CorpusExplorer – Ein Programm, das aus meiner Magisterarbeit erwachsen ist und im aktuellen Promotionsprojekt weiterentwickelt wird. Der CorpusExplorer vereint eine Vielzahl bekannter computer-/korpuslinguistischer Tools. Er vereinfacht das Arbeiten mit großen Textmengen und erlaubt es, Korpora als Wissensquelle neu zu entdecken … Das Ziel: Sprache und Technik ein Stück näher zusammenzubringen.
CorpusExplorer (Update Q4 2023)
Kurz vor Jahresende gibt es noch ein kleines Update für den CorpusExplorer. Folgende neue und geänderte Funktionen gibt es: Wichtig: Die Systemvoraussetzung wurde auf .NET 4.6.2 angehoben. Es ist absehbar, dass Microsoft den Support auch hierfür bald einstellt und...
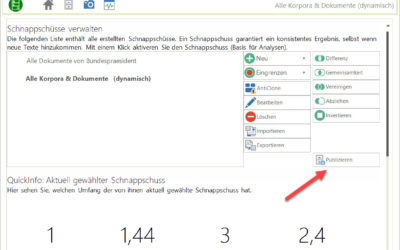
CorpusExplorer (Update Q3 2023)
Dieses Update bringt größere Neuerungen mit sich und steht ganz im Zeichen "Wie kommen Daten in den CorpusExplorer und aus dem CorpusExplorer heraus?". Folgende Neuerungen gibt es: Der Publishing-Wizzard Diese Funktion ist in der "Schnappschuss Übersicht" zu finden....
CorpusExplorer (Update Q2 2023)
Eigentlich gibt es im Mai immer ein neues, größeres Update für den CorpusExplorer. Diesmal werde ich 'größere' Änderungen auf Q3/Q4 verschieben müssen. Das Update umfasst neben verschiedenen Fehlerkorrekturen nur ein paar geringfügige Neuerungen: Der Befehl...
CorpusExplorer (Update Q1 2023) – SP1
Kleines Service-Pack für das Q1-Update. Folgende Neurungen und Verbesserungen wurden eingepflegt: Neues Format für CMS-Exporte. Neuer Query-Editor für Tabellenabfragen. CEC Cluster kann jetzt im Modus Loop exportieren. Fehler im WebCrawler wurden behoben....
CorpusExplorer (Update Q1 2023)
Für das Jahr 2023 wünsche ich Euch alles Gute. Ein kleines Update gibt es ganz zum Jahresanfang. Es behebt primär einige kleine Fehler und bietet ein paar Neuerungen: Neue Funktionen: Neuer Export für die verbesserte Version der CWB (CorpusWorkBench). Diese wurde in...
CorpusExplorer (Update Q3/Q4 2022)
Mit etwas Verspätung erscheint das Q3-Release des CorpusExplorers. Evtl. wird es noch ein weiteres Update in diesem Jahr geben. Folgendes ist neu oder wurde geändert: Neuerung: Mit MDA (Multidimensional Document Analyzer) gibt es jetzt eine relativ einfache wie auch...
CorpusExplorer (Update Q2 2022)
Eigentlich hatte ich das Update für das Q2 2022 erst für Mai 2022 geplant. Es wird auch ein Mai-Update geben, denn traditionell gibt es im Q2/Mai eines jeden Jahres das größte Update. Trotzdem haben sich jetzt einige Aktualisierungen und Korrekturen angesammelt -...
CorpusExplorer (Update Q1 2022) – SP1
Der CorpusExplorer unterstützt ab jetzt "Sketch Engine VERT" sowohl für den Im- als auch den Export.
CorpusExplorer (Update Q1 2022)
Alle Nutzer*innen des CorpusExplorers wünsche ich ein frohes, gesundes und erfolgreiches Jahr 2022. Der CorpusExplorer startet dieses Jahr früh mit dem ersten Quartals-Release Q1-2022. Es gibt einige spannende Neuerungen und viele weitere sind für 2022 bereits in...
CorpusExplorer (Update Q4 2021)
Das 2021Q4-Update für den CorpusExplorer bringt folgende Neuerungen/Verbesserungen: LDA-Topic Modeling Der CorpusExplorer verfügt jetzt über die Möglichkeit ein Topic-Modell zu erzeugen. Grundlage ist hierfür LightLDA (https://github.com/microsoft/LightLDA) eine...