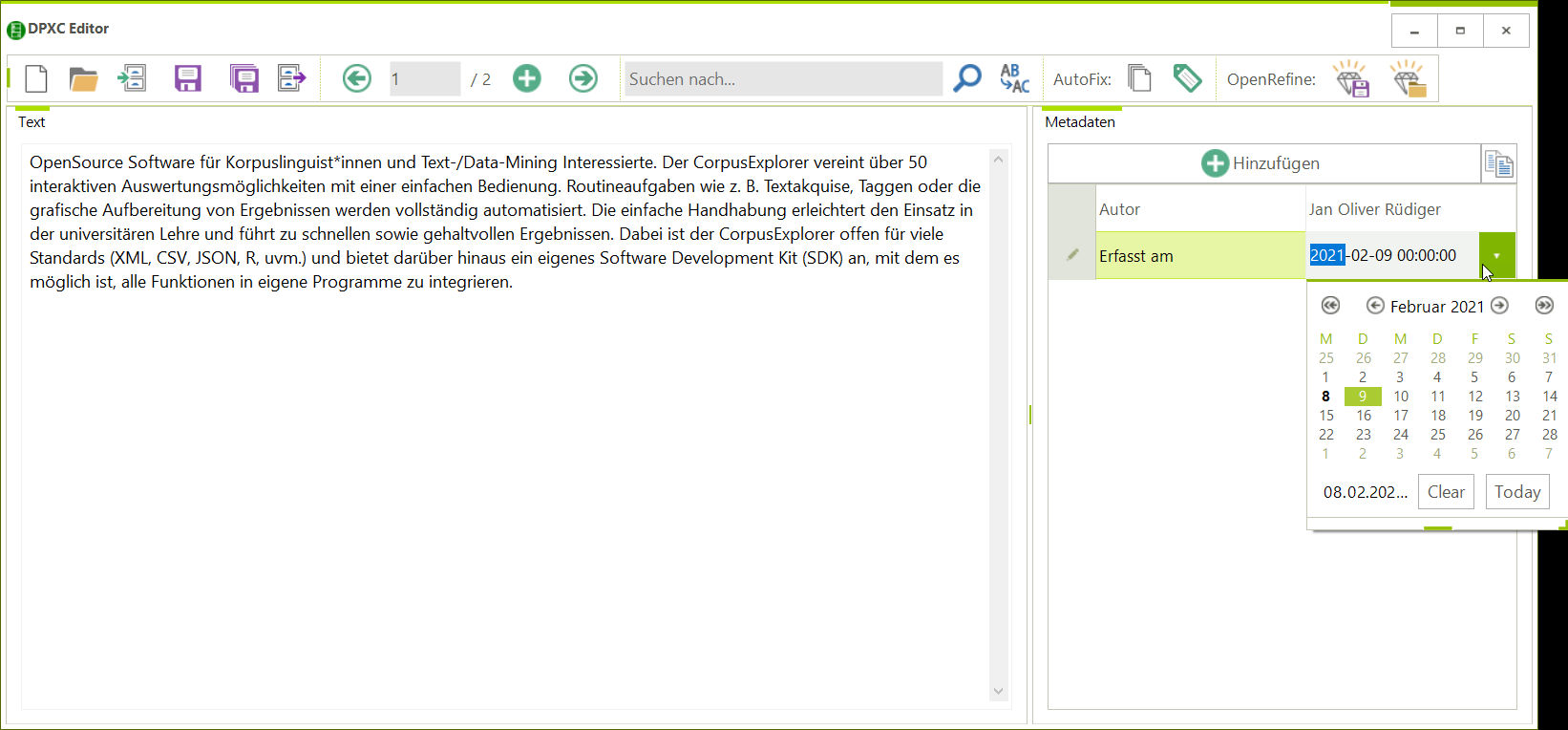
- Suchen & Ersetzen – für Volltexte und Metadaten
- AutoFix für Texte und Metadaten – z. B. das Entfernen von HTML-Fragmenten oder überzähligen Leerzeichen.
- Import / Export für OpenRefine. Bei OpenRefine handelt es sich um eine freie, sichere und hoch Effiziente (reproduzierbar, schnell, raffiniert etc.) Lösung, um Metadaten zu bereinigen. Das Programm steht kostenfrei unter: https://openrefine.org/ zum Download zur Verfügung.
- Hinweis 1: Was ich sehr oft als Frage in Trainings mit OpenRefine-Bezug zu hören bekomme: „Sind meine Daten in OpenRefine sicher? – OpenRefine ist doch von Google – und ich soll da Daten in den Browser hochladen…“ – Antwort: Ja, die Daten sind sicher. OpenRefine startet auf ihrem PC, auf dem Sie OpenRefine installieren, einen lokalen Webserver. Google hat die Lösung gewählt, um OpenRefine für alle Betriebssystem anbieten zu können (Windows, MacOS, Linux). Sie laden zwar die Daten mit Hilfe ihres Webbrowsers – aber: Die Daten verlassen ihren PC nicht.
- Hinweis 2: Ein Student (Sinan Cosgun – Universität Siegen) hat in einem meiner Seminare (Uni Siegen) ein deutschsprachiges Tutorial zu OpenRefine erstellt – wer sich einarbeiten möchte: https://mooc.diskurslinguistik.net/course/view.php?id=8
- Integration:
- WordBag v2
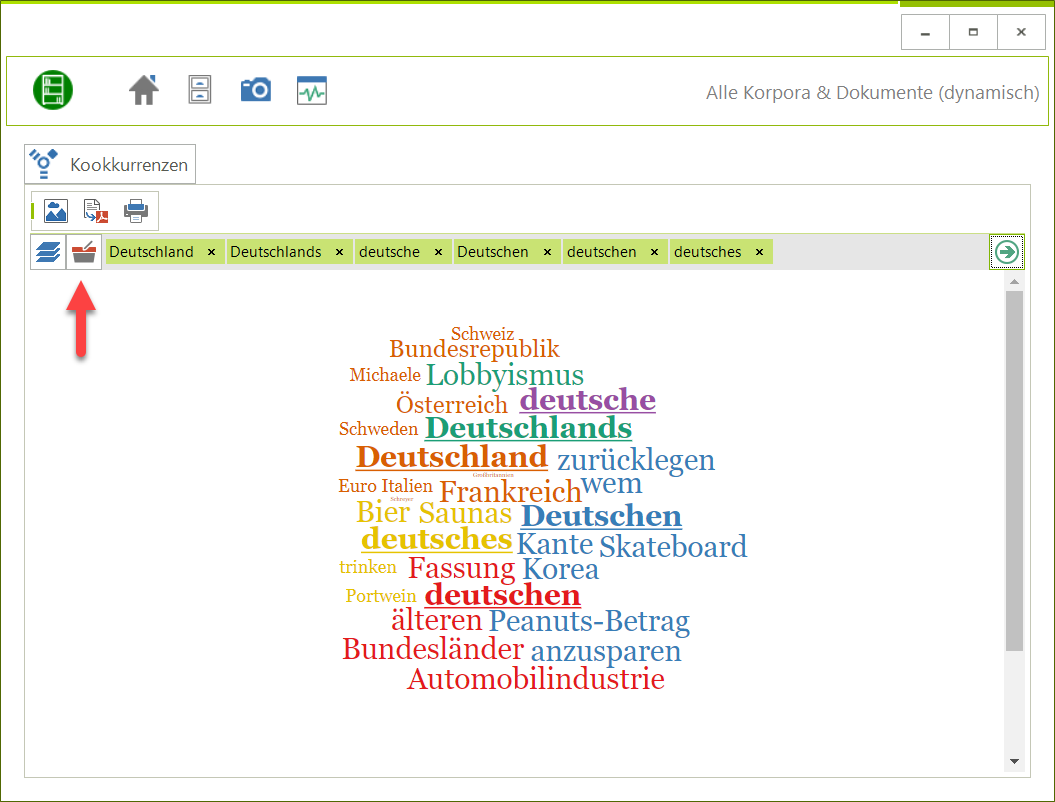
Die neue erweiterte WordBag-Funktion erlaubt es schneller mehrere Begriffe für Suchabfragen zu ermitteln. Mussten früher Begriffe manuell eingegeben werden (unterstützt durch ein interaktives Wörterbuch) oder mit Hilfe zuvor definierter Listen. Kann jetzt eine Abfrageliste über das WordBag-Symbol erstellt werden – Beispiel:
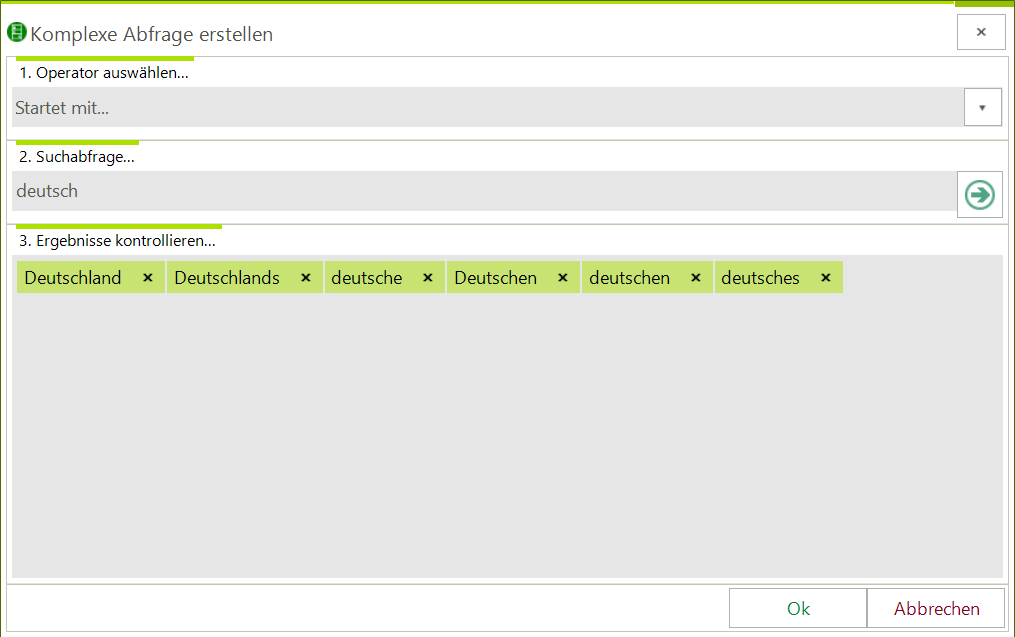
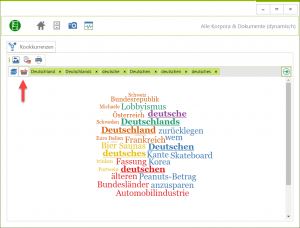 Danach erscheint die folgende Abfragemaske:
Danach erscheint die folgende Abfragemaske:
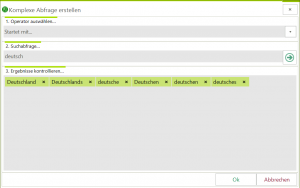 Über die Suchoperatoren können gleich alle passenden Begriffe gesucht werden. Abwahl durch Klick auf das ‚X‘ des jeweiligen Begriffs.
Über die Suchoperatoren können gleich alle passenden Begriffe gesucht werden. Abwahl durch Klick auf das ‚X‘ des jeweiligen Begriffs. - VOC-D und MTLD
Unter „Stilometrie“ können jetzt VOC-D und MTLD berechnet werden. Bitte beachten: Beide Verfahren nutzen ein Daten-Sampling. Dadurch kann die Berechnung längere Zeit (5-15 Minuten) in Anspruch nehmen. - Dispersion
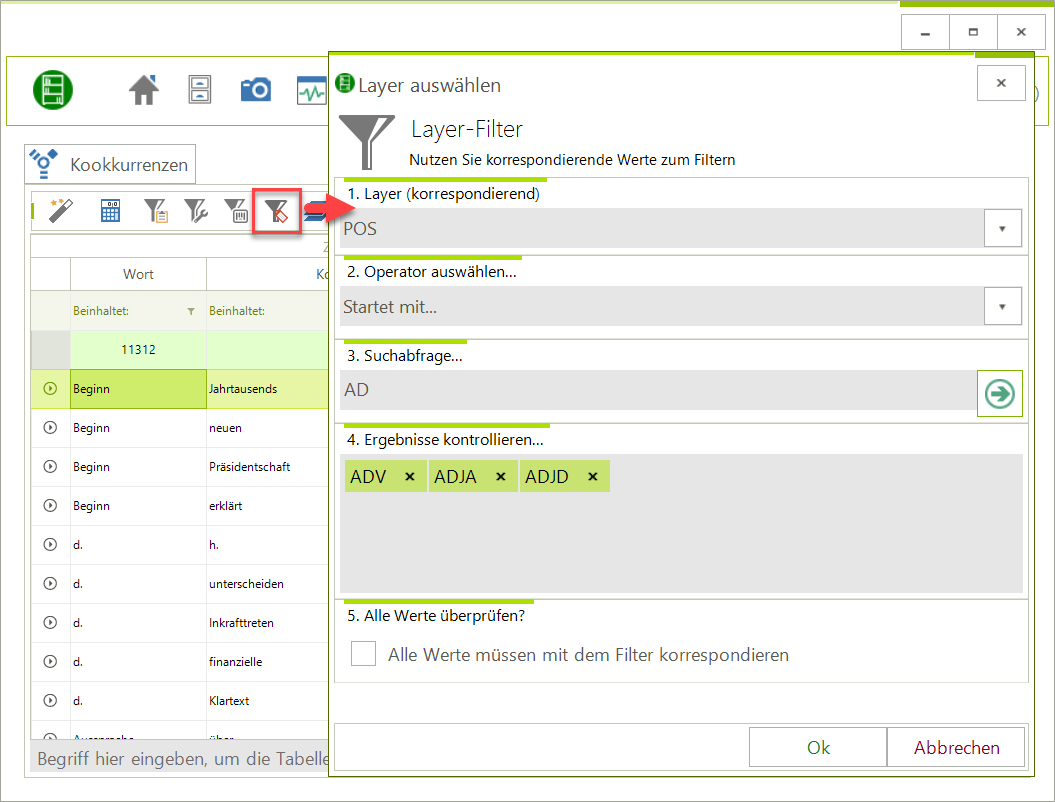
Über „Frequenzanalyse“ > „Dispersion“ kann jetzt die X-Term-Frequenz und die Inverse-X-Term-Frequenz berechnet werden. Als „X“ kann jede beliebe Metaangabe verwendet werden. So ist die Berechnung z. B. von Dokument-Term-Frequenz (durch Auswahl von GUID) oder die Berechnung von Inverse-Autoren-Term-Frequenz möglich. - Filter: Korrespondierende Layerwerte
Ursprünglich (nur für POS-Werte) wurde diese Funktion auf Nutzer*innen-Wunsch für die Kookkurrenz-Analyse umgesetzt. Davon ausgehend wurde der Layer-Filter entwickelt (alle Layer können ausgewählt werden – z. B. POS oder Lemma). Dies ist ein Post-Analyse-Filter d. h. der Filter wird auf die Analyseergebnisse angewendet.
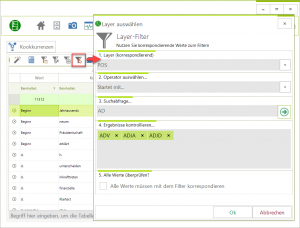 Der Filter steht für N-Gramme, Kookkurrenzen, Links-/Rechts-Frequenz, Dispersion und Keywords zur Verfügung.
Der Filter steht für N-Gramme, Kookkurrenzen, Links-/Rechts-Frequenz, Dispersion und Keywords zur Verfügung. - ImageBuilder v1
Der ImageBuilder ist ein Konsolen-Programm, dass ein komplettes Installations-Image des CorpusExplorers erzeugt.
Wofür ist das Tool nützlich? – Wenn Sie z. B.- Den CorpusExplorer auf einem Cluster, Linux oder MacOS (als Konsolen-Version) nutzen möchten, dann können Sie damit ein Image erstellen.
- Falls sich der CorpusExplorer unter Windows nicht installieren lässt (z. B. aufgrund von restriktiven Richtlinien, Firewall oder Anti-Viren-Programmen).
- Wenn Sie den CorpusExplorer auf einem USB-Stick nutzen möchten.
Was ist für die kommenden Versionen des ImageBuilders geplant:
-
- Download von Korpora
- Betriebssystemoptimierte Builds – aktuell müssten Sie (um automatisch zu annotieren) die Tagger-Dateien durch passende Betriebssystem-Builds ersetzen. Dies soll in Zukunft automatisiert passieren.
- Neue Import/Export-Formate:
- CATMA 6 (Import/Export)
Hinweis: CATMA ist leider vom Format und den Möglichkeiten etwas ’speziell‘ – sprich: Sehr oft ist es so, dass man Daten zwar in CATMA einlesen kann, die Daten sich danach nicht mehr adäquat exportieren lassen. Ich empfehle folgendes Vorgehen:- Laden Sie ihr Rohkorpus in den CorpusExplorer (ggf. auch über den DPXC-Editor) – z. B. über „Dokumente annotieren“
- Exportieren Sie dann das Korpus (Schnappschuss Übersicht > Exportieren) nach CATMA
- Laden Sie den CATMA-Export in CATMA.
- Wenn Sie in CATMA weitere Layer oder Werte hinzufügen, dann orientieren Sie sich bitte an der Struktur, die der CorpusExplorer vorgibt.
- Speichern Sie die CATMA-Daten lokal ab und laden Sie die Daten erneut über „Korpus importieren“ in den CorpusExplorer.
- Tipp: Wenn Sie eigene Layer oder Layerwerte in CATMA anlegen, dann sollten Sie diese in einem kleinen Pilot testen (nur wenige Sätze) und die Daten in den CorpusExplorer re-importieren. So vermeiden Sie böse Überraschungen.
- IDS I5- und KorAP-XML
Die I5- und KorAP-Daten stehen primär nur IDS-Mitarbeiter*innen zur Verfügung. Es gibt aber auch einige freie Korpora, die über folgende Seite bezogen werden können: https://www1.ids-mannheim.de/kl/projekte/korpora/verfuegbarkeit.html- IDS I5-XML
IDS I5-XML ist das Standardformat für Volltexte + Metadaten des „Leibniz-Institut für Deutsche Sprache“. Der CorpusExplorer unterstützt I5 bereits seit längerem. Neu ist der verbesserte Metadaten-Support. - KorAP-XML
KorAP-XML ist das Standardformat für das die Korpusanalyseplattform des „Leibniz-Institut für Deutsche Sprache“.
- IDS I5-XML
- CATMA 6 (Import/Export)